TA的每日心情 | 无聊
3 天前 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
1.Selenium简单介绍
1.简介
Selenium是一个用于测试网站的自动化测试工具,支持各种主流界面浏览器。
简而言之,Selenium是一个用来做网站自动化测试的库,它的定位是做自动化测试的。我们也可以利用它来做爬虫,获取一些网页信息,并且这种爬虫是模拟真实浏览器操作的,实用性更强。
Selenium是市面上唯一一款可以与付费产品竞争的自动化测试工具。
2.安装
要使用Selenium首先要在python中安装相关的库:
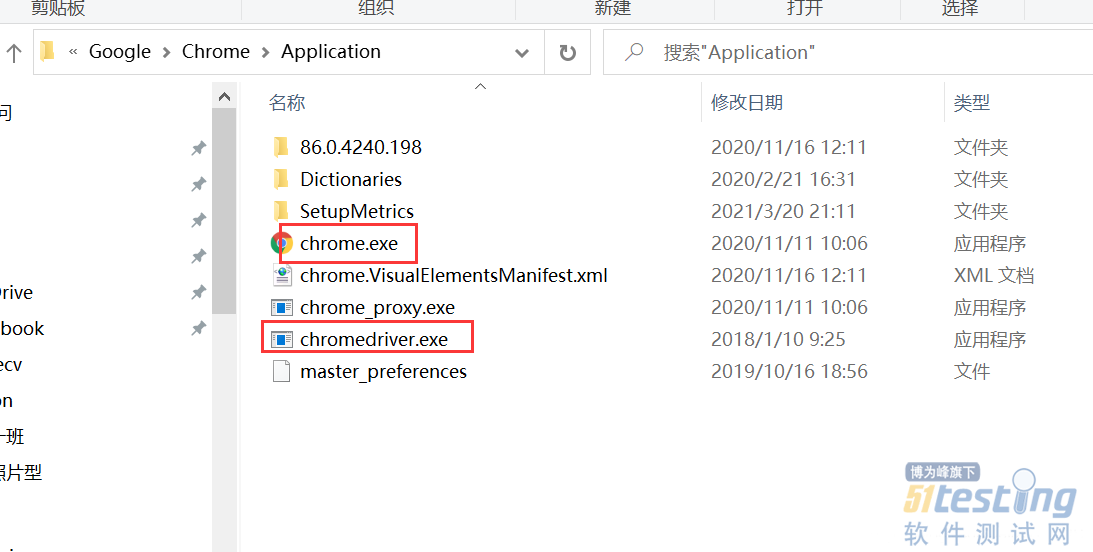
安装相应浏览器的webdricer驱动文件,这里提供chrome的链接,其它浏览器网上搜一搜就有。选择合适的版本,我选择的是2.23。
下载解压后得到exe文件,将这个文件拷贝到chrom的安装文件夹下:
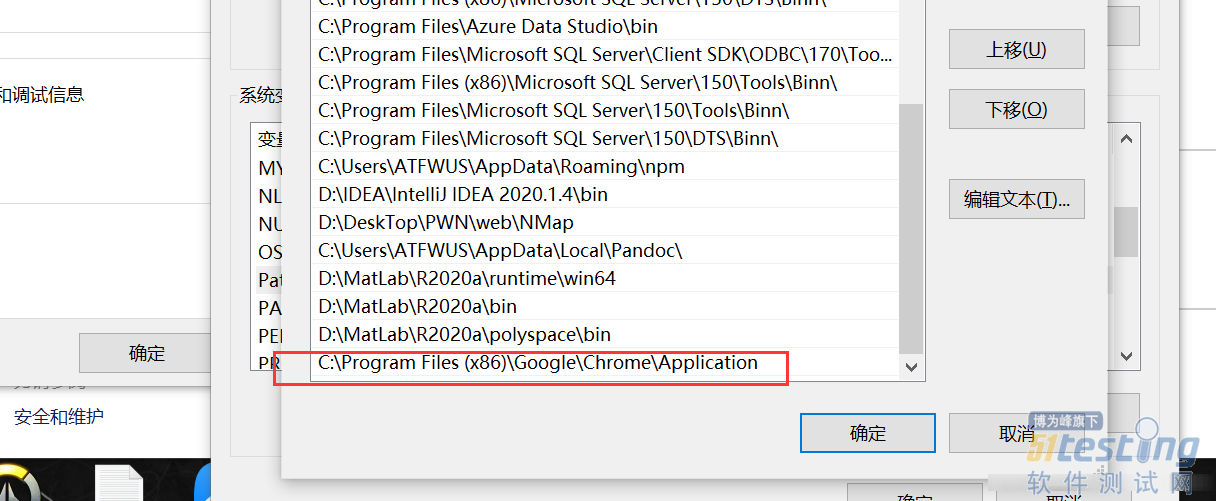
一般是C:\Program Files (x86)\Google\Chrome\Application,或者是C:\Program Files\Google\Chrome\Application。
然后将该路径配置到环境变量中:
最后到写段代码测试一下:
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
|
如果看到开启了一个浏览器窗口就是成功了,否则下面会有相应的报错信息,需要检查前面的步骤。
3.简单使用介绍
1)元素定位方式:
基本上前几种方式就能够获取到需要的元素,需要自己辨别结果是否唯一来选择相应的选择器。
通过drive对象调用此方法,返回的是标签对象,或者是标签对象的列表,可以通过.text获取该标签下的文字,可以通过get_attribute()获取标签的其它属性值。
分享快速定位元素的小妙招:看所需信息所在的标签的id,class,name的名称是否与标签下信息的语义有关,一般有关的都代表是唯一的。(从开发者的角度去思考)若无法通过当前标签唯一定位,则考虑父级标签,依此类推,总是能找到定位的方法的。
2)鼠标事件(模拟鼠标操作)
通过标签对象调用即可。
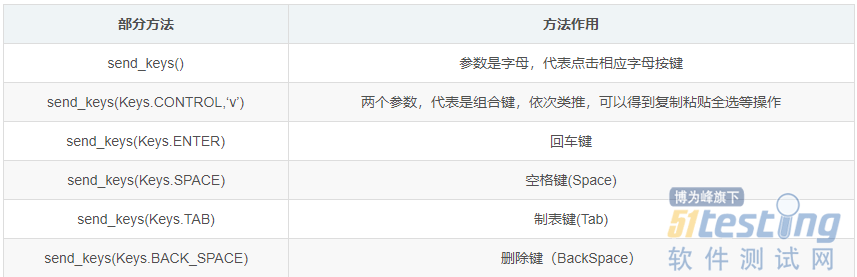
3)键盘事件(模拟键盘操作)
4)其他操作
其他操作包括控制浏览器的操作,获取断言信息,表单切换,多窗口切换,警告框处理,下拉框处理,文件上传操作,cookie操作,调用js代码,截图,关闭浏览器等操作,因为在这里用的不多,就没有一一罗列,自行去官网学习。
2.爬取目标
这个实战爬虫主要完成以下目标:
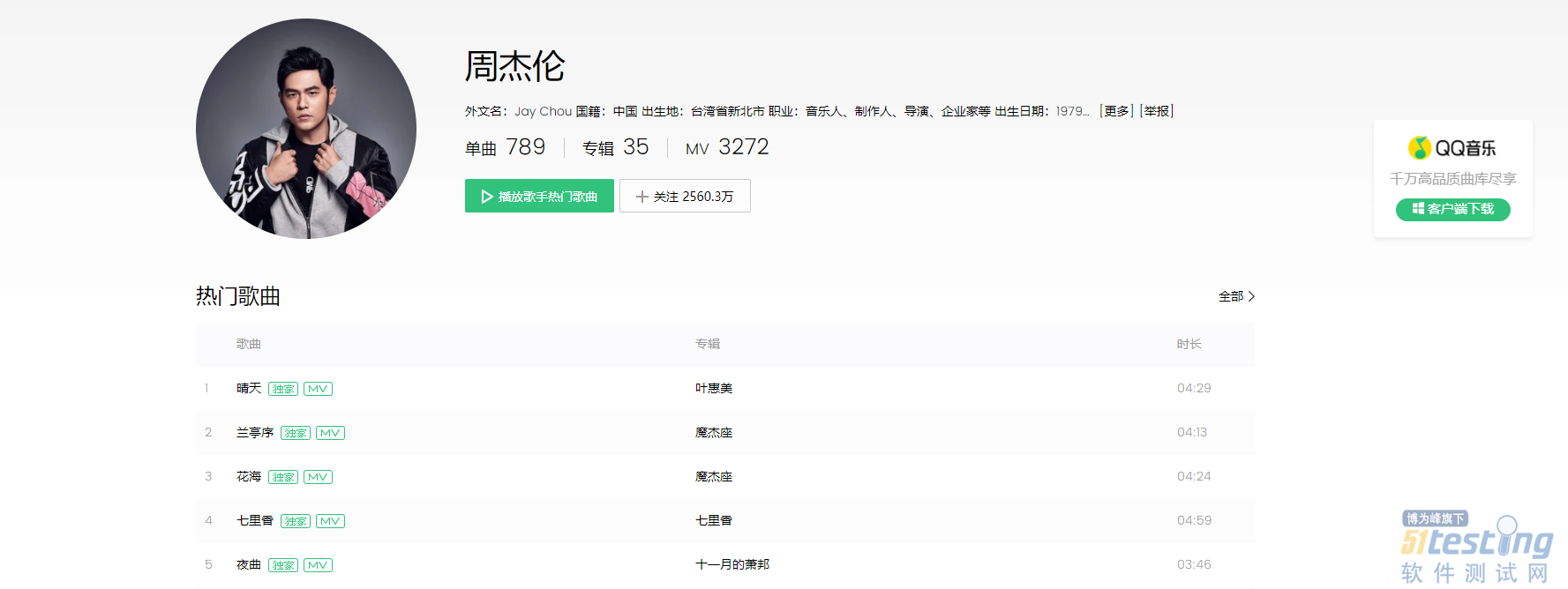
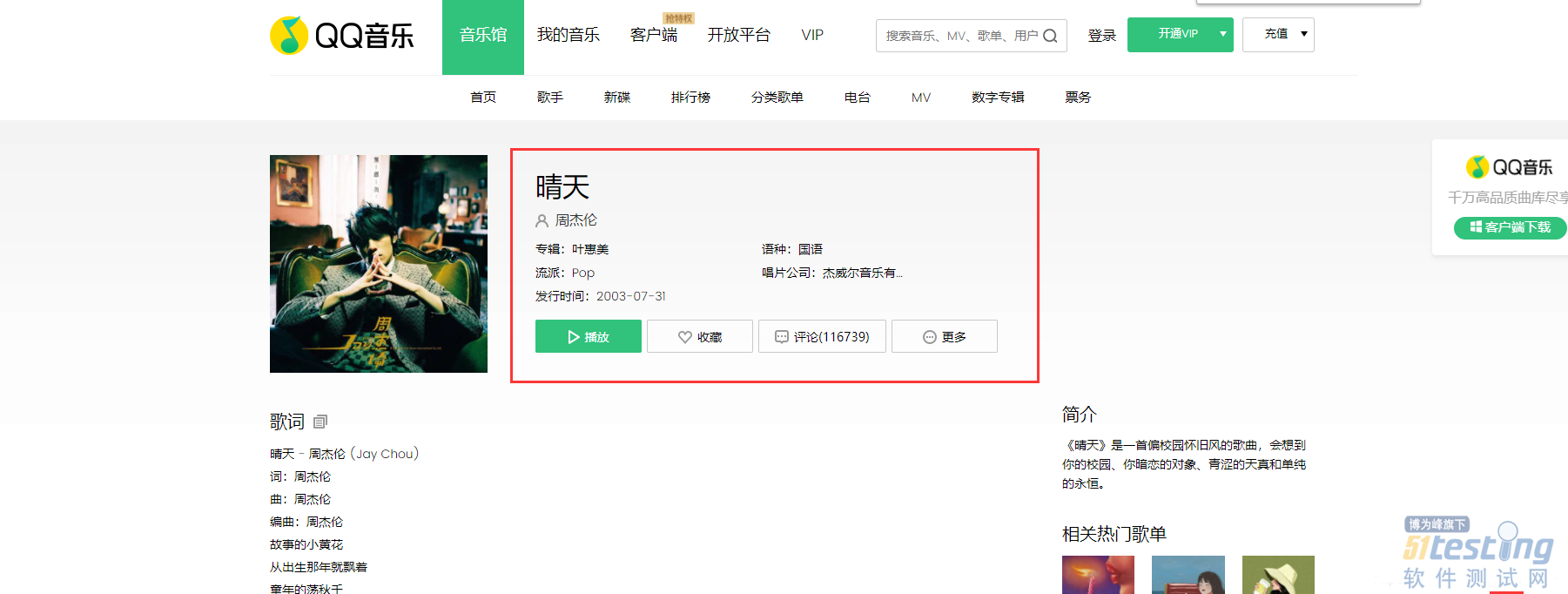
爬取QQ音乐官网指定歌手的前5首歌曲的基本信息和前五百条热门评论。
1)获取前五歌曲的url
分析该页面的代码得知,包裹所有歌曲信息的标签的class是唯一的,我们可以获取到它,再遍历所有子标签,也可以一次得到所有包裹歌曲信息的div,再获取里面的a标签。
2)获取歌曲基本信息
可以看到基本信息标签里的class名称是有一部分带语义的,那么通过css选择器肯定可以唯一确定下来。
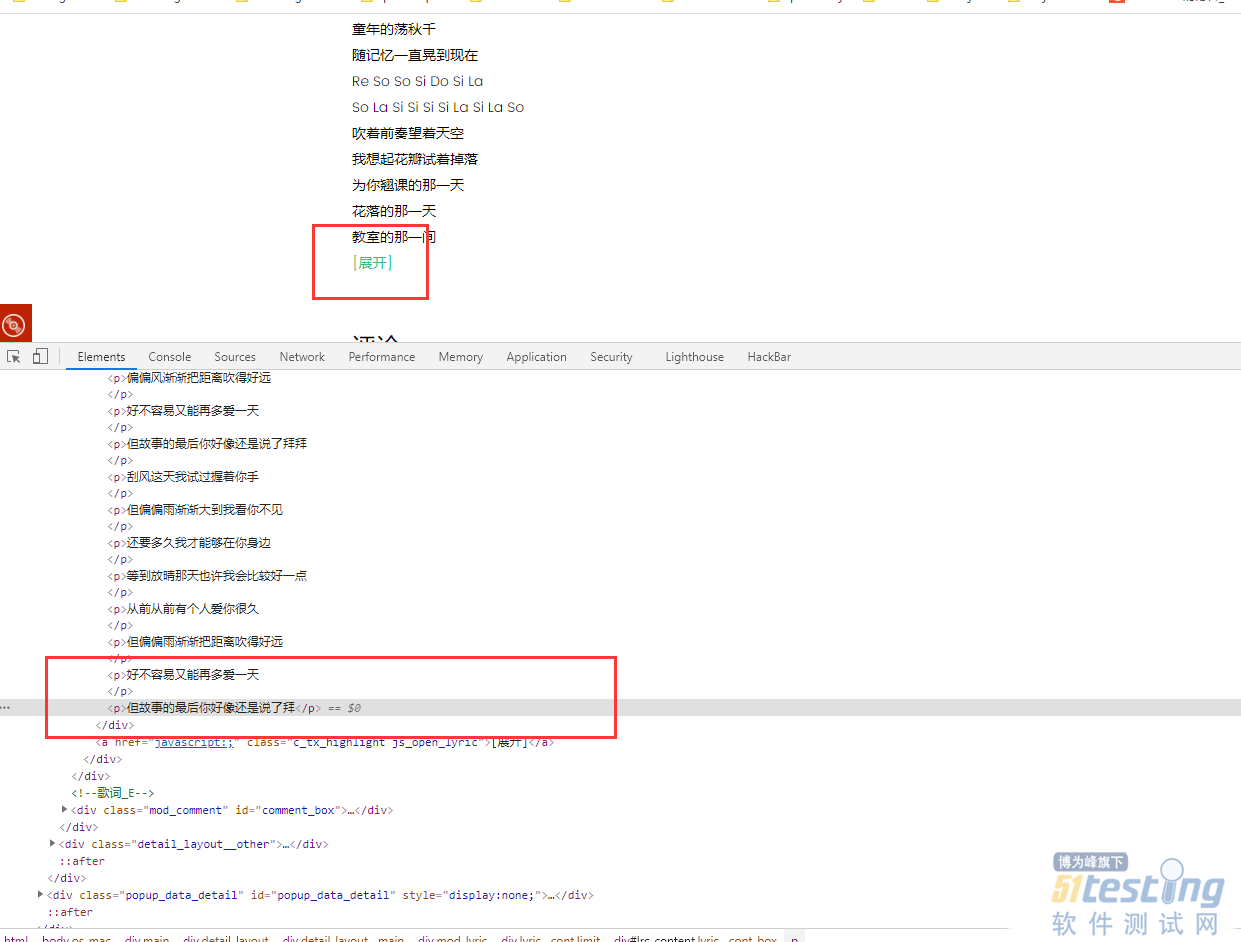
3)获取歌词
页面上的歌词不完整,似乎需要点击展开才行,但其实所有歌词已经在标签里面了,只是显示的问题了。
4.获取前五百条评论消息
我们可以看到热门评论一次是十五条,下面有一个点击加载更多链接,点了之后会多出15条。
我们需要模拟点击33次,获得510条评论。
5.写入CSV文件
使用csv库,将爬取到的数据写入到csv文件中进行持久化。
6.实现代码
from selenium import webdriver
import csv
from time import sleep
import time
#
# Author : ATFWUS
# Date : 2021-03-21 20:00
# Version : 1.0
# 爬取某个最热门五首歌曲的基本信息,歌词,前五百条热门评论
# 此代码仅供交流学习使用
#
#1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口
driver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
#2.打开QQ音乐 -周杰伦页面
driver.get("https://y.qq.com/n/yqq/singer/001t94rh4OpQn0.html")
#3.配置
csv_file = open('songs1.csv','w',newline='',encoding='utf-8')
writer = csv.writer(csv_file)
start = time.time()
# 取前5首歌曲
song_numer=5
song_url_list=[]
song_resourses=[]
songlist__item=driver.find_elements_by_class_name("songlist__item")
# 获取所有歌曲url
for song in songlist__item:
song__url=song.find_element_by_class_name("js_song").get_attribute("href")
song_url_list.append(song__url)
song_numer-=1
if(song_numer==0):
break
# print(song_url_list)
print("已获取当前歌手热门歌曲列表前五首的url")
print()
# 获取一首歌曲所需要的信息
def getSongResourse(url):
song_resourse={}
driver.get(url)
# 这个1.8秒用于等待页面所有异步请求的完成
sleep(1.8)
# 获取歌曲名
song_name=driver.find_element_by_class_name("data__name_txt").text
print("开始获取歌曲《"+song_name+"》的基本信息")
# 获取流派,发行时间,评论数
song_liupai = driver.find_element_by_css_selector(".js_genre").text[3:]
song_time = driver.find_element_by_css_selector(".js_public_time").text[5:]
song_comment_num = driver.find_element_by_css_selector(".js_into_comment").text[3:-1]
print("歌曲《" + song_name + "》基本信息获取完毕")
print("开始获取歌曲《" + song_name + "》的歌词")
# 点击展开歌词
driver.find_element_by_partial_link_text("[展开]").click()
sleep(0.3)
lyic=""
# 获取拼接歌词
lyic_box=driver.find_element_by_id("lrc_content").find_elements_by_tag_name("p")
for l in lyic_box:
if l.text!="":
lyic+=l.text+"\n"
print("歌曲《" + song_name + "》的歌词获取完毕")
print("开始获取歌曲《" + song_name + "》的第1-15条热门评论")
# 获取500条评论
comments=[]
# 点击加载更多29次,每次多出15条评论
for i in range(33):
try:
driver.find_element_by_partial_link_text("点击加载更多").click()
except:
break
print("开始获取歌曲《" + song_name + "》的第"+str((i+1)*15+1)+"-"+str((i+2)*15)+"条热门评论")
sleep(0.5)
comments_list=driver.find_element_by_css_selector(".js_hot_list").find_elements_by_tag_name("li")
for com in comments_list:
content=com.find_element_by_css_selector(".js_hot_text").text
content_time=com.find_element_by_css_selector(".comment__date").text
zan_num=com.find_element_by_class_name("js_praise_num").text
comment = {}
comment.update({"评论内容":content})
comment.update({"评论时间":content_time})
comment.update({"评论点赞次数":zan_num})
comments.append(comment)
print("歌曲《" + song_name + "》的前五百条热门评论获取完毕")
print("歌曲《"+song_name+"》所有信息获取完毕")
print()
song_resourse.update({"歌曲名":song_name})
song_resourse.update({"流派":song_liupai})
song_resourse.update({"发行时间":song_time})
song_resourse.update({"评论数":song_comment_num})
song_resourse.update({"歌词":lyic})
song_resourse.update({"500条精彩评论":comments})
return song_resourse
for song_page in song_url_list:
song_resourses.append(getSongResourse(song_page))
print("正在写入CSV文件...")
for i in song_resourses:
writer.writerow([i["歌曲名"],i["流派"],i["发行时间"],i["评论数"],i["歌词"]])
for j in i["500条精彩评论"]:
writer.writerow([j["评论内容"],j["评论时间"],j["评论点赞次数"]])
writer.writerow([])
csv_file.close()
end = time.time()
print("爬取完成,总耗时"+str(end-start)+"秒")
|
7.代码注意事项
·注意在驱动对象get请求网页之后,要sleep一段时间,这段时间是网站用来进行ajax请求获取所需数据的,如果不sleep,那么你获取的数据很有可能是空的,或者是默认值。
· 整个爬下来大概10分钟的样子,我已经将进度输出,不要提前关闭,因为我是最后才写入csv文件的, 提前关闭csv文件里什么也没有。
· QQ音乐最近有个bug,就是点击去获取更多后,新增的15条评论还是最初的,可能也是网的原因,代码那里应该没有问题的。
· 若某首歌曲的评论少于510条,会获取到所有的评论,但此时下面做数据读取的时候也要做相应的改变。
· 这个代码主要用于爬取主要数据,很多模拟操作可能不完善。
8.使用Pandas库简单的计算数据
有关Pandas库的使用,它的两种数据结构,请查看官网,这里不做说明。
先读取csv文件中的数据到内存中,再进行操作。
需要先安装pandas库:
import pandas as pd
import csv
# 这五个列表用于创建Series
se=[]
names=[]
# 先读取CSV文件的内容至内存中
with open("songs1.csv",'r',encoding="utf8") as f:
# 创建阅读器对象
reader = csv.reader(f)
rows = [row for row in reader]
index=0
print("开始解析CSV数据...")
for i in range(5):
s1=[]
# 读取第一行信息
names.append(rows[index].__str__().split(',')[0][2:-1])
index+=1
# 读取五百条评论的点赞消息
for j in range(510):
try:
s1.append(int(rows[index].__str__().split(',')[2][2:-2]))
index+=1
except:
break
se.append(s1)
# 读取掉空行
index+=1
print("CSV数据解析成功\n")
# 创建的5个series
for i in range(5):
series=pd.Series(se)
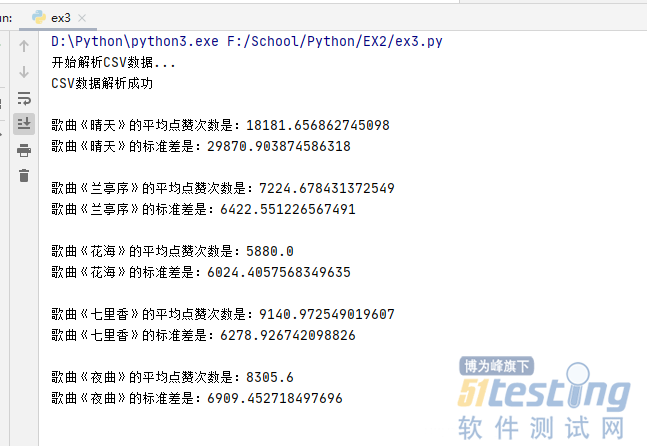
print("歌曲《"+names+"》的平均点赞次数是:" + str(series.mean()))
print("歌曲《" + names + "》的标准差是:" + str(series.std()))
print()
|
9.大致结果截图
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2021-4-20 11:03:29
发表于 2021-4-20 11:03:29









 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务