|
|
譯者按:
在文中被標識了[***]為譯文不確定之處。
若有指正之處,請發郵件到cnalexanderiii_gmail_com請把”_”換成郵箱的特殊符號。
原文地址:
http://www.bullseye.com/coverage.html
作者:Steve Cornett
譯者:AlexanderIII
聯繫方式: http://www.51testing.com/?61747
cnalexanderiii_gmail_com
代碼覆蓋率分析 [中文翻译0.1版]
介绍
代码覆盖率分析是
在程序中寻找没有被用例测过的地方的流程;
创建新的测试用例来增加覆盖率的流程;
决定代码覆盖定量的量度方法,同时也是一种间接度量质量的方法的过程。
它的另外一种使用方式是识别不会增加覆盖率的冗余用例,可由覆盖分析器来完成此过程。
使用覆盖率分析,实际上是确保你的测试的质量,而不是確保实际产品的质量。一般情況下你也不會在對你發佈產品上運行測試的時候使用覆蓋分析器。覆蓋分析通常需要訪問到測試程序源代碼,以及會經常需要用特殊的命令來重編譯。
本篇文章討論了向測試計劃增加覆蓋分析時所需要考慮的詳細內容。覆蓋率分析有著它的優點和缺點。你需要選擇採用哪些度量的方法。你要設定一個最低的覆蓋率來決定什麼時候停止分析覆蓋。覆蓋分析是一種測試的技術,但你不應該依賴於它的單獨使用。
覆蓋分析有時候也叫“測試覆蓋分析”, 這兩種術語是同義的。在學術界裏,術語“測試覆蓋”使用得比較多,在測試業界裏的話,使用得多的就是術語“代碼覆蓋”。同樣的,覆蓋分析器有時候也被叫做“覆蓋監控器”。比較喜歡測試業界術語。
結構測試與功能測試
代碼覆蓋分析是一種結構測試技術(AKA玻璃盒测试和白盒测试)。结构化测试是以源代码的意图表现为依据来比较被测程序行为的。这就与以需求规格为依据去比较被测程序行为的功能测试(AKA 黑盒测试)形成对比。结构化测试检查程序是如何工作的,以及代码结构和逻辑方面的潜在缺陷。功能测试是不管程序内部如何运作的,它只检查及关心程序实现了什么。
結構化測試通常也叫做路徑測試,那是因為你所創建的測試用例所經過的,就是程序路徑的結構。要注意的是,千萬不要把路徑測試和路徑覆蓋度量搞混了,下面章節會解釋。
粗略的看上去,結構化測試似乎是不太穩妥的,它不能夠找到被遺漏的錯誤。可是(從功能測試方面來說),需求規格不存在,甚至很少是完整的這種事是真實的,尤其會發生在產品開發快結束的時,由於需求規格更新得慢,產品它自己會取代需求規格的作用了。在越接近發佈的時間,功能測試和結構化測試的區別就越模糊。
前提
在覆蓋分析的背後的一些最基本的假設,可以讓我們知道這種測試技術的長處和短處。下面列出了幾點最最基本的假設。
- Bugs是和控制流相關的,你可以通過變換控制流的方法來找到Bugs[Beizer1990 p.60].比如說,一個程序員寫了"if (c)" 而不是 "if (!c)"。
- 你可以在不知道有什麼故障將會發生的情況下去找故障, 以及相信所有測試都是可信的,如果成功執行完這些測試,(沒有發現錯誤)就代表了程序的正確性[Morell1990]。測試人員明白一個正確程序會做些什麼,以及能夠識別與這些正確行為的差異。
- 其它的假設包括了,可完成的規格,沒有遺漏的錯誤,和沒有運行不到的代碼。
顯然,這些假設並不是一直都有效的。覆蓋分析可以找到一些疑似的bugs,但並不能夠找出所有的bugs. 覆蓋分析應用在要做許多判斷的應用程序上所得到的好處要比它應用在以數據為中心的程序(比如說數據庫應用)要多。
基本的度量方法
現在有很多的覆蓋度量方法,這裏所描述的只是一些基本的度量方法以及他們的優缺點。
語句覆蓋
這種度量報告是否每一條可執行語句都被測過了。它也同時可以被叫為,行覆蓋,段覆蓋[Ntafos1988],C1[Beizer1990 p.75],以及基本的塊覆蓋。基本塊覆蓋是和語句覆蓋是一樣的,除了它們測量的最基本代碼單位有所不同。基本塊覆蓋的基本單位是每一個非分支語句的序列。
我不是太鼓勵去使用描述得不太準確的名字 C1。人們有時會使用C1去標識判定覆蓋。因此這個術語就存在了二義性了。
這種度量的最主要好處就是直接應用到被測對象代碼裏,不需要再處理代碼。性能監視器[***]通常會使用這種度量。它的主要壞處就是它對一些控制結構不敏感。舉個下面的C/C++的代碼片段例子來說:
int* p = NULL;
if (condition)
p = &variable;
*p = 123;
在沒有一個測試用例能夠走假分支的情況下,語句覆蓋仍然會認為這段代碼被完全覆蓋了。但事實上,只要if 條件能夠走到假分支的話,這段代碼就會失敗。這就是語句覆蓋的最大的缺點。If語句是非常普遍的。
語句覆蓋並不報告循環是否達到了他們的停止條件情況,它只報告這個循環體是否被執行過。但在C,C++,和JAVA裡,這種限制會影響到包含了BREAK語句的循環。
由於DO-WHILE循環不管怎麼樣都會執行至少一次,語句覆蓋會把它看作與非分支語句同類。語句覆蓋對邏輯操作符完全無視,它還不能夠區別連續的SWITCH標籤。
和非判斷語句相比,測試用例一般情況下和判斷語句更加相關。你應該不會為了連續10句非分支語句寫10個單獨的測試用例吧?通常情況下,我們都只會用一個測試用例。舉個例子來講,有一個IF-ELSE語句,在THEN子句裡包含了一條語句,在ELSE子句裡包含了99條語句。當在走過了這兩個可能的路徑其中任何一條,語句覆蓋會給出相差很大的結果,要不是1%,要不就是99%。基本塊覆蓋就可以解決這個問題。
在支持語句覆蓋比其它度量要好的一個論點就是bugs是均勻的頒在代碼中的,因此可執行語句被覆蓋的百分比,就可以反應到故障能夠找到的百分經。然而,我們最基本的四種假設其中之一說的就是,故障是和控制流相關的,並不是和計算相關。而且,我們可以合理的預期到程序員將會把分支數和語句數保持在一定的比例上。
總之,計算性的語句影響這種度量的程度要比判定影響的程度要大。
判定覆蓋
這種度量報告的是在控制結構裏(例如IF語句和WHILE語句)的布爾表達式的真假值都被測過了。整個的布爾表達式被看成了一個單獨的真假判定,不管它裏面有沒有邏輯與或者邏輯非操作符。這種覆蓋還包括了SWITCH語句裏的CASE執行語句,EXCEPTION處理,以及中斷處理的覆蓋。
它也被叫做分支覆蓋,all-edges(所有邊界?)覆蓋[Roper1994 p.58], 基本路徑覆蓋[Roper1994 p.48], C2 [Beizer1990 p.75], DDP覆蓋(判定路徑覆蓋)[Roper1994 p.39].“基本路徑”測試是選擇相應的路徑去滿足判定覆蓋。
我不推薦使用C2這個描述不清楚的名字,它容易和術語C1搞混。
這種覆蓋的優點就是簡單,以及沒有語句覆蓋的那些問題。缺點就是會由於布爾表達式裏面的short-circuit 操作符,而忽略掉一些分支。比如下面的C/C++/JAVA代碼段:
if (condition1 && (condition2 || function1()))
statement1;
else
statement2;
在使用這種度量方法考慮覆蓋率分析的時候,可以完全不考慮調用function1()而達到完全覆蓋。當condition1和condition2都取真值的時候,整個表達式就真,當condition1為假的時候,整個表達式就為假。在這種情況下,short-circuit 操作符把調用function1排除在外。
條件覆蓋
條件覆蓋報告了每一個被邏輯非和邏輯與分開的布爾子表達式真假值的情況。條件覆蓋獨立的估量每個子表達式。
這種度量與判定覆蓋相似,但對控制流的敏感性又比它強。但是,完全條件覆蓋並不能保證完全的判定覆蓋。比如下面的C++/JAVA代碼例子:
bool f(bool e) { return false; }
bool a[2] = { false, false };
if (f(a && b)) ...
if (a[int(a && b)]) ...
if ((a && b) ? false : false) ...
在上面的例子中,不管a和b的值取什麼,所有的IF語句都會走假分支。但是,如果你使用了所有的a和b值的組合去測試代碼,條件覆蓋會報告完全覆蓋的結果。
多條件覆蓋
多條件覆蓋是報告是否所有布爾子表達式的組合都出現了。在前面介紹條件覆蓋的時候,子表達式都是被邏輯與邏輯非分開的。
如果想要達到對一個條件的多條件完全覆蓋的話,可以由這個條件的邏輯操作符真值表來獲得。
對於有short-circuit操作符的語言來說,像C,C++,和JAVA,多條件覆蓋有一個優點就是它需要非常徹底的測試。對於這些語言來講,多條件覆蓋和條件覆蓋非常相像。
這種度量的缺點就是決定所需最小測試用例集的過程是非常冗長的,尤其對於非常複雜的布爾表達式來說,更乏味。
它的另一種缺點就是對於相似複雜度的條件,它們所需要的測試用例數相差可以相當的大。比如下面的兩個C/C++/JAVA條件的例子:
1st a && b && (c || (d && e))
2nd ((a || b) && (c || d)) && e
為了得到完全的多條件覆蓋,第一個例子裏的條件需要6個測試用例,第二個需要11個。這兩個例子具有相同數量的操作數和操作符。
下面是測試用例的列表。
a && b && (c || (d && e))
1. F - - - -
2. T F - - -
3. T T F F -
4. T T F T F
5. T T F T T
6. T T T - -
((a || b) && (c || d)) && e
1. F F - - -
2. F T F F -
3. F T F T F
4. F T F T T
5. F T T - F
6. F T T - T
7. T - F F -
8. T - F T F
9. T - F T T
10. T - T - F
11. T - T - T
多條件覆蓋和條件覆蓋一樣不包括判定覆蓋。對於沒有short-circuit操作符的語言,比如VB和PASCAL,多條件覆蓋是一種有效的邏輯表達試的路徑覆蓋,它有一樣的優缺點。下面是VB的代碼例子。
If a And b Then
...
多條件覆蓋需要4個測試用例來覆蓋每一種A和B的組合真和假值。與路徑覆蓋一樣(?),它每增加一個邏輯操作符,測試用例所需要的數量就要增加一倍。
條件/判定覆蓋
條件/判定覆蓋是一種由條件覆蓋和判定覆蓋混在一起度量的方法。它簡單,沒有組成它的兩種度量的缺點。BullseyeCoverage量度的就是條件/判定覆蓋。
改進型條件/判定覆蓋
這種覆蓋也被叫為MC/DC和MCDC覆蓋。它需要足夠多的測試用例去驗證每個條件是可以影響到它所包括的判定結果。這種度量是由波音公司建立的,以及根據RCTA/DO-178B來開發航空軟件。
對於C,C++,和JAVA來說,這種度量需要的測試用例與條件/判定覆蓋相同。改進型的條件/判定覆蓋是為了有邏輯操作符但不是short-circuit的語言而設計的。當在C,C++和JAVA中的short circuit 邏輯操作符的結果可以影響到它所包含的判定時,它們僅僅起評估條件的作用。
在定義了這種度量的論文[Chilenski1994]中,章節"3.3 Extensions for short-circuit operators" 講了,"short-circuit操作符的使用,使得所有固定條件的需求與對不同條件影響的關係更加和諧"[***] 這篇論文裏使用的編程語言是ADA,它有非short circuit的邏輯操作符,也有shortcircuit的操作符。[***]
路徑覆蓋
這種度量報告的是每個FUNCTION裏面的每一個可能的路徑是否已經被走過了。路徑指的是從FUNCTION入口到出口的分支序列。
它的另外一種叫法是斷言覆蓋。斷言覆蓋是把路徑看做邏輯條件的可能組合[Beizer1990 p.98]。
由於循環覆蓋介紹了無限制路徑數目的方法,所以這種度量只考慮有限次數循環的可能性。這種度量有很多種變化來應對多種循環。內部邊界值路徑測試考慮了循環的兩種可能性:0次重複,以及多於0次的重複[Ntafos1988]。對於DO-WHILE循環,就是一次循環與多於一次循環。
路徑覆蓋的優點是需要非常彻底的測試。但它具有兩個非常嚴重的缺點。第一個,路徑的個數為分支數目的指數倍。比如,如果一個有10個IF語句的函數,它就有1024條路徑去測試。
當加了一條IF語句時,它的路徑數就翻倍到了2048。第二個缺點就是,由於數據間的關係,它有很多的路徑是不可能被測試的。比如下面的C/C++代碼例子:
if (success)
statement1;
statement2;
if (success)
statement3;
從路徑測試的角度來看這段代碼,它就有四條路徑。但事實上,它只有兩個是可行的:SUCCESS等於假和SUCCESS等於真。
研究學者已經研究出多種路徑覆蓋來對付數目具大的路徑。比如說,N長度子路徑覆蓋報告了你是否測試過了長度為N分支的每一個路徑。其它的衍变各類包括了線性代碼序列及跳轉[***]LCSAJ覆蓋, 數據流覆蓋。
其它度量
下面描述的是一些基本度量的變種和一些用得比較少的度量。
功能覆蓋
這個度量報告了你是否調用了每一個函數或者過程。它在初步測試中可以至少保證軟件的所有功能都得到一些覆蓋。主要簡單的測試可以快速的找出一些不足之處。BullseyeCoverage量度的是功能覆蓋。
調用覆蓋
這種度量報告的是你是否執行了每個函數的調用。這裏的假設是Bugs通常發生在模塊之間的接口處,它又叫做調用對覆蓋[***]。
LCSAJ覆蓋
這種是路徑覆蓋的一種變種,它考慮的是那些容易在程序代碼裏表現出來及不需要流圖的子路徑[Woodward1980]。一個LCSAJ是指一序列的源代碼按順序執行。
這裏說的“linear”序列可以包含判定,只要在運行時控制流真的是從這一條語句到那一條語句斷續執行。子路徑是由這些連接著的LCSAJ們所構建的。研究學者
通常把這種長度N的LCSAJ的路徑覆蓋比率叫做測試效力比率(TER)N+2。
這種度量的好處就是它比判定覆蓋更加彻底,但避免了路徑覆蓋的測試用例的指數級數量問題。不好的方面就是它也不能夠避免那些不可行的路徑。
數據流覆蓋
這種路徑覆蓋的變種只考慮從分配的變量到後續參考的變量之間的子路徑的情況。它的優點就是它所考慮到的路徑都是和程序處理數據的方法直接相關。它第一個缺點是
它並不包含判定覆蓋。另外一個缺點就是複雜。研究學者提出了幾種變種,但這幾種都是增加了它的複雜度的。比如說,這些改進了的度量方法因為計算語句中的變量的使用方法與在判定語句中的變量使用方法不同而不同,
本地與全局變量的使用不同而不同。通過對代碼優化進行數據流分析,指針也會造成問題的產生。
目標碼分支覆蓋
這種度量報告了每個機器語言條件轉移命令是成功的轉移到分支了還是失敗了。這種度量給出的結果與編譯器更加相關而不是程序結構。造成這種情況的原因是編譯器的代碼生成和優化技術, 能夠生成可以承受相似的源代碼結構[***]。
因為分支會被指令管道所中斷,所以有時候編譯器需要避免生成分支,而且要生成替代此分支的非分支指令序列。編譯器經常由於要讓函數少調用一些其它函數而要向函數裏內嵌一些代碼。如果此類函數包含了分支,那麼與源代碼比起來,它相應的機器碼就會非常明顯的增加了不少。
你最好是針對原始的源代碼來進行充足的測試,因為它比目標碼更加與程序的需求相關。
循環覆蓋
這種度量報告了每個循環是否被執行了0次,1次,以及多於1次。對於DO-WHILE循環,循環覆蓋報告的是你是否執行了1次和超過1次。這種度量最有價值的地方就是它可以決定WHILE循環和FOR循環執行超過一次,這樣的信息其它度量是不能提供的。具我所知,只有GCT實現了這種度量。
RACE覆蓋
這種度量報告了是否多線程在同一時間執行了同樣的代碼。它可以幫助查到同時對資源存取這樣的問題。它對於多線程程序的測試是非常有用的,比如說在一個操作系統裏使用。 據我所知,只有GCT實現了這種度量。
關係操作符覆蓋
這種度量報告的是具有關係操作符(<,<=,>,>=)的時候,邊界值的情況。 它假想的是這些邊界測試用例查到一些差一(OFF-BY-ONE)錯誤,以及用了錯誤的關係操作符(比如,用<代替了正確的<=)
下面舉個C/C++的例子來講:
if (a < b)
statement;
關係操作符覆蓋報告是否有A==B的這種情況發生。如果A==B發生了,若程序也給出正確的反應,那你就可以知道此關係操作符是<=是錯的。到目前為止,我就只知道GCT是有實現這個度量的。
弱轉換覆蓋[***](Weak Mutation Coverage)
這種度量與關係操作符覆蓋相似,但它更具有概括性[Howden1982]。它所報告的是測試用例是否顯露了錯誤的操作符操作數的使用問題。首先,它會將程序表達式裏原有的操作符與變量用替身操作符與替身變量取代,比如說使用"-"號替代掉"+"號,然後它再報告這個被轉換掉的條件的覆蓋率。
這種度量目前暫時還主要處於學術界中[譯者:此篇源文與譯文的年數相差較大,可能不太準確],它有多種不同的解釋[***]。而且在它可以具體應用之前,被測程序需要達到不少的特殊要求才行。同樣的,具我所知,它目前只在GCT中得到實現。
表覆蓋
這種度量講的是在某一數組中的每一個元素是否被引用了。這種方法對於被有限狀態機控制的程序非常有用。
度量方法的比較
當一個強的度量方法包含了另一個比較弱的度量方法時,你只能比較他們之間的相對的強處。
- 判定覆蓋包括了語句覆蓋,原因是當執行過每一條分支的時候,肯定會導致每一條語句都被執行了。
- 條件/判定覆蓋包括了判定覆蓋與條件覆蓋(這是由它們的定義得出來的)
- 路徑覆蓋包括了判定覆蓋
- 斷言覆蓋包括了路徑覆蓋和多條件覆蓋,以及其它大多數度量方法。
學術界也認為強的度量方法包含了弱的度量方法。覆蓋度量方法是不能從數量上進行比較。
發佈標準中的覆蓋率目標
每一個項目都必須要根據可用的測試資源以及防止推遲發佈的重要性,來選擇一個可以作為發佈標準的覆蓋率最小值。
很明顯的,和安全相關的軟件,它的覆蓋率就要有一個高一些的值。還有,你也可以把單元測試的覆蓋率最小通過值設置得比系統測試的要高。它這樣做的原因是低層次的代碼錯誤可以影響到很多高層的調用代碼。
當你使用語句覆蓋,判定覆蓋,或者條件/判定覆蓋時,覆蓋率的最小通過值就可以設為80%~90%,甚至更高。也有另外的一些人覺得如果把它設置為低於100%的話,是不能夠保證質量的。但問題是,如果你真的設置了100%的目標,那麼你將會花費巨多的精力去獲取這個100%。
假若我們可以把這同樣的精力放到另外的測試活動中,比如說正式的技術評審,它也許可以找到更多的Bugs。另一個要注意的是,不要把目標設為低於80%。
中間的覆蓋率目標
選擇一個中間的覆蓋率目標可以很有效的提高測試生產率。你最高的測試生產率發生在當你使用了最少精力找到了最多錯誤的時候。
精力是由時間評估的,這時間包括了創建測試用例,把它們加到你的測試套件裏,以及運行它們的時間。你應該使用覆蓋率分析策略來儘快增加覆蓋率。
這可以讓你更早的獲得找到失敗的最大概率。Figure 1闡明了高低測試生產率與相應覆蓋率。Figure 2闡明了相應的失敗發現比率。
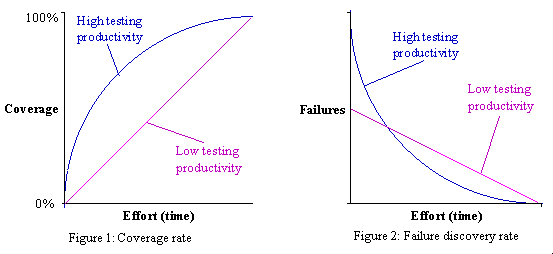
有一種可以較快增加覆蓋率的策略,它就是在追求更高的覆蓋率之前,先通過對整個測試程序進行一些簡單的覆蓋。你可以通過在早期的瀏覽被測程序的各個功能,來找到明顯的早期錯誤。比如,假設你的應用程序需要打印幾種類型的文檔,有一個bug使得程序的打印功能完全失效。如果一開始就每種類型的文檔都試著打印一份,你也許就可以很快的找到這個bug了。這樣就比通過針對一種類型的文檔而打印出很多同種類型的文檔進行彻底的測試要快得多。它的目的就是通過最少的測試,
比較容易的找到早期程序的錯誤。
下麵列出的覆蓋率目標順序就是這種策略的一種可行方案。
- 源代碼或者類的90%都可以調用至少一個函數[***]
- 調用至少90%的函數
- 每個函數至少獲得90%的條件/判定覆蓋率
- 獲得100%的條件/判定覆蓋率
需要注意的是,我們並不需要在初始的目標中就要達到100%覆蓋。這樣就可以把最難的地方放在後面測試。這樣做是對維持高測試生產率,以及用最少精力獲得最多結果是很重要的。
再者,還要注意要避免在定中間覆蓋率目標時使用弱度量方法,在定最終的發佈目標時使用強度量方法。如果這樣做的話,就會由弱度量方法的短處來決定推遲哪些測試用例。實際上應該把強度量方法應用在所有的目標上,以及可以根據每個測試用例的難度來決定哪些會被推遲。
結束語
覆蓋率分析是一種幫助把測試套件中的缝隙消除掉的結構化測試技術。當在沒有詳盡的需求規格的時候,它更能起到重要作用。對於C,C++,和JAVA來說,條件/判定覆蓋是最好的一種通用度量方法。如果把中間的覆蓋率目標(不管哪種類型)設置為100%,那麼它都將會降低測試的生產率。在發佈前,努力爭取達到語句,分支,或者條件覆蓋方法的80%~90%覆蓋吧!
References
Beizer1990 Beizer, Boris, "Software Testing Techniques", 2nd edition, New York: Van Nostrand Reinhold, 1990
Chilenski1994 John Joseph Chilenski and Steven P. Miller, "Applicability of Modified Condition/Decision Coverage to Software Testing", Software Engineering Journal, September 1994, Vol. 9, No. 5, pp.193-200.
RTCA/DO-178B, "Software Considerations in Airborne Systems and Equipment Certification", RCTA, December 1992, pp.31, 74.
Howden1982 "Weak Mutation Testing and Completeness of Test Sets", IEEE Trans. Software Eng., Vol.SE-8, No.4, July 1982, pp.371-379.
McCabe1976 McCabe, Tom, "A Software Complexity Measure", IEEE Trans. Software Eng., Vol.2, No.6, December 1976, pp.308-320.
Morell1990 Morell, Larry, "A Theory of Fault-Based Testing", IEEE Trans. Software Eng., Vol.16, No.8, August 1990, pp.844-857.
Ntafos1988 Ntafos, Simeon,"A Comparison of Some Structural Testing Strategies", IEEE Trans. Software Eng., Vol.14, No.6, June 1988, pp.868-874.
Roper1994 Roper, Marc, "Software Testing", London, McGraw-Hill Book Company, 1994
Woodward1980 Woodward, M.R., Hedley, D. and Hennell, M.A., "Experience with Path Analysis and Testing of Programs", IEEE Transactions on Software Engineering, Vol. SE-6, No. 3, pp. 278-286, May 1980.
[ 本帖最后由 AlexanderIII 于 2008-5-6 07:19 编辑 ] |
|








 /1
/1 

 关于我们
关于我们





 发表于 2008-5-6 00:41:32
发表于 2008-5-6 00:41:32


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务