TA的每日心情 | 无聊
4 天前 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
百度百科Selenium时,头一段文字介绍了selenium的主要作用和特点:selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。鉴于本文讨论的是python爬虫技术,所以有关其他功能暂时不去关注,下面开始说如何使用selenium模块中的webdriver驱动器来实现网络爬虫。
(1)网页技术基础
网络爬虫就是对网页上的内容进行定向获取,首先需要了解一下网页的基础知识。
网页为HTML文档,也就是由一系列HMTL标签(tag)、字符串构成的内容文档。如下:
<!DOCTYPE html>
<html>
<head>
<title>我的网页</title>
</head>
<body>
<div class="main">
<a href="http://www.baidu.com">百度一下</a>
<button id="btn">点我</button>
</div>
</body>
</html>
代码中的尖括号包裹的文本如<html>、<body>、<button>就是网页标签,通常成对构成。成对时起始标签为<html>,结束标签为</html>。
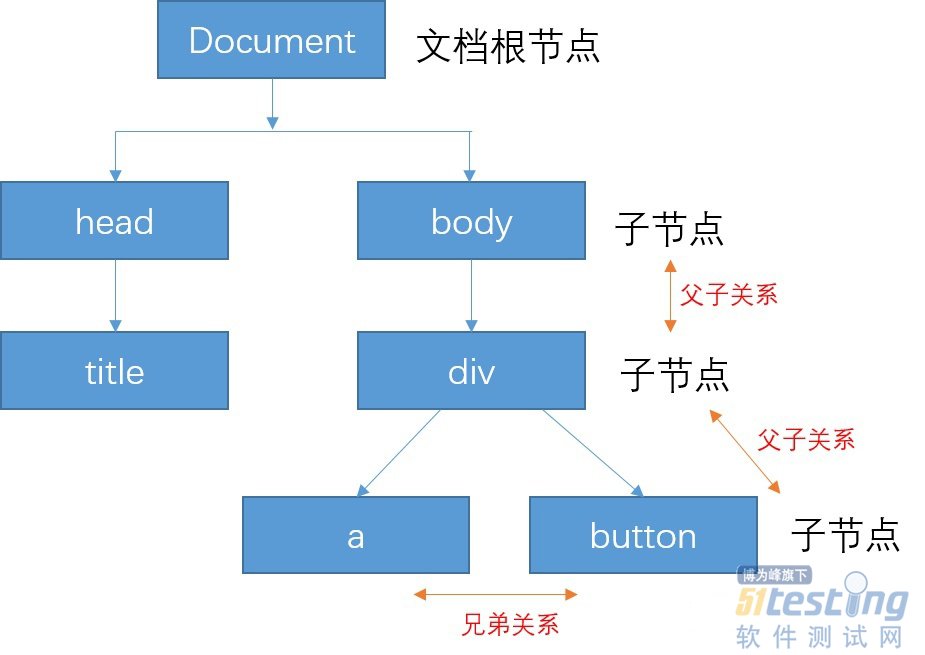
HTML文件使用网页浏览器打开时,浏览器内置的layout engine(布局引擎)将文档显示成我们看到的样子。对浏览器软件而言,它读取网页文档内容时,同时根据特定标签名构建一个HTML DOM树,这里的DOM是Document Object Model,即文档对象模型。这个树根据读入的HTML文档形成根节点、子节点,如上文档的DOM树结构为:
图上看到节点之间有层级关系,如head和body为文档根节点的子节点,head标签内部的title则为其子节点,body内部的div为其子节点,下一级的a和button之间为兄弟节点,与div为父子关系。
不过这些节点对象主要用于构建DOM树和标定位置,在页面上并不会显示出来,而在页面上显示的是节点的文本内容。如下:
DOM是W3C指定的标准,如上图可以看到,DOM是由一个个的node(节点)组成。节点之间还存在依赖关系,每个节点处的element(元素)是最重要的node,是html中一个标签tag里面的内容。在某些标签内还可以使用关联的属性来描述。例如上述程序中的:
<a href="http://www.baidu.com">百度一下</a>
a超链接就是div节点里的一个element(元素),href就是a标签的一个属性,“百度一下”为a标签的文本内容。
了解了网页文档显示及DOM构成的基本方式后,我们还需要将重点放在标签元素上,因为这是构成网页文档的基础,也是DOM树构建的基础。软件爬虫目标也是这些基本元素。
对于一个标签元素,除了标签tag名称外,通常为了定位和修饰需要,还会增加一些CSS样式用于丰富标签显示,这里的样式名主要包括两种:class名称、ID名称。如下例子:
<button id="btn" class="title">点我</button>
<div class="title">数据大会</div>
给button按钮标签添加了id名和class名。一般情况下class类名用于css显示样式设定,id名用于javascript程序精确定位元素。在一个网页文档中,多个网页元素可以有相同的class类名,这样使得多个网页元素具有相同的显示样式,而id名则相对唯一,即一个元素使用单独的id名,这样可以精确定位到这个元素。
为了网页显示美观,通常还需要对元素内容显示样式进行设定。样式内容包括字体大小、元素颜色、空间布局、边框、背景等,例如将上述文档加一个样式设定:
<!DOCTYPE html>
<html>
<head>
<title>我的网页</title>
<style type="text/css">
.main{background: grey;}
a{text-decoration: none;color:red;}
#btn{background: blue;color:white;}
</style>
</head>
<body>
<div class="main">
<a href="http://www.baidu.com">百度一下</a>
<button id="btn" class="title">点我</button>
</div>
</body>
</html>
在浏览器中显示效果为:
上例中设定显示样式时,采用了内容与样式分离的方法,即CSS样式单独设置,将其放置在head标签内。在例子中分别列举了使用标签名称,使用class类名和id名三种方式对网页元素设置样式。
标签名:直接使用标签名称,在大括号内给定样式相关属性名和值,定位到a元素
class类名:使用.符号,如.main,表示选择类名为main的元素,定位到div元素
ID名:使用#符号,如#btn,表示选择id名为btn的元素,定位到button按钮元素
这三种方式我们也总结为CSS选择器,也就是可以通过这三种方式精确定位到网页元素在文档中的位置。三种方式对比而言,在网页中会有多个元素具有相同的标签名和class类名,如果在选择时会是多项内容或者一组内容;而id名则能精确定位到某一个元素。
(2)selenium安装
selenium模块安装较为简单。如果安装了python3版本软件,同时在环境变量中设置了python路径,可以直接在cmd窗口中输入:
C:\Users\Administrator>pip install selenium
直接完成安装,不过这要取决于网速,有些可能就会直接down掉。如果这种方式安装不成功,则需要从pypi上下载下来到本地,然后执行安装。
下载如图:
然后使用解压缩软件打开,然后使用python setup.py install 方式安装:
F:\selenium-3.141.0>python setup.py install
selenium模块安装好后,可以打开selenium目录,其核心就是webdriver包,在webdriver包下有很多浏览器软件名称,如firefox、chrome、ie、opera等,也就是在使用selenium时,可以适用于多个浏览器软件环境。
但如果要使用python来操作selenium模块的webdriver对象,模拟浏览器操作,还需要支持的浏览器驱动器,如要使用chrome浏览器软件,就需要在python安装目录下将chrome浏览器的驱动器拷贝进去,如果要使用其他类型浏览器软件,就下载其他浏览器的驱动器到python安装目录。
chrome浏览器驱动: chromedriver.exe
firefox浏览器驱动: geckodriver.exe
如果使用chrome浏览器,就基于上述链接下载chromedriver.exe,然后拷贝到python安装目录下:
在selenium和对应浏览器的驱动器下载完成安装后,就可以在python终端测试了,如下:
from selenium import webdriver #导入selenium中的webdriver包
driver=webdriver.Chrome() #调用webdriver中的chrome对象,返回一个driver对象
如果终端没有报错,就说明运行正常,接下来就可以使用selenium实现爬虫了。
(3)selenium+webdriver爬虫
从一个自动测试百度搜索的例子开始:
#第一步,导入selenium模块的webdrivier包
from selenium import webdriver
#第二步,调用webdriver包的Chrome类,返回chrome浏览器对象
driver=webdriver.Chrome()
#第三步,如使用浏览器一样开始对网站进行访问
driver.maximize_window() #设置窗口最大化
driver.implicitly_wait(3) #设置等待3秒后打开目标网页
url="https://www.baidu.com"
#使用get方法访问网站
driver.get(url)
#使用find_element_by_id方法定位,这里定位到输入框
element_kw=driver.find_element_by_id('kw')
#使用send_keys方法,给输入框传递参数
element_kw.send_keys('曹鉴华')
#定位到百度一下按钮,模拟点击操作
element_btn=driver.find_element_by_id('su')
#获得点击搜索按钮后网页中id名为1的结果
result=driver.find_element_by_id('1')
#打印id名为1的文本内容
print(result.text)
#退出浏览器
driver.quit()
如上一步步的注释说明过程:第一步,导入webdriver包:
from selenium import webdriver
第二步,选择浏览器驱动,这里使用chrome浏览器:
driver=webdriver.Chrome()
这段程序执行后就会自动打开chrome浏览器。
第三步,使用浏览器对象的get访问方法访问目标网页,这里以百度网页为例:
url="http://www.baidu.com"
driver.get(url)
执行这段代码后,chrome浏览器等待3秒后会自动打开百度首页。
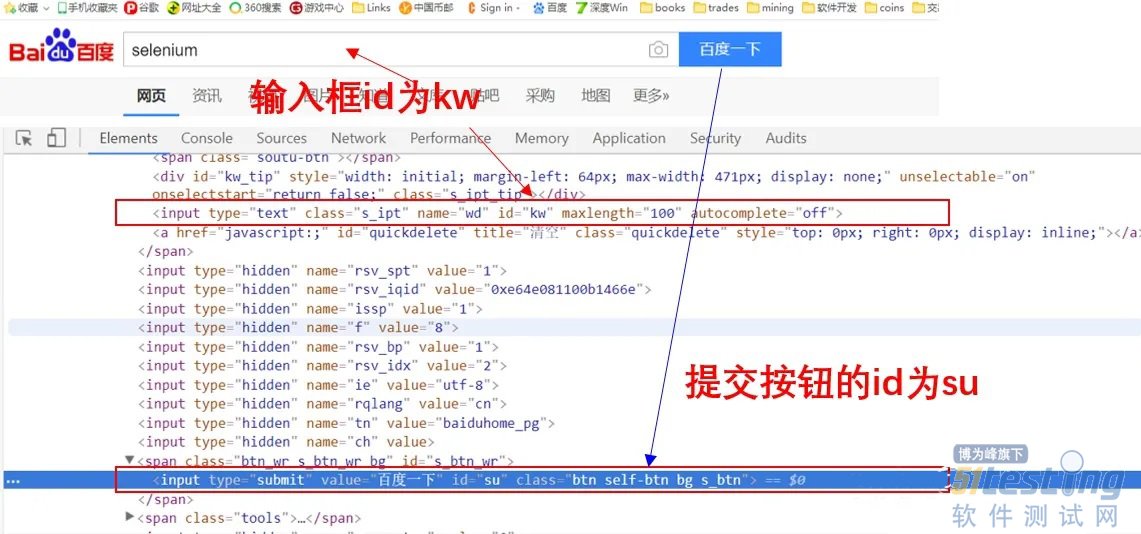
第四步,开始对目标网页元素进行精确定位,如百度,先定位到搜索框和百度一下按钮,我们可以使用开发者工具看到输入框及按钮内容处的源代码:
先定位到输入框对象,id为kw,使用方法为浏览器对象的find_element_by_id:
kw=driver.find_element_by_id('kw')
然后模拟往输入框输入内容,使用输入框对象的send_keys方法:
kw.send_keys("曹鉴华")
有了输入后,就可以模拟点击那个提交按钮,如上我们看到源代码中百度一下这个提交按钮的id为su,因此接下来使用浏览器对象的find_element_by_id的方法定位到这个按钮:
driver.find_element_by_id('su')
这样定位执行代码后实际上就已经进行了提交操作,执行这几行代码后,chrome浏览器会自动在输入框输入"曹鉴华",然后进行搜索操作,并在chrome浏览器中呈现搜索的结果。这种过程与使用浏览器操作一模一样,不过却是代码来实现的,而不是手动操作,由此来实现自动化测试。
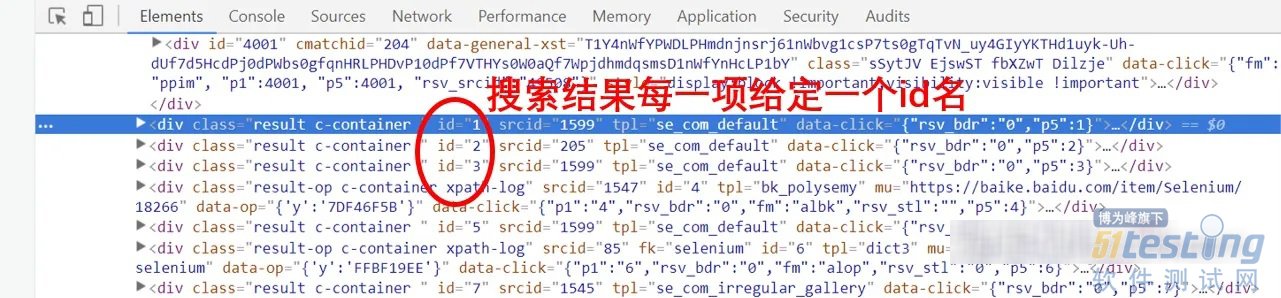
第五步,获得目标内容。案例中是获得搜索结果的第一项,同样我们需要使用开发者工具查看搜索结果列表的源代码表示方式,从而进行精确定位。
从源代码中可以看到对于搜索结果列表项,每一个搜索结果都给定了一个id名,如第一项就用id为1来定位,第2项就是id为2来定位。由此可以使用find_element_by_id方法来获取某一项搜索结果的具体内容:
#获得点击搜索按钮后网页中id名为1的结果
result=driver.find_element_by_id('1')
#打印id名为1的文本内容
print(result.text)
第六步,退出浏览器。通过第五步操作已经获得了想要的内容,由此就可以关闭浏览器对象了。使用方法为浏览器对象的quit操作。
driver.quit()
我们来对比一下使用浏览器操作和使用selenium代码爬虫结果:
两者效果是一样的。
从上述案例实现过程中发现在使用selenium自动化测试的时候,非常重要的一点就是元素的定位。在selenium模块中,一共包括8种元素定位的方法
·find_element_by_id : 使用id名来定位,通常可以实现精确定位到某条[url=]记录[/url]或内容
· find_element_by_name : 使用标签的name来定位,如表单内容部分
· find_element_by_xpath : 使用xpath来定位
· find_element_by_link_text :使用文字链接来定位
· find_element_by_partial_link_text:使用文字链接来定位
· find_element_by_tag_name : 使用标签名来定位
· find_element_by_class_name :使用类名类定位
· find_element_by_css_selector: 使用css选择器组合来定位
里面较常用的包括find_element_by_id 、find_element_by_xpath、ind_element_by_class_name 、find_element_by_css_selector这四种。
find_element_by_css_selector组合选择器:这是css selector,所以可以包括id和classname等。实际使用过程中还可以使用正则表达式来对目标进行匹配,如下对上面这个百度搜索案例修改一下:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_css_selector("input[id=\"kw\"]").send_keys('selenium') #定位输入框输入selenium
driver.find_element_by_css_selector("input[type=\"submit\"]").click() #定位搜索按钮点击按钮,属性选择type
time.sleep(5)
res=driver.find_element_by_id('1') #获得搜索结果列表的第一项
print(res.text)
driver.quit()
获得的结果如下:
.find_element_by_xpath: 根据xpath定位。Xpath是在一种在XML文档里查找信息的语言。主要就是路径信息,使用格式为:
标签+属性定位——xpath = "//标签名[@属性='属性值']"
如xpath="//book",表示选取所有节点名为book的子元素。同时有一种简便方法确定节点所在的xpath,就是在开发者工具中找到目标内容区域,然后右键点击,选择copy菜单里的copy xpath,就可以自动将xpath位置获取到。
如还是使用百度案例,将搜索selenium结果的第一项内容获取到,此时将获取结果采用xpath方式。首先获取到xpath:
然后张贴时可以获取xpath的值为://*[@id="1"]。将上述代码中res=driver.find_element_by_id('1') ,替换为:
res=driver.find_element_by_xpath('//*[@id="1"]')
print(res.text)
运行时获得结果与上述一样。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-6-19 15:15:53
发表于 2023-6-19 15:15:53










 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务