TA的每日心情 | 擦汗
5 小时前 |
|---|
签到天数: 1047 天 连续签到: 5 天 [LV.10]测试总司令
|
程序设计的好与坏,早在我们青葱岁月时就接触过了,只是那是并不知道这竟如此重要。能够立即改善程序设计、写出“好”代码的知识有以下几点:
· 面向对象五个基本原则;
· 常见的三种架构;
· 绘图;
· 起一个好名字;
· 优化嵌套的 if else 代码;
当然,其他技术知识的丰富程度也决定了程序设计的好坏。例如通过引入消息队列解决双端性能差异问题、通过增加缓存层提高查询效率等。下面我们一起来看看,上面列出的知识点包含哪些内容,这些内容对代码和程序设计的改善有何帮助。
面向对象五个基本原则
本书作者是 2010 级学生,面向对象是作者青葱时期发展火热的编程范式。它的五个基本原则是:
· 单一职责原则;
· 开放封闭原则;
· 依赖倒置原则;
· 接口隔离原则;
· 合成复用原则;
下面我们将通过对比和场景假设的方式了解五个基本原则对代码质量的影响。
立竿见影的单一职责原则
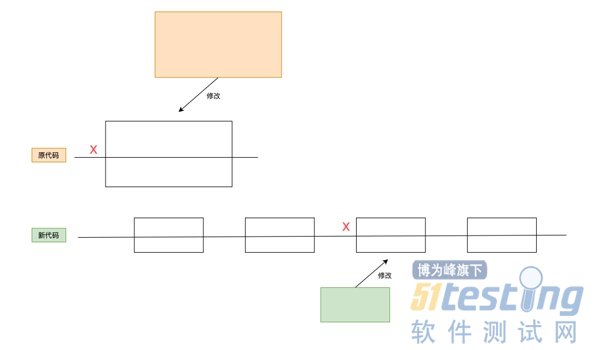
没错,立竿见影、效果卓越。对于我们这些自学编程无师自通的人来说,能把功能实现就可以了,根本没有时间考虑代码优化和维护成本问题。时光流逝,竟在接触编程很长一段时间后才发现它竟如此重要。
俗话说只要代码写的够烂,提升就足够明显。以一个从文件内容中匹配关键数据并根据匹配结果发出网络请求的案例,看看大部分程序员的写法:
- import re
- import requests
- FILE = "./information.fet"
- def extract(file):
- fil = open(file, "r")
- content = fil.read()
- fil.close()
- find_object = re.search(r"url=\d+", content)
- find = find_object.group(1)
- text = requests.get(find)
- return text
- if __name__ == "__main__":
- text = extract(FILE)
- print(text)
· 如果读取文件的时候发生异常了怎么办?
· 如果数据源发生变化该如何处理?
· 如果网络请求返回的数据不符合最终要求怎么办?
如果你心里的第一个反应是改代码,那你就要注意了。完成一件事中间的某个环节发生变化,改代码是在所难免的,但是如果按照上面这种写法,不仅代码越改越乱,连逻辑也会越来越乱。单一职责原则表达的是让一个函数尽量只做一件事,不要将多件事混杂在一个函数中。
上面的代码如果重新设计,我认为至少应该是这样的:
- def get_source():
- """获取数据源"""
- return
- def extract_(val):
- """匹配关键数据"""
- return
- def fetch(val):
- """发出网络请求"""
- return
- def trim(val):
- """修剪数据"""
- return
- def extract(file):
- """提取目标数据"""
- source = get_source()
- content = extract_(source)
- text = trim(fetch(content))
- return text
- if __name__ == "__main__":
- text = extract(FILE)
- print(text)
单一职责原则的核心是解耦和增强内聚力,如果一个函数承担的职责过多,等于把这些职责耦合在一起,这种耦合会导致脆弱的设计。当发生变化时,原本的设计会遭受到意想不到的破坏。单一职责原则实际上是把一件事拆分成多个步骤,代码修改造成的影响范围很小。
让代码稳定性飞升的开放封闭原则和依赖倒置原则
开放封闭原则中的开放指的是对扩展开放,封闭指的是对修改封闭。需求总是变化的,业务方这个月让你把数据存储到 MySQL 数据库中,下个月就有可能让你导出到 Excel 表格里,这时候你就得改代码了。这个场景和上面的单一职责原则很相似,同样面临代码改动,单一职责原则示例主要表达的是通过解耦降低改动的影响,这里主要表达的是通过对扩展开放、对修改封闭提高程序应对变化的能力和提高程序稳定性。
稳定这个词如何理解呢?
较少的改动或者不改动即视为稳定,稳定意味着调用这个对象的其它代码拿到的结果是可以确定的,整体是稳定的。
按照一般程序员的写法,数据存储的代码大概是这样的:
- class MySQLSave:
- def __init__(self):
- pass
- def insert(self):
- pass
- def update(self):
- pass
- class Business:
- def __init__(self):
- pass
- def save(self):
- saver = MySQLSave()
- saver.insert()
· 重新写一个存储到 ExcelSave 的类;
· 对 MySQLSave 类进行改动;
上面的两种选择,无论怎么选都会改动 2 个类。因为不仅存储的类需要改动,调用处的代码也需要更改。这样一来,它们整体都是不稳定的。如果换一种实现方式,根据依赖倒置的设计指导可以轻松应对这个问题。边看代码边理解:
- import abc
- class Save(metaclass=abc.ABCMeta):
- @abc.abstractmethod
- def insert(self):
- pass
- @abc.abstractmethod
- def update(self):
- pass
- class MySQLSave(Save):
- def __init__(self):
- self.classify = "mysql"
- pass
- def insert(self):
- pass
- def update(self):
- pass
- class Excel(Save):
- def __init__(self):
- self.classify = "excel"
- def insert(self):
- pass
- def update(self):
- pass
- class Business:
- def __init__(self, saver):
- self.saver = saver
- def insert(self):
- self.saver.insert()
- def update(self):
- self.saver.update()
- if __name__ == "__main__":
- mysql_saver = MySQLSave()
- excel_saver = Excel()
- business = Business(mysql_saver)
依赖倒置中的倒置,指的是依赖关系的倒置。之前的代码是调用方 Business 依赖对象 MySQLSave,一旦对象 MySQLSave 需要被替换, Business 就需要改动。依赖倒置中的依赖指的是对象的依赖关系,之前依赖的是实体,如果改为后面这种依赖抽象的方式,情况就会扭转过来:
实体 Business 依赖抽象有一个好处:抽象稳定。相对于多变的实体来说,抽象更稳定。代码改动前后的依赖关系发生了重大变化,之前调用方 Business 直接依赖于实体 MySQLSave,通过依赖倒置改造后 Busines 和 ExcelSave、 MySQLSave 全都依赖抽象。
这样做的好处是如果需要更换存储,只需要创建一个新的存储实体,然后调用 Business 时传递进去即可,这样可以不用改动 Business 的代码,符合面向修改封闭、面向扩展开放的开放封闭原则;
依赖倒置的具体实现方式使用了一种叫做依赖注入的手段,实际上单纯使用依赖注入、不使用依赖倒置也可以满足开闭原则要求,感兴趣的读者不妨试一试。
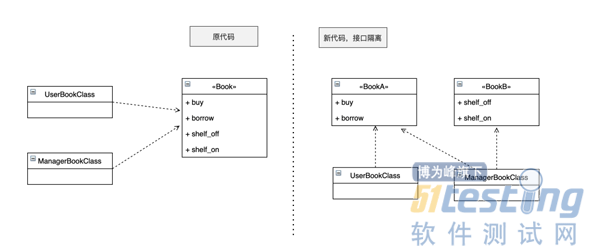
挑肥拣瘦的接口隔离原则
接口隔离原则中的接口指的是 Interface,而不是 Web 应用里面的 Restful 接口,但是在实际应用中可以将其抽象理解为相同的对象。接口隔离原则在设计层面看,跟单一职责原则的目的是一致的。接口隔离原则的指导思想是:
· 调用方不应该依赖它不需要的接口;
· 依赖关系应当建立在最小接口上;
这实际上是告诉我们要给接口减肥,过多功能的接口可以选用拆分的方式优化。举个例子,现在为图书馆设计一个图书的抽象类:
- import abc
- class Book(metaclass=abc.ABCMeta):
- @abc.abstractmethod
- def buy(self):
- pass
- @abc.abstractmethod
- def borrow(self):
- pass
- @abc.abstractmethod
- def shelf_off(self):
- pass
- @abc.abstractmethod
- def shelf_on(self):
- pass
这样是不是一下就看懂了。这个指导思想很重要,不仅能够指导我们设计抽象接口,也能够指导我们设计 Restful 接口,还能够帮助我们发现现有接口存在的问题,从而设计出更合理的程序。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2021-6-29 09:49:06
发表于 2021-6-29 09:49:06



 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务