TA的每日心情 | 无聊
4 小时前 |
|---|
签到天数: 1052 天 连续签到: 2 天 [LV.10]测试总司令
|
添加用户查询用户登录三个接口调通后线程组设置为10个间隔时间(Ramp-Upperiod)与循环次数去掉勾选调度器设置持续时间60s设置响应断言察看结果树与SummaryReport移动到http请求之外一起监控开始执行具体如下:
10个并发压三个接口持续一分钟导致自己电脑超频了。
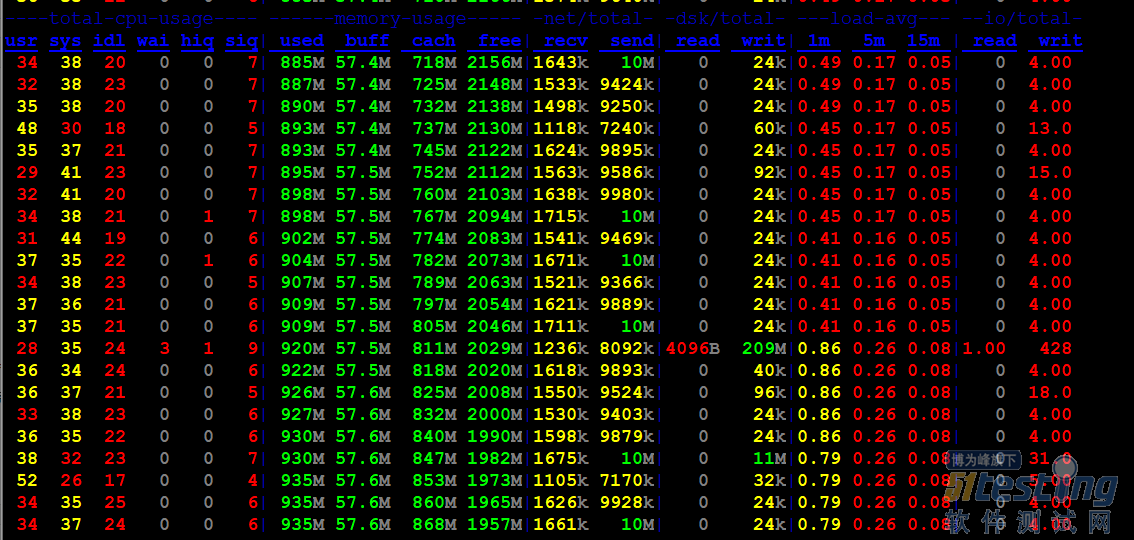
进入到部署cms的服务器当中使用yum-yinstalldstat命令在线安装dstat性能工具。
使用dstat-c-m-n-d-r-l监控cpu内存网络磁盘io系统负载情况。
下面对显示出来的部分信息作一些说明:
cpu:hiq、siq分别为硬中断和软中断次数。
system:int、csw分别为系统的中断次数(interrupt)和上下文切换(contextswitch)。
其他的都很好理解。
语法
dstat[-afv][options..][delay[count]]
常用选项
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C0,1是显示cpu0和cpu1的信息。
-d:显示磁盘读写数据大小。
-Dhda,total:includehdaandtotal。
-n:显示网络状态。
-Neth1,total:有多块网卡时,指定要显示的网卡。
-l:显示系统负载情况。
-m:显示内存使用情况。
-g:显示页面使用情况。
-p:显示进程状态。
-s:显示交换分区使用情况。
-S:类似D/N。
-r:I/O请求情况。
-y:系统状态。
--ipc:显示ipc消息队列,信号等信息。
--socket:用来显示tcpudp端口状态。
-a:此为默认选项,等同于-cdngy。
-v:等同于-pmgdsc-Dtotal。
--output文件:此选项也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。
例:dstat--output/root/dstat.csv&此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。
当然dstat还有很多更高级的用法,常用的基本这些选项,更高级的用法可以结合man文档。
监测界面各参数含义(部分)
Procs
r:运行的和等待(CPU时间片)运行的进程数,这个值也可以判断是否需要增加CPU(长期大于1)
b:处于不可中断状态的进程数,常见的情况是由IO引起的
Memory
swpd:切换到交换内存上的内存(默认以KB为单位)。如果swpd的值不为0,或者还比较大,比如超过100M了,但是si,so的值长期为0,这种情况我们可以不用担心,不会影响系统性能。
free:空闲的物理内存
buff:作为buffercache的内存,对块设备的读写进行缓冲
cache:作为pagecache的内存,文件系统的cache。如果cache的值大的时候,说明cache住的文件数多,如果频繁访问到的文件都能被cache住,那么磁盘的读IObi会非常小。
Swap
si:交换内存使用,由磁盘调入内存
so:交换内存使用,由内存调入磁盘
内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响。磁盘IO和CPU资源都会被消耗。
我发现有些朋友看到空闲内存(free)很少或接近于0时,就认为内存不够用了,实际上不能光看这一点的,还要结合si,so,如果free很少,但是si,so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
磁盘IO
bi:从块设备读入的数据总量(读磁盘)(KB/s)
bo:写入到块设备的数据总理(写磁盘)(KB/s)
注:随机磁盘读写的时候,这2个值越大(如超出1M),能看到CPU在IO等待的值也会越大
System
in:每秒产生的中断次数
cs:每秒产生的上下文切换次数
上面这2个值越大,会看到由内核消耗的CPU时间会越多
Cpu
usr:用户进程消耗的CPU时间百分比
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或者进行加速了(比如PHP/Perl)。
sys:内核进程消耗的CPU时间百分比
sys的值高时,说明系统内核消耗的CPU资源多,这并不是良性的表现,我们应该检查原因。
wai:IO等待消耗的CPU时间百分比
wa的值高时,说明IO等待比较严重,这可能是由于磁盘大量作随机访问造成,也有可能是磁盘的带宽出现瓶颈(块操作)。
idl:CPU处在空闲状态时间百分比
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2021-6-24 09:56:24
发表于 2021-6-24 09:56:24



 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务