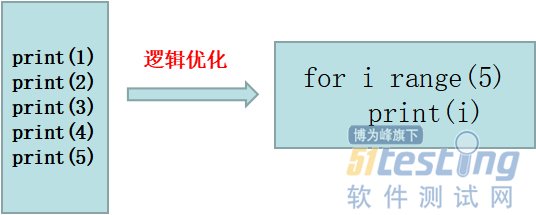
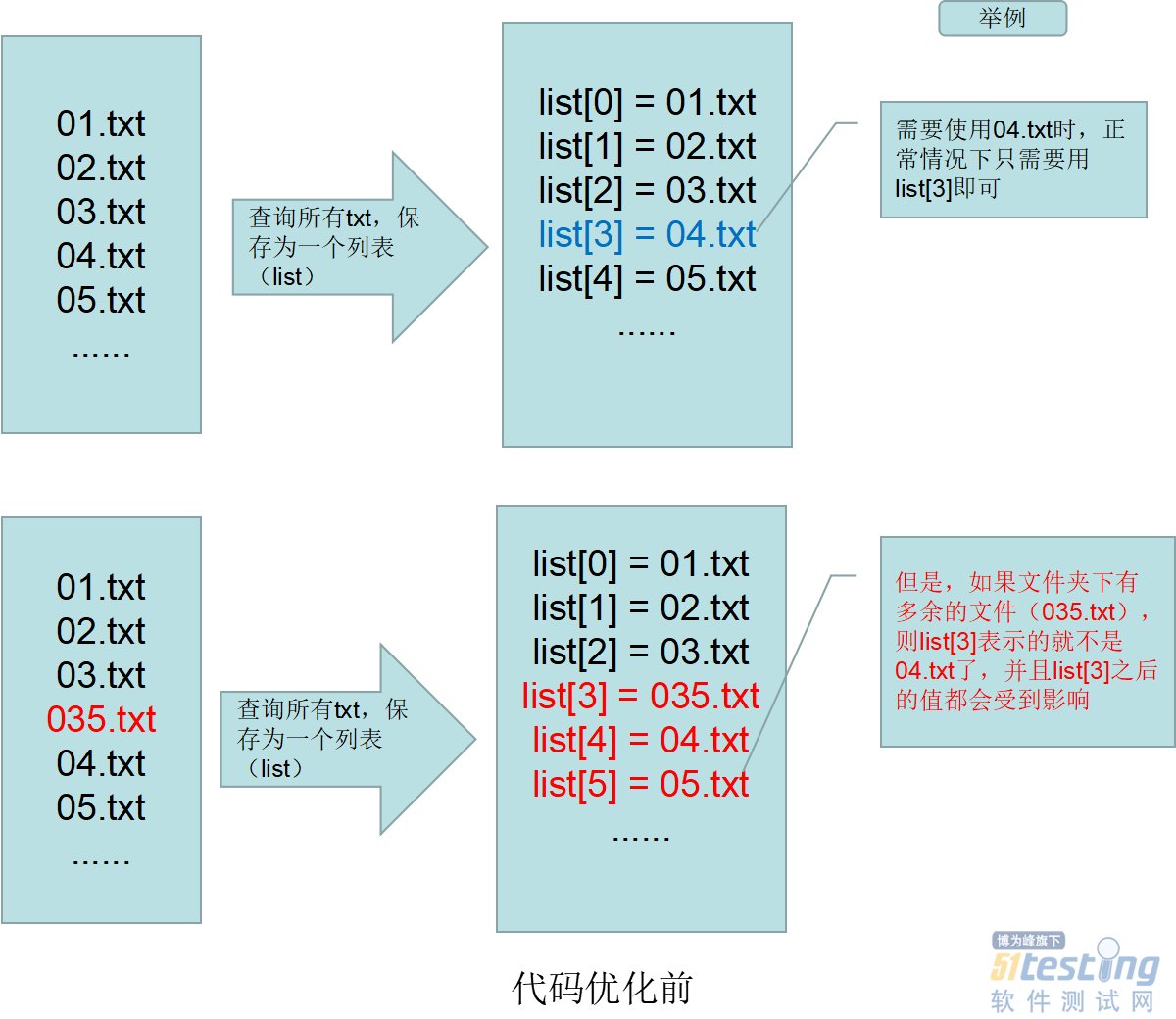
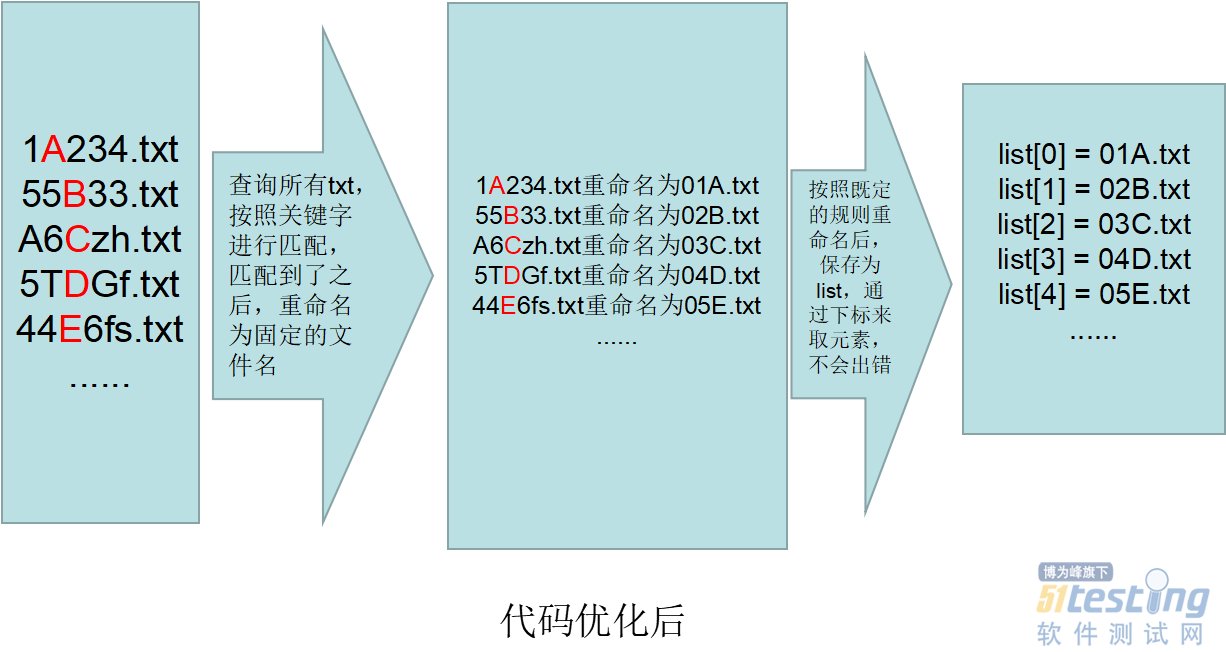
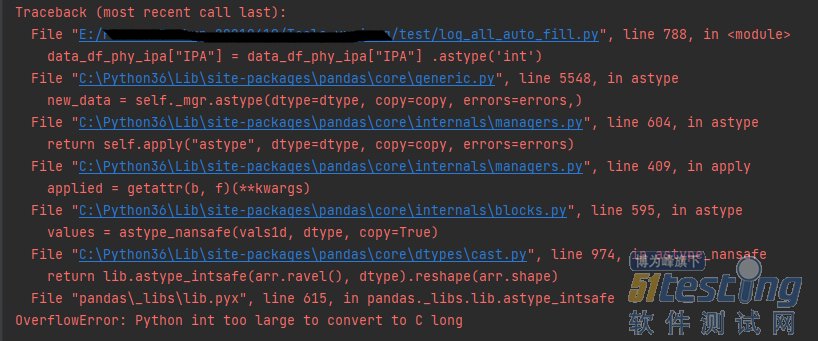
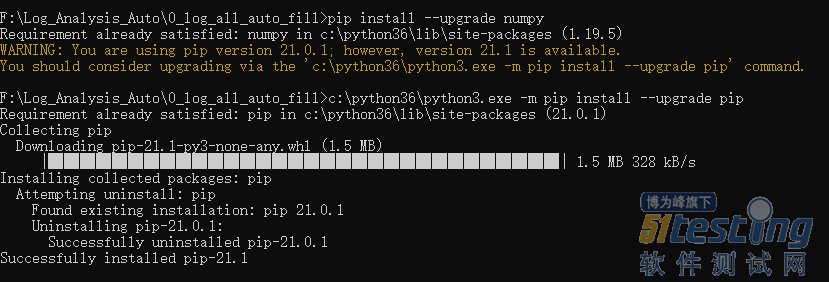
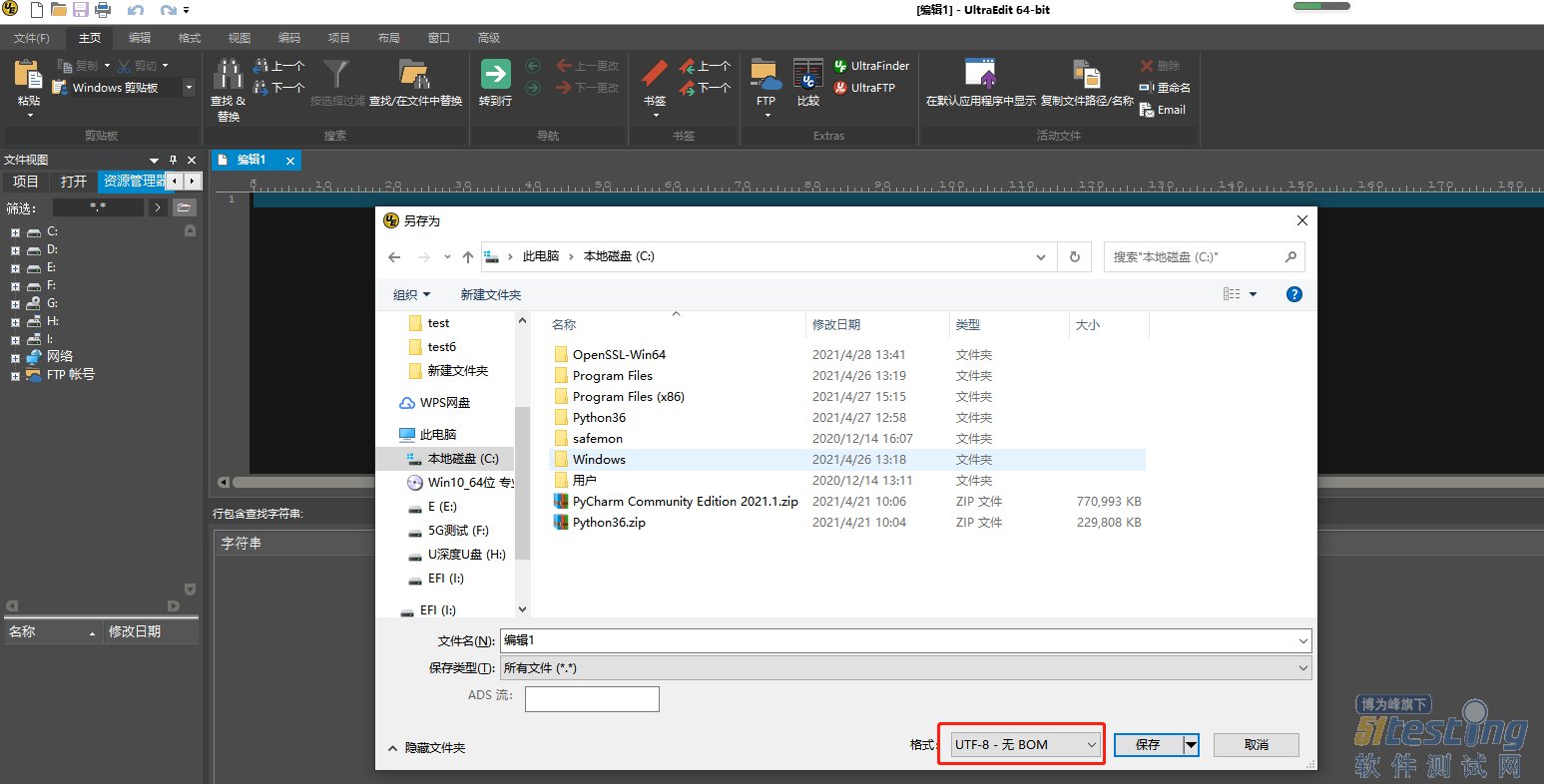
import re
def txt_cut(filel,keyws,cutby=r'[|]\s*'):
file = open(str(filel), "r")
txtlines = file.readlines()
data_is_need_num = 0
all_data = []
for line_num in range(len(txtlines)):
cur_line_data = txtlines[line_num]
for i in range(len(keyws)):
if keyws in cur_line_data:
data_is_need_num = data_is_need_num + 1
data_split = re.split(cutby, cur_line_data)
all_data.append(data_split)
if data_is_need_num == 0:
print("没有找到您想找的关键字:")
for i in range(len(keyws)):
print(keyws)
file.close()
return all_data
|








 /1
/1 

 关于我们
关于我们






 发表于 2021-6-16 09:53:42
发表于 2021-6-16 09:53:42


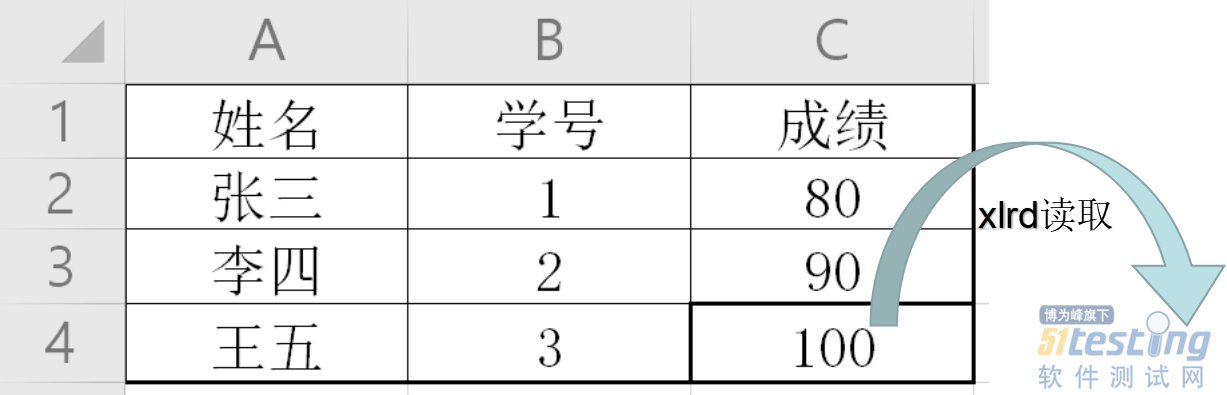
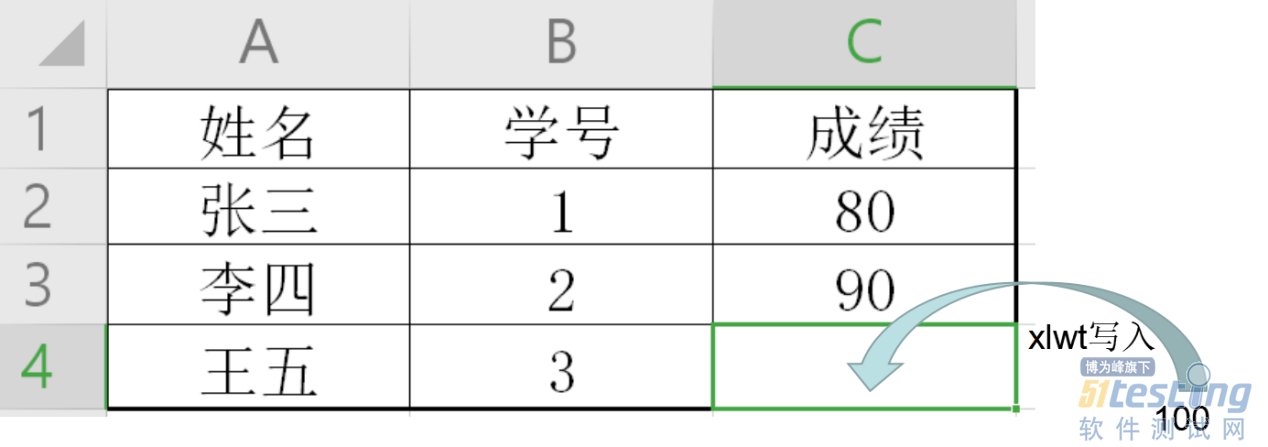

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务 楼主
楼主