TA的每日心情 | 无聊
13 小时前 |
|---|
签到天数: 1051 天 连续签到: 1 天 [LV.10]测试总司令
|
最近想爬下B站的弹幕和评论,发现网上找到的教程基本都失效了,毕竟爬虫和反爬是属于魔高一尺、道高一丈的双方,程序员小哥哥们在网络的两端斗智斗勇,也是精彩纷呈。
当然了,对于爬虫这一方,爬取网站数据,一般目的都是比较明确的,比如我这里就是为了冰冰,废话不多说,开干!
获取弹幕数据
这里先声明一点,虽然网络上的整体教程都失效了,但是有一些步骤还是可以参考的,比如我们可以知道,对于弹幕数据,我们是可以通过如下的一个接口来获取的。
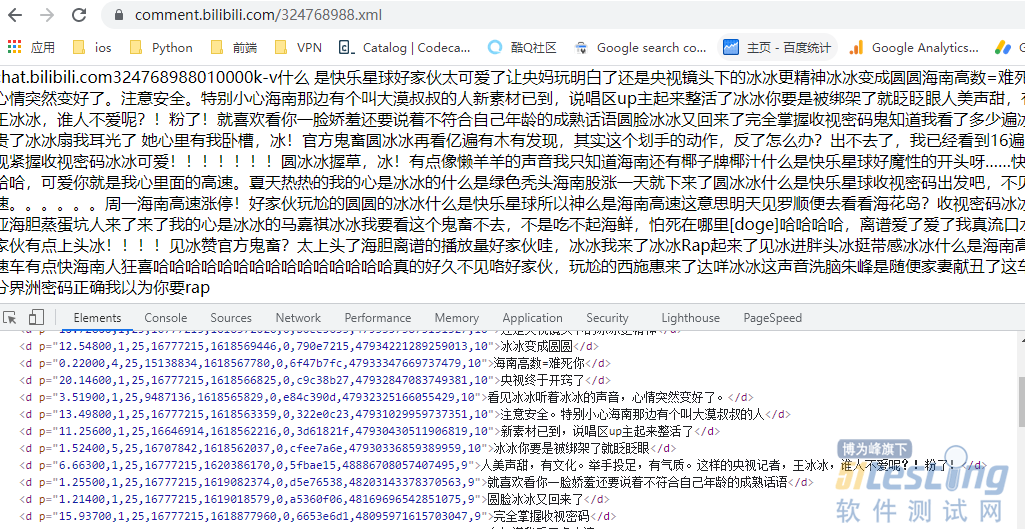
在浏览器打开可以看到如下:
数据还是非常干净的,那么下一步就是看如何获取这个 xml 的 url 地址了,也就是如何获取 324768988 ID;
接下来我们搜索整个网页的源码,可以发现如下情况;
也就是说,我们需要的 ID 是可以在 script 当中获取的,下面就来编写一个提取 script 内容的函数。
def getHTML_content(self):
# 获取该视频网页的内容
response = requests.get(self.BVurl, headers = self.headers)
html_str = response.content.decode()
html=etree.HTML(html_str)
result=etree.tostring(html)
return result
def get_script_list(self,str):
html = etree.HTML(str)
script_list = html.xpath("//script/text()")
return script_list
拿到所有的 script 内容之后,我们再来解析我们需要的数据。
script_list = self.get_script_list(html_content)
# 解析script数据,获取cid信息
for script in script_list:
if '[{"cid":' in script:
find_script_text = script
final_text = find_script_text.split('[{"cid":')[1].split(',"page":')[0]
最后,我们再把整体代码封装成一个类,就完成了弹幕抓取的数据收集工作了。
spider = BiliSpider("BV16p4y187hc")
spider.run()
结果如下:
获取评论数据
对于评论数据,可能要复杂一些,需要分为主(main)评论和回复主评论的 reply 评论。
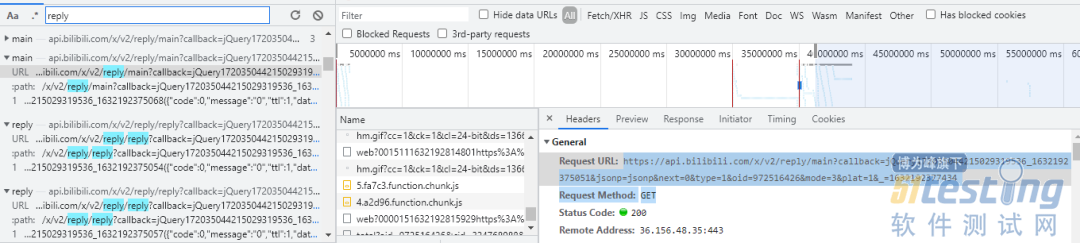
我们通过浏览器工具抓取网页上的所有请求,然后搜索 reply,可以得到如下结果:
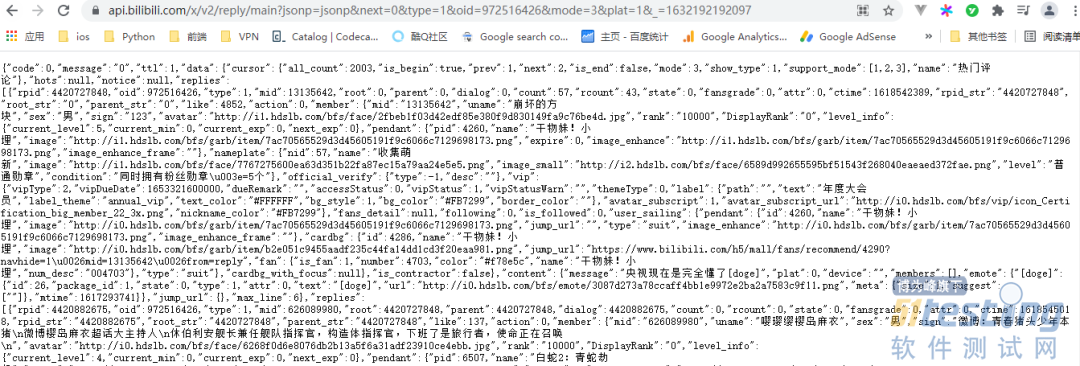
我们先来看看 main 请求,整理后通过浏览器访问如下:
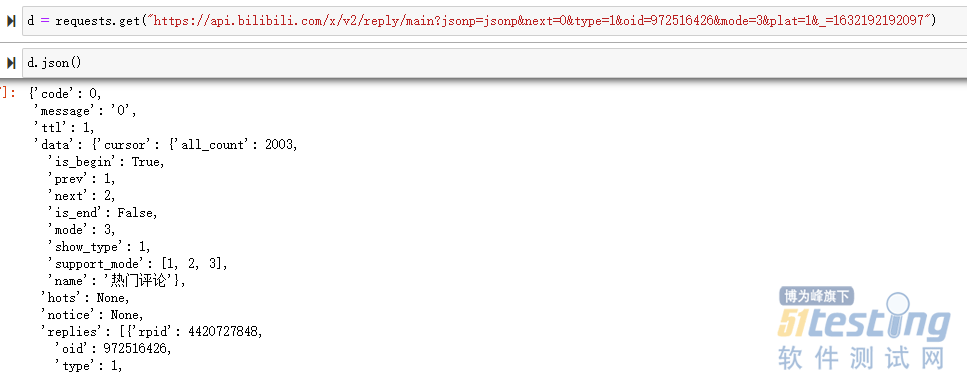
也可以直接通过 requests 请求;
通过观察可以得知,响应消息里的 replies 就是主评论内容,同时我们还可以改变 url 当中的 next 参数来翻页,进而请求不同的数据。
这里我们再关注下 rpid 参数,这个会用于 reply 评论中。
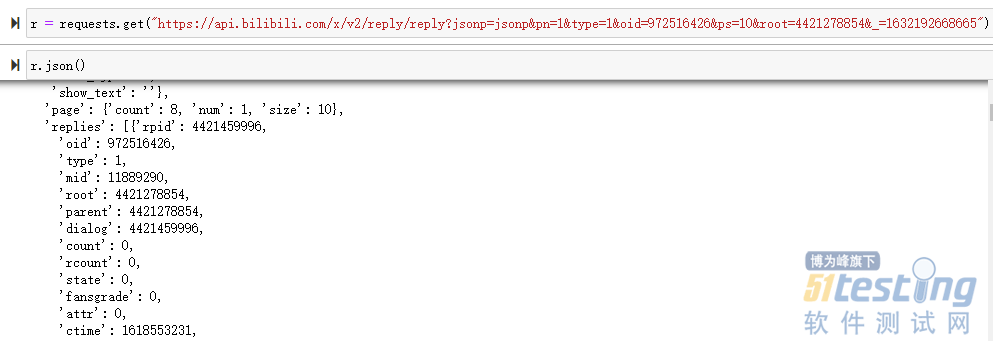
再来看看 reply 评论,同样可以使用 requests 直接访问,同时 url 当中的 root 参数就是我们上面提到的 rpid 参数。
我们厘清了上面的关系之后,我们就可以编写代码了;
def get_data(data):
data_list = []
comment_data_list = data["data"]["replies"]
for i in comment_data_list:
data_list.append([i['rpid'], i['like'], i['member']['uname'], i['member']['level_info']['current_level'], i['content']['message']])
return data_list
def save_data(data_type, data):
if not os.path.exists(data_type + r'_data.csv'):
with open(data_type + r"_data.csv", "a+", encoding='utf-8') as f:
f.write("rpid,点赞数量,用户,等级,评论内容\n")
for i in data:
rpid = i[0]
like_count = i[1]
user = i[2].replace(',', ',')
level = i[3]
content = i[4].replace(',', ',')
row = '{},{},{},{},{}'.format(rpid,like_count,user,level,content)
f.write(row)
f.write('\n')
else:
with open(data_type + r"_data.csv", "a+", encoding='utf-8') as f:
for i in data:
rpid = i[0]
like_count = i[1]
user = i[2].replace(',', ',')
level = i[3]
content = i[4].replace(',', ',')
row = '{},{},{},{},{}'.format(rpid,like_count,user,level,content)
f.write(row)
f.write('\n')
for i in range(1000):
url = "https://api.bilibili.com/x/v2/reply/main?jsnotallow=jsonp&next={}&type=1&oid=972516426&mode=3&plat=1&_=1632192192097".format(str(i))
print(url)
d = requests.get(url)
data = d.json()
if not data['data']['replies']:
break
m_data = get_data(data)
save_data("main", m_data)
for j in m_data:
reply_url = "https://api.bilibili.com/x/v2/reply/reply?jsnotallow=jsonp&pn=1&type=1&oid=972516426&ps=10&root={}&_=1632192668665".format(str(j[0]))
print(reply_url)
r = requests.get(reply_url)
r_data = r.json()
if not r_data['data']['replies']:
break
reply_data = get_data(r_data)
save_data("reply", reply_data)
time.sleep(5)
time.sleep(5)
爬取过程中:
这样,针对一个冰冰视频,我们就完成了上千评论的抓取;
可视化
下面我们简单做一些可视化动作;
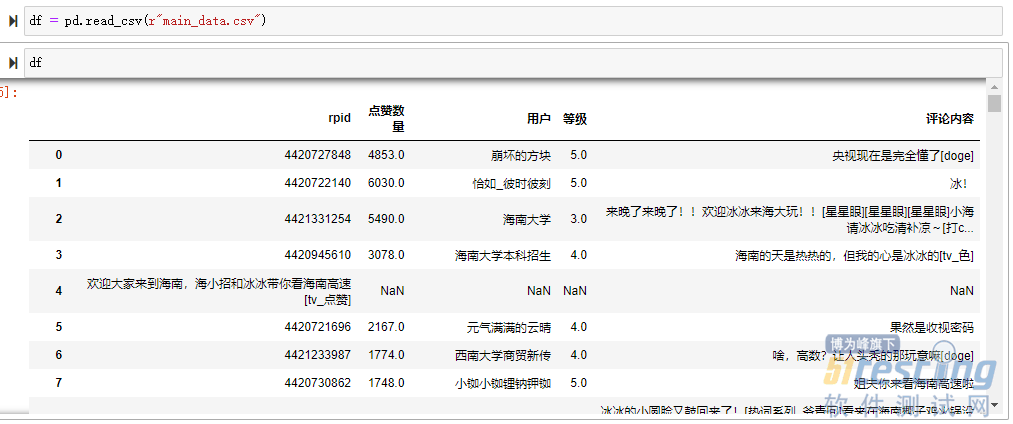
先来看下我们爬取的数据整体的样子:
因为数据中有一些空值,我们来处理下:
df_new = df.dropna(axis=0,subset = ["用户"])
下面就可以作图了,GO!
使用 pyecharts 还是我们的首选,毕竟编写容易
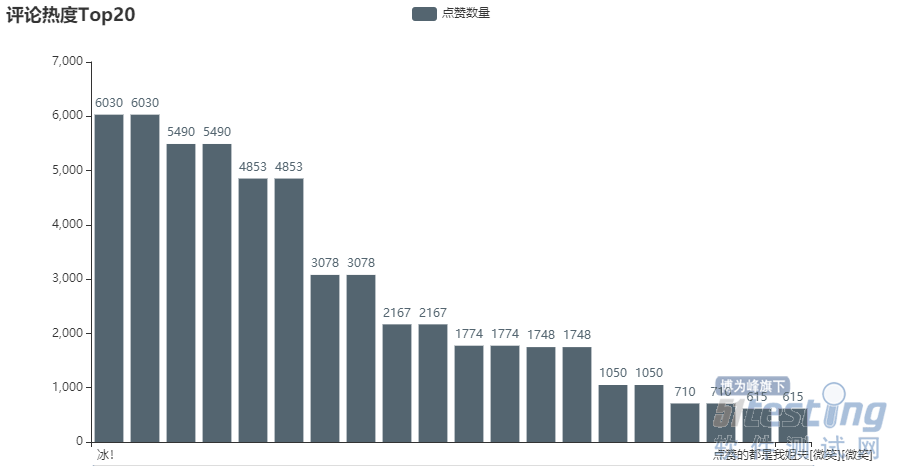
评论热度
df1 = df.sort_values(by="点赞数量",ascending=False).head(20)
c1 = (
Bar()
.add_xaxis(df1["评论内容"].to_list())
.add_yaxis("点赞数量", df1["点赞数量"].to_list(), color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="评论热度Top20"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
.render_notebook()
)
等级分布
pie_data = df_new.等级.value_counts().sort_index(ascending=False)
pie_data.tolist()
c2 = (
Pie()
.add(
"",
[list(z) for z in zip([str(i) for i in range(6, 1, -1)], pie_data.tolist())],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="等级分布"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
评论词云
def wordcloud(data, name, pic=None):
comment = jieba.cut(str(data), cut_all=False)
words = ' '.join(comment)
img = Image.open(pic)
img_array = np.array(img)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file(name + '.png')
wordcloud(df_new["评论内容"], "冰冰", '1.PNG')
好了,今天的分享就到这里,喜欢冰冰就点个在看吧!
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2022-12-27 14:19:58
发表于 2022-12-27 14:19:58







 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务 发表于 2023-1-5 20:49:40
发表于 2023-1-5 20:49:40



 发表于 2023-2-28 10:29:14
发表于 2023-2-28 10:29:14
