TA的每日心情 | 无聊
3 天前 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效。本节中,就让我们来感受一下它的强大之处吧。
1. 准备工作
本节以Chrome为例来讲解Selenium的用法。在开始之前,请确保已经正确安装好了Chrome浏览器并配置好了ChromeDriver。另外,还需要正确安装好Python的Selenium库,详细的安装和配置过程可以参考第1章。
2. 基本使用
准备工作做好之后,首先来大体看一下Selenium有一些怎样的功能。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
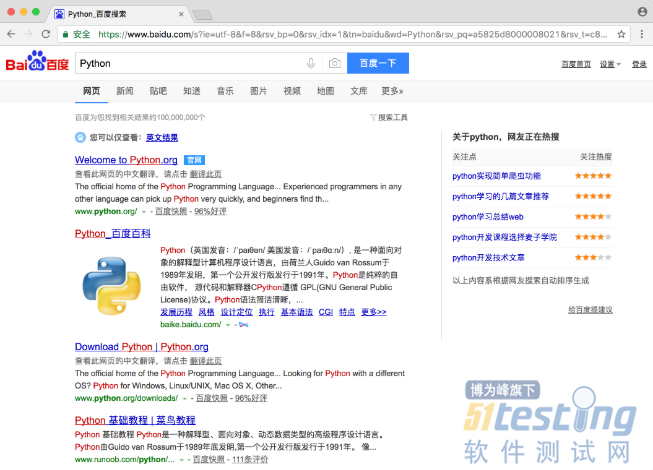
运行代码后发现,会自动弹出一个Chrome浏览器。浏览器首先会跳转到百度,然后在搜索框中输入Python,接着跳转到搜索结果页,如图7-1所示。
可以发现,它的id是q,name也是q。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。比如,find_element_by_name()是根据name值获取,find_element_by_id()是根据id获取。另外,还有根据XPath、CSS选择器等获取的方式。
我们用代码实现一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)
browser.close()
这里我们使用3种方式获取输入框,分别是根据ID、CSS选择器和XPath获取,它们返回的结果完全一致。运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.564956309
6161541-1")>
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.564956309
6161541-1")>
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.564956309
6161541-1")>
可以看到,这3个节点都是WebElement类型,是完全一致的。
这里列出所有获取单个节点的方法:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。我们用代码实现一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()
实际上,这种查找方式的功能和上面列举的查找函数完全一致,不过参数更加灵活。
多个节点
如果查找的目标在网页中只有一个,那么完全可以用find_element()方法。但如果有多个节点,再用find_element()方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用find_elements()这样的方法。注意,在这个方法的名称中,element多了一个s,注意区分。
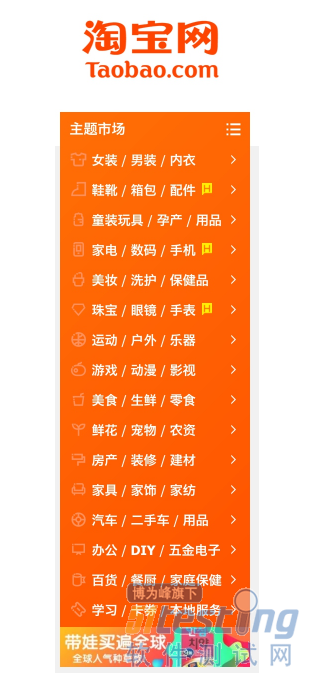
比如,要查找淘宝左侧导航条的所有条目,如图所示。
就可以这样来实现:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()
运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.0922104
4033125603-1")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19",
element="0.09221044033125603-2")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d
96bfab3740d19", element="0.09221044033125603-3")>...<selenium.webdriver.remote.webelement.WebElement
(session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-16")>]
这里简化了输出结果,中间部分省略。
可以看到,得到的内容变成了列表类型,列表中的每个节点都是WebElement类型。
也就是说,如果我们用find_element()方法,只能获取匹配的第一个节点,结果是WebElement类型。如果用find_elements()方法,则结果是列表类型,列表中的每个节点是WebElement类型。
这里列出所有获取多个节点的方法:
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
当然,我们也可以直接用find_elements()方法来选择,这时可以这样写:
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
结果是完全一致的。
6. 节点交互
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()
这里首先驱动浏览器打开淘宝,然后用find_element_by_id()方法获取输入框,然后用send_keys()方法输入iPhone文字,等待一秒后用clear()方法清空输入框,再次调用send_keys()方法输入iPad文字,之后再用find_element_by_class_name()方法获取搜索按钮,最后调用click()方法完成搜索动作。
通过上面的方法,我们就完成了一些常见节点的动作操作,更多的操作可以参见官方文档的交互动作介绍:http://selenium-python.readthedo ... r.remote.webelement。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-6-8 11:54:31
发表于 2023-6-8 11:54:31


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务
 发表于 2023-6-13 09:56:25
发表于 2023-6-13 09:56:25

