TA的每日心情 | 擦汗
昨天 09:05 |
|---|
签到天数: 1048 天 连续签到: 1 天 [LV.10]测试总司令
|
前言
在本篇文章当中主要给大家介绍 python 当中的拷贝问题,话不多说我们直接看代码,你知道下面一些程序片段的输出结果吗?
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
a = [1, 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4]
b = copy.copy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4]
b = copy.deepcopy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
在本篇文章当中我们将对上面的程序进行详细的分析。
Python 对象的内存布局
首先我们介绍一下一个比较好用的关于数据在内存上的逻辑分布的网站,我们在这个网站上运行第一份代码:
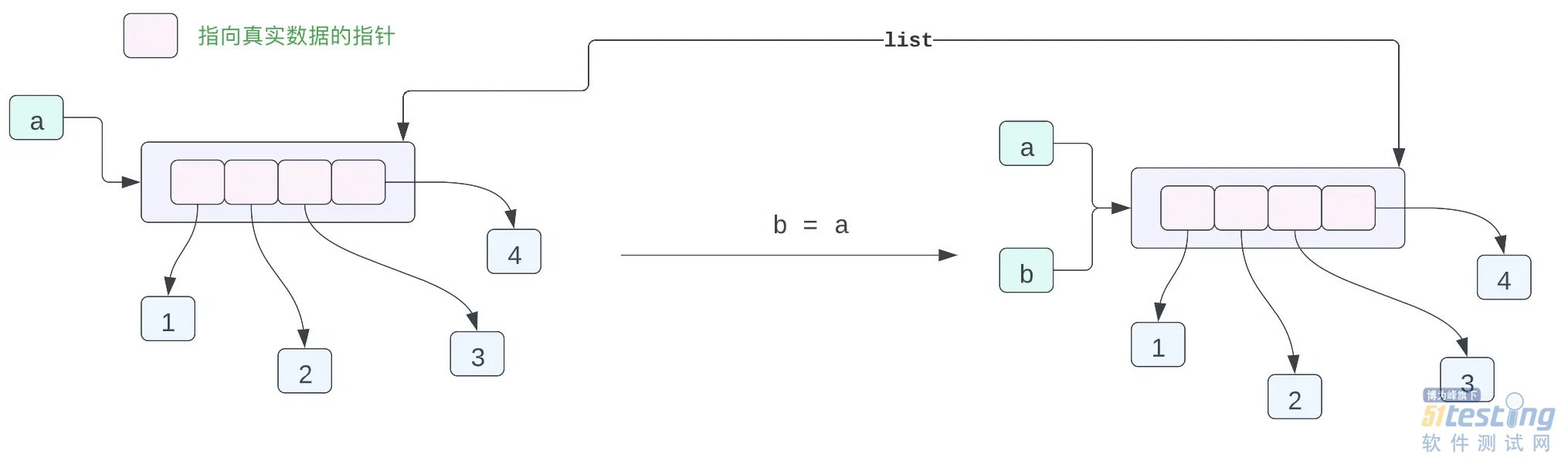
从上面的输出结果来看 a 和 b 指向的是同一个内存当中的数据对象。因此第一份代码的输出结果是相同的。我们应该如何确定一个对象的内存地址呢?在 Python 当中给我们提供了一个内嵌函数 id() 用于得到一个对象的内存地址:
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
print(f"{id(a) = } \t|\t {id(b) = }")
# 输出结果
# a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
# a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
# id(a) = 4393578112 | id(b) = 4393578112
事实上上面的对象内存布局是有一点问题的,或者说是不够准确的,但是也是能够表示出各个对象之间的关系的,我们现在来深入了解一下。在 Cpython 里你可以认为每一个变量都可以认为是一个指针,指向被表示的那个数据,这个指针保存的就是这个 Python 对象的内存地址。
在 Python 当中,实际上列表保存的指向各个 Python 对象的指针,而不是实际的数据,因此上面的一小段代码,可以用如下的图表示对象在内存当中的布局:
变量 a 指向内存当中的列表 [1, 2, 3, 4],列表当中有 4 个数据,这四个数据都是指针,而这四个指针指向内存当中 1,2,3,4 这四个数据。可能你会有疑问,这不是有问题吗?都是整型数据为什么不直接在列表当中存放整型数据,为啥还要加一个指针,再指向这个数据呢?
事实上在 Python 当中,列表当中能够存放任何 Python 对象,比如下面的程序是合法的:
data = [1, {1:2, 3:4}, {'a', 1, 2, 25.0}, (1, 2, 3), "hello world"]
在上面的列表当中第一个到最后一个数据的数据类型为:整型数据,字典,集合,元祖,字符串,现在来看为了实现 Python 的这个特性,指针的特性是不是符合要求呢?每个指针所占用的内存是一样的,因此可以使用一个数组去存储 Python 对象的指针,然后再将这个指针指向真正的 Python 对象!
牛刀小试
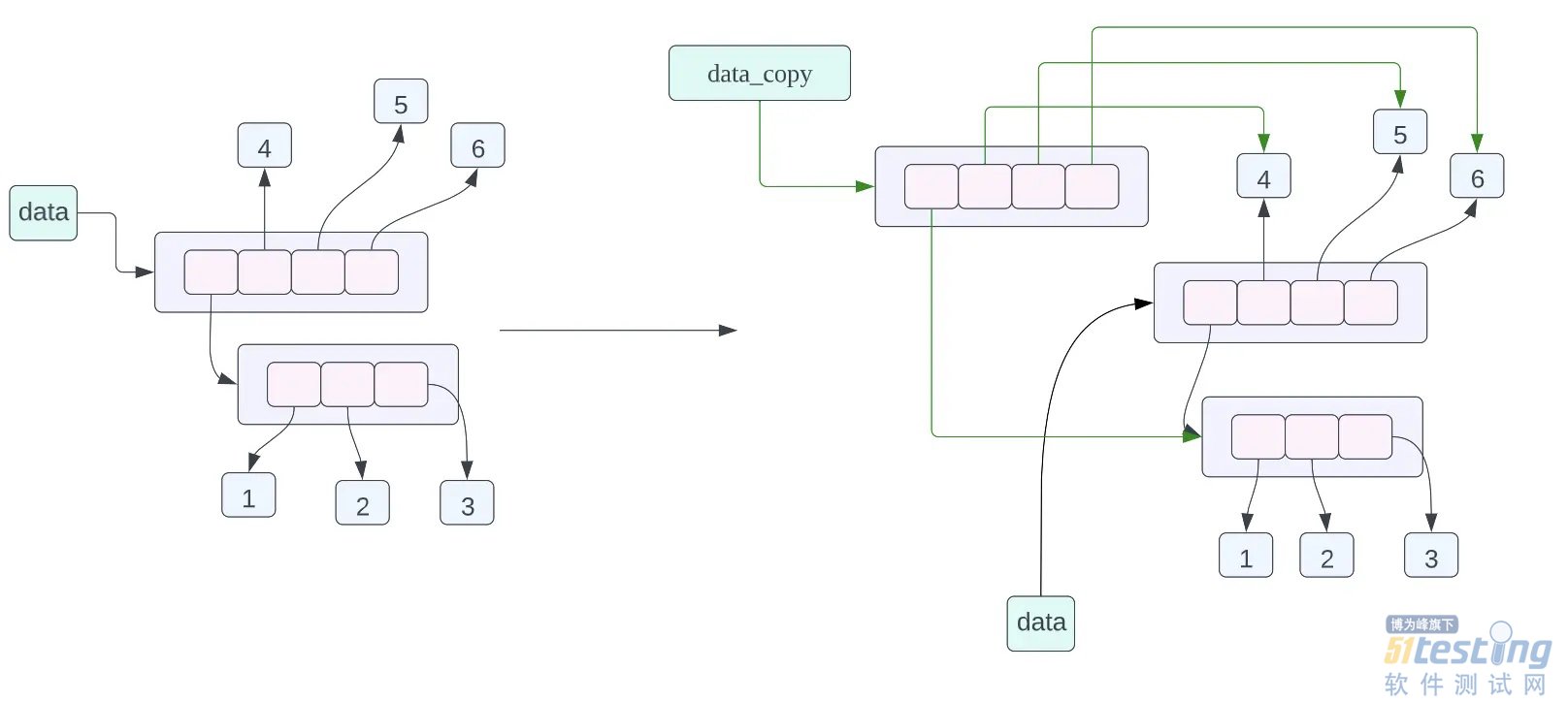
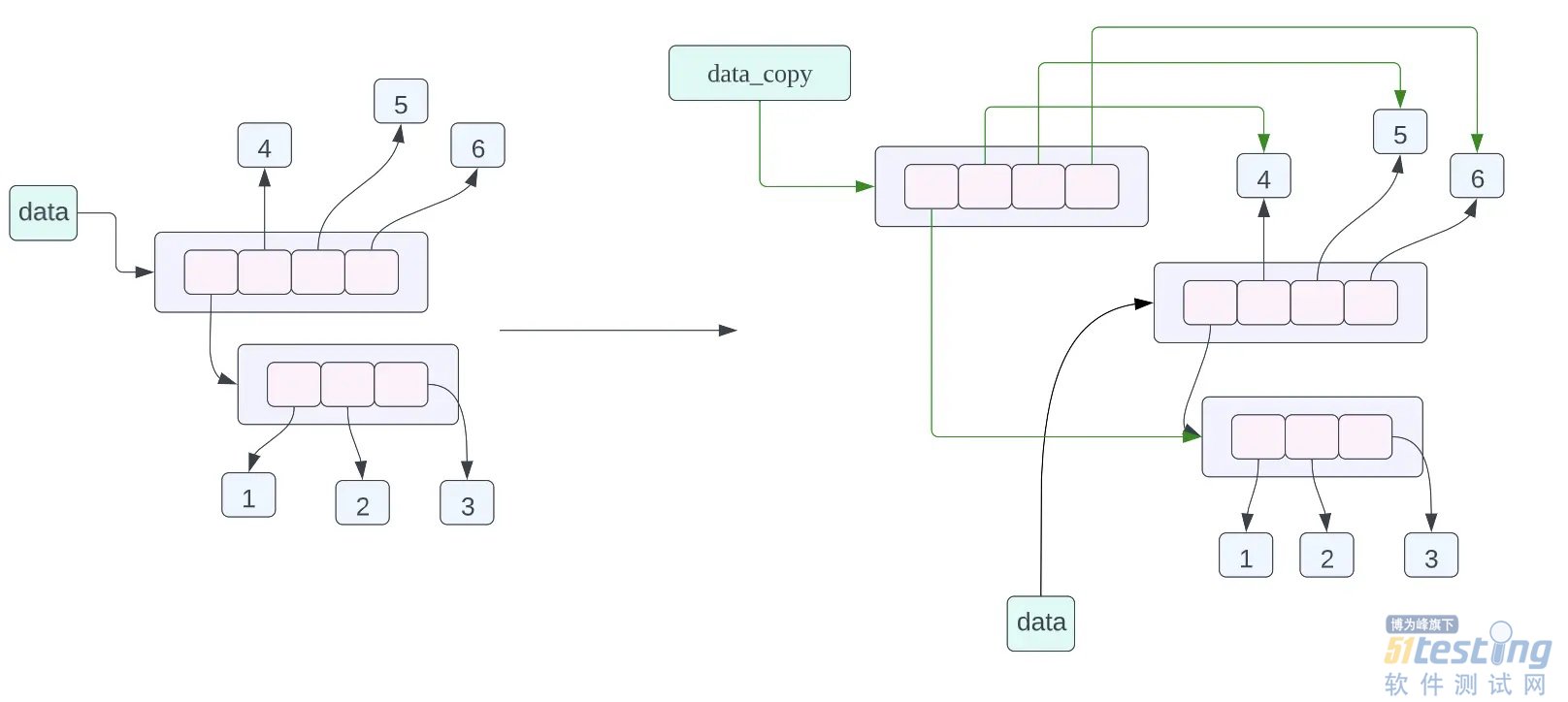
在经过上面的分析之后,我们来看一下下面的代码,他的内存布局是什么情况:
data = [[1, 2, 3], 4, 5, 6]
data_assign = data
data_copy = data.copy()
data_assign = data,关于这个赋值语句的内存布局我们在之前已经谈到过了,不过我们也在复习一下,这个赋值语句的含义就是 data_assign 和 data 指向的数据是同一个数据,也就是同一个列表。
data_copy = data.copy(),这条赋值语句的含义是将 data 指向的数据进行浅拷贝,然后让 data_copy 指向拷贝之后的数据,这里的浅拷贝的意思就是,对列表当中的每一个指针进行拷贝,而不对列表当中指针指向的数据进行拷贝。从上面的对象的内存布局图我们可以看到 data_copy 指向一个新的列表,但是列表当中的指针指向的数据和 data 列表当中的指针指向的数据是一样的,其中 data_copy 使用绿色的箭头进行表示,data 使用黑色的箭头进行表示。
查看对象的内存地址
在前面的文章当中我们主要分析了一下对象的内存布局,在本小节我们使用 python 给我们提供一个非常有效的工具去验证这一点。在 python 当中我们可以使用 id() 去查看对象的内存地址,id(a) 就是查看对象 a 所指向的对象的内存地址。
看下面的程序的输出结果:
a = [1, 2, 3]
b = a
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a) = } {id(b) = }")
根据我们之前的分析,a 和 b 指向的同一块内存,也就说两个变量指向的是同一个 Python 对象,因此上面的多有输出的 id 结果 a 和 b 都是相同的,上面的输出结果如下:
id(a) = 4392953984 id(b) = 4392953984
i = 0 id(a) = 4312613104 id(b) = 4312613104
i = 1 id(a) = 4312613136 id(b) = 4312613136
i = 2 id(a) = 4312613168 id(b) = 4312613168
看一下浅拷贝的内存地址:
a = [[1, 2, 3], 4, 5]
b = a.copy()
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a) = } {id(b) = }")
根据我们在前面的分析,调用列表本身的 copy 方法是对列表进行浅拷贝,只拷贝列表的指针数据,并不拷贝列表当中指针指向的真正的数据,因此如果我们对列表当中的数据进行遍历得到指向的对象的地址的话,列表 a 和列表 b 返回的结果是一样的,但是和上一个例子不同的是 a 和 b 指向的列表的本身的地址是不一样的(因为进行了数据拷贝,可以参照下面浅拷贝的结果进行理解)。
可以结合下面的输出结果和上面的文字进行理解:
id(a) = 4392953984 id(b) = 4393050112 # 两个对象的输出结果不相等
i = 0 id(a) = 4393045632 id(b) = 4393045632 # 指向的是同一个内存对象因此内存地址相等 下同
i = 1 id(a) = 4312613200 id(b) = 4312613200
i = 2 id(a) = 4312613232 id(b) = 4312613232
copy模块
在 python 里面有一个自带的包 copy ,主要是用于对象的拷贝,在这个模块当中主要有两个方法 copy.copy(x) 和 copy.deepcopy()。
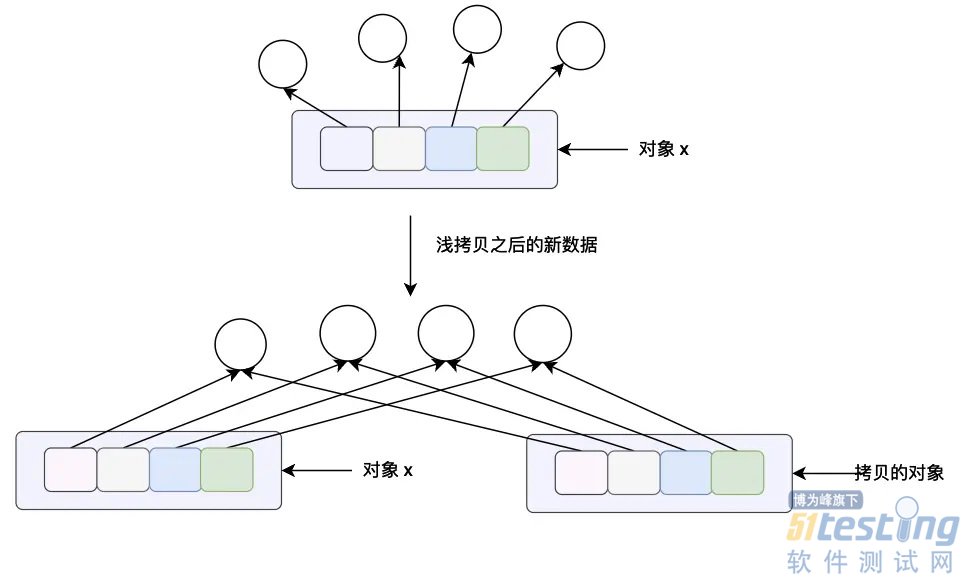
copy.copy(x) 方法主要是用于浅拷贝,这个方法的含义对于列表来说和列表本身的 x.copy() 方法的意义是一样的,都是进行浅拷贝。这个方法会构造一个新的 python 对象并且会将对象 x 当中所有的数据引用(指针)拷贝一份。
copy.deepcopy(x) 这个方法主要是对对象 x 进行深拷贝,这里的深拷贝的含义是会构造一个新的对象,会递归的查看对象 x 当中的每一个对象,如果递归查看的对象是一个不可变对象将不会进行拷贝,如果查看到的对象是可变对象的话,将重新开辟一块内存空间,将原来的在对象 x 当中的数据拷贝的新的内存当中。(关于可变和不可变对象我们将在下一个小节仔细分析)
根据上面的分析我们可以知道深拷贝的花费是比浅拷贝多的,尤其是当一个对象当中有很多子对象的时候,会花费很多时间和内存空间。
对于 python 对象来说进行深拷贝和浅拷贝的区别主要在于复合对象(对象当中有子对象,比如说列表,元祖、类的实例等等)。这一点主要是和下一小节的可变和不可变对象有关系。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2022-12-29 10:16:09
发表于 2022-12-29 10:16:09




 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务