TA的每日心情 | 无聊
13 小时前 |
|---|
签到天数: 1052 天 连续签到: 2 天 [LV.10]测试总司令
|
一、什么是爬虫
爬虫: 一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
从技术层面来说就是:通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
二、Selenium实现爬虫的基本流程
1.分析网页结构
2.连接浏览器
3.打开指定的页面
4.模拟用户行为
5.提取数据
三、环境搭建
所谓工欲善其事必先利其器,所以我们先配置好我们的开发环境。
1.前置条件
· Windows系统
· 已安装Python3
· 已安装pip包管理工具
2.Selenium安装
在cmd命令行中,输入:pip install selenium
1).安装
因为这里已经安装了,所以提示已满足。
2).验证
首先输入python,切换到python命令交互模式,在输入import selenium,如果无报错,则证明已经安装成功。
3.ChromeDriver安装
我们使用Geogle浏览器配合Selenium使用,所以我们需要安装ChromeDriver驱动的配置。
1).安装
首先,我们需要先确认自己浏览器的版本,打开Chrome浏览器->帮助->关于Goolge Chrome(G)
其次,按照自己的Chrome浏览器版本,去找相邻近的ChromeDriver驱动版本;地址:https://npm.taobao.org/mirrors/chromedriver/
点击该目录,然后下载红框标注的版本就行。
下下来之后是一个压缩包,解压缩得到一个exe文件,这个就是我们需要的,我们可以直接放到python安装环境的Scripts目录下,当然也可以放在其他你想放置的目录。
2).验证
因为我直接复制到python安装环境的Scripts目录下了,所以直接输入ChromeDriver,如下提示既没有问题。
然后我们验证是否可以驱动浏览器。
如果弹出一个空白的浏览器既证明配置无问题。
四、示例:爬取国家中小学网络云平台所有视频数据
网页地址:https://tongbu.eduyun.cn/tbkt/tbkthtml/1.html
1. 分析网页结构
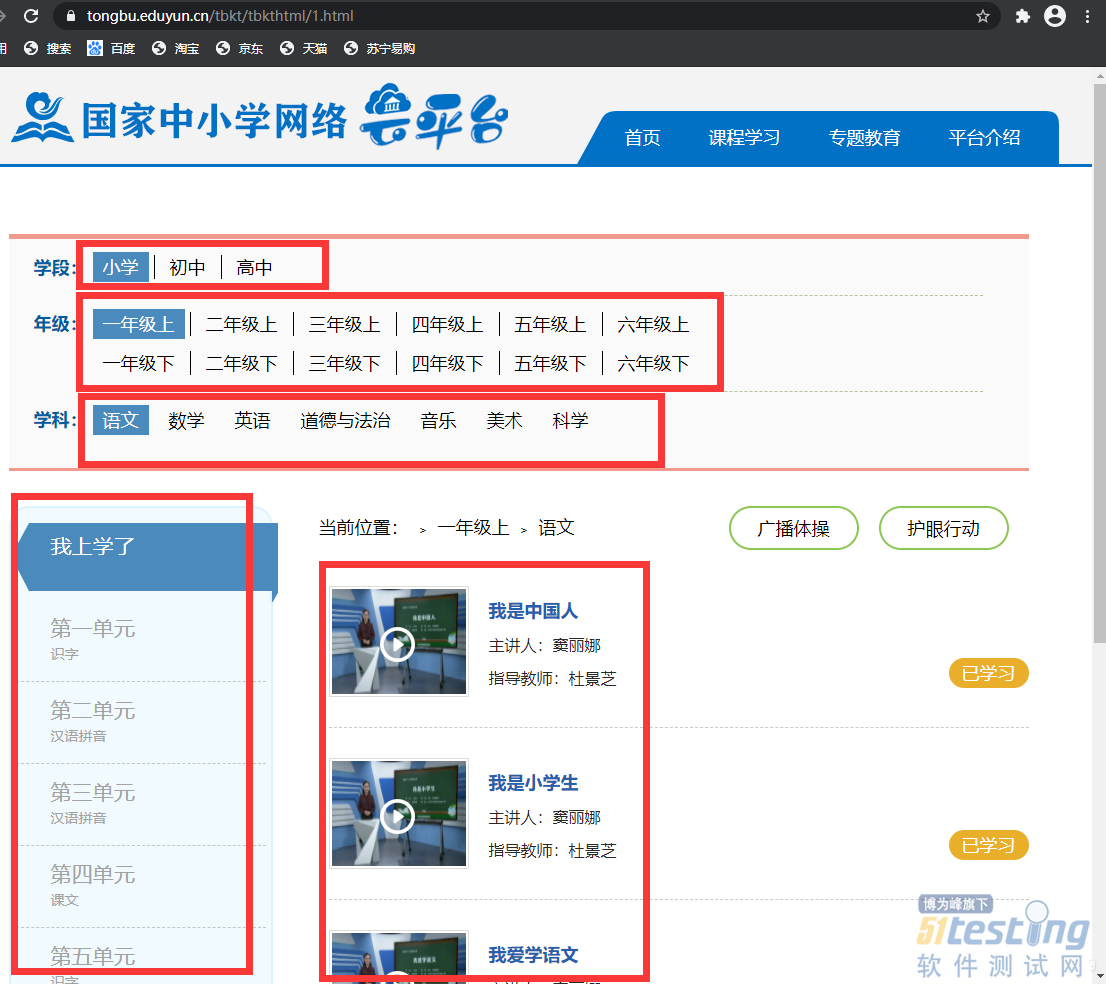
首先我们先看下我们需要爬取的页面的整体架构:
我们发现要得到视频信息,要走好几个环节,首先有个学段,其次年级,再其次就是学科,单元,最后才会得到右下侧的视频列表信息。
然后当我们点击了视频的播放按钮之后,会弹出一个新页面。
这个页面就是我们具体的视频播放页面了,我们需要的视频url也在这里。
2. 连接浏览器
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import presence_of_element_located
import time
import re
import subprocess
import os
# selenium调用
options = webdriver.ChromeOptions()
# 编码格式
options.add_argument('lang=zh_CN.UTF-8')
# 等待浏览器DOMContentLoaded事件
options.page_load_strategy = 'eager'
# 无头模式启动
# options.add_argument('--headless')
# 谷歌文档提到需要加上这个属性来规避bug
options.add_argument('--disable-gpu')
options.add_argument('blink-settings=imagesEnabled=false')
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 10)
|
3. 打开指定的页面
| browser.get("https://tongbu.eduyun.cn/tbkt/tbkthtml/1.html") |
4. 模拟用户行为
此处写了个生成器,主要是数据过多,我想只在需要的时候在获取。
def fibonacci():
# 学段
wait.until(presence_of_element_located((By.ID, "xueduan")))
elements_xd = browser.find_element(By.ID, "xueduan").find_elements(By.TAG_NAME, "dd")
for len_xd in range(len(elements_xd)):
element_xd_a = browser.find_element(By.XPATH, "//dl[@id='xueduan']/dd[{}]".format(len_xd + 1))
element_xd_a_text = element_xd_a.text
print(element_xd_a_text)
element_xd_a.click()
# 年级
wait.until(presence_of_element_located((By.ID, "nianjiDl")))
elements_nj = browser.find_elements(By.XPATH, "//dl[@id='nianjiDl']/dd[@value]")
for len_nj in range(len(elements_nj)):
element_nj_a = browser.find_element(By.XPATH, "//dl[@id='nianjiDl']/dd[@value][{}]".format(len_nj + 1))
element_nj_a_text = element_nj_a.text
print(element_nj_a_text)
element_nj_a.click()
# 学科
wait.until(presence_of_element_located((By.ID, "xuekeDl")))
elements_xk = browser.find_elements(By.XPATH, "//dl[@id='xuekeDl']/dd")
for len_xk in range(len(elements_xk)):
element_xk_a = browser.find_element(By.XPATH, "//dl[@id='xuekeDl']/dd[{}]".format(len_xk + 1))
element_xk_a_text = element_xk_a.text
print(element_xk_a_text)
element_xk_a.click()
# 单元
wait.until(presence_of_element_located((By.ID, "UlDzfw")))
elements_nl = browser.find_elements(By.XPATH, "//ul[@id='UlDzfw']/li")
for len_nl in range(len(elements_nl)):
element_nl_li = browser.find_element(By.XPATH, "//ul[@id='UlDzfw']/li[{}]".format(len_nl + 1))
element_nl_li_a = element_nl_li.find_element(By.XPATH, "h3/a")
element_nl_li_span = element_nl_li.find_element(By.XPATH, "h3/a/span")
element_nl_li_a_text = element_nl_li_a.text
print(element_nl_li_a_text)
print("##{}".format(element_nl_li_span.text))
element_nl_li_a.click()
# 视频列表
wait.until(presence_of_element_located((By.ID, "casel")))
elements_casel = browser.find_elements(By.XPATH, "//div[@id='casel']/dl")
for len_casel in range(len(elements_casel)):
element_casel_li_a = browser.find_element(By.XPATH,
"//div[@id='casel']/dl[{}]/dd/h4/a".format(
len_casel + 1))
element_casel_li_a_text = element_casel_li_a.text
print(element_casel_li_a_text)
# 视频地址
browser.get(element_casel_li_a.get_attribute("href"))
# 具体视频连接在script里面,使用正则表达式获取连接
_script = browser.find_element_by_xpath("//div[@class='ShiPin_C']/script[2]").get_attribute(
"textContent")
# 获取m3u8中的下载连接
searchObj = re.search(r'file:\s*"(.*)?",', _script, re.M | re.I)
browser.back()
yield element_xd_a_text, element_nj_a_text, element_xk_a_text, element_nl_li_a_text, element_casel_li_a_text, searchObj.group(
1)
|
示例:
5. 提取数据
list = fibonacci()
l1 = next(list)
print(l1)
ffmpeg_cmd = 'D:\\ffmpeg-n4.3.1\\bin\\ffmpeg.exe -referer "http://tongbu.eduyun.cn/" -i "{}" -c copy -bsf:a aac_adtstoasc "{}".mp4'.format(
l1[5], l1[4])
print(ffmpeg_cmd)
child = subprocess.Popen(ffmpeg_cmd, cwd=os.getcwd() + "\\", shell=True)
child.wait()
l1 = next(list)
print(l1)
ffmpeg_cmd = 'D:\\ffmpeg-n4.3.1\\bin\\ffmpeg.exe -referer "http://tongbu.eduyun.cn/" -i "{}" -c copy -bsf:a aac_adtstoasc "{}".mp4'.format(
l1[5], l1[4])
print(ffmpeg_cmd)
child = subprocess.Popen(ffmpeg_cmd, cwd=os.getcwd() + "\\", shell=True)
child.wait()
browser.quit()
|
因为数据很多,所以这里只提取了两个视频信息。下载使用的是ffmpeg,你可以使用python写代码下载也行,这里只是为了简便。
注意:
1)视频url是m3u8的。
2)某些视频需要设置请求头referer为http://tongbu.eduyun.cn/,不然获取不到视频。
总结
使用Selenium爬取网页数据,我们可以模拟正常用户的行为,就和人在点击是一致的。
这种方式为某些需要点击触发啊之类的数据请求提供了一个方便,不过selenium最主要的作用还是用作自动测试化。
我们要爬取任何网页的数据,首先需要做的都是分析网页结构,分析网页链接等等,比如某些视频的权限之类的,这样才能游刃有余。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2021-5-11 10:03:07
发表于 2021-5-11 10:03:07












 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务