只需一步,快速开始
微信登录,快人一步
手机号码,快捷登录
签到天数: 1050 天
连续签到: 1 天
[LV.10]测试总司令
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
查看 »
小黑屋|手机版|Archiver|51Testing软件测试网 ( 沪ICP备05003035号 ) 关于我们
GMT+8, 2024-11-26 03:08 , Processed in 0.062601 second(s), 23 queries .
Powered by Discuz! X3.2
© 2001-2024 Comsenz Inc.








 /1
/1 

 关于我们
关于我们






 发表于 2023-5-19 11:03:31
发表于 2023-5-19 11:03:31




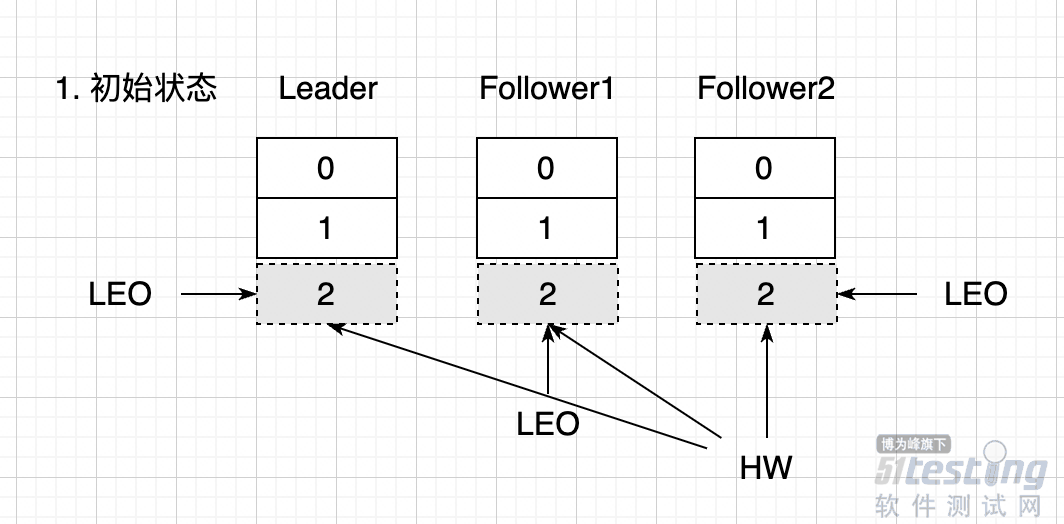

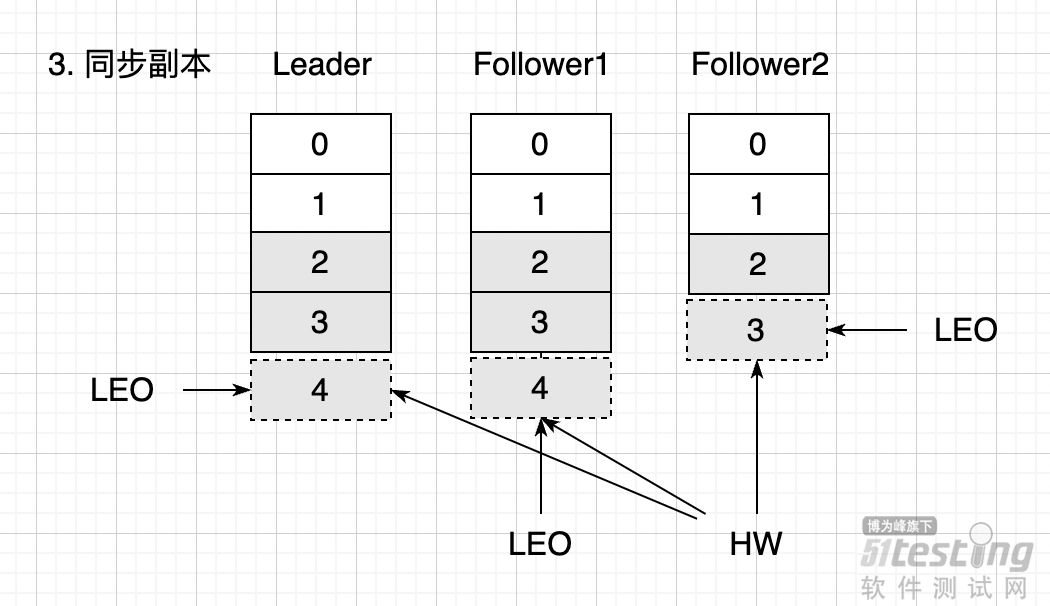
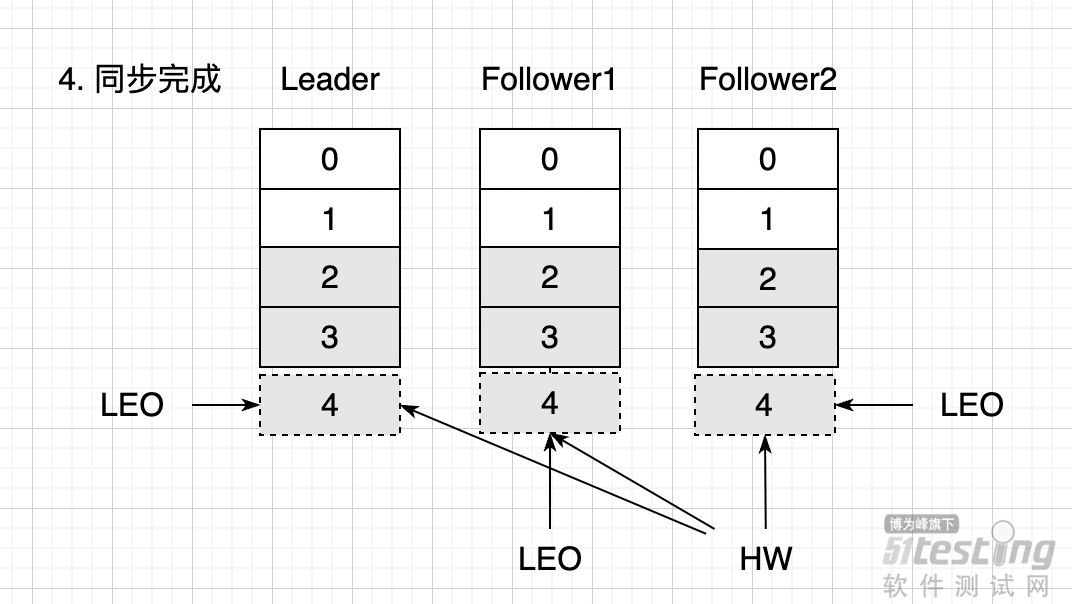

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务