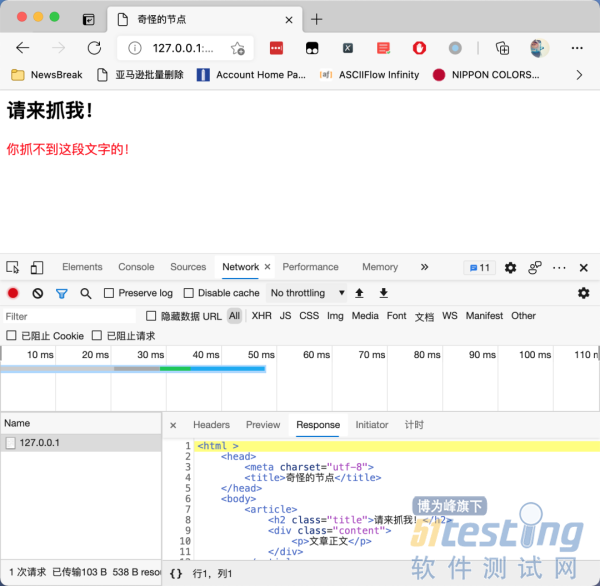
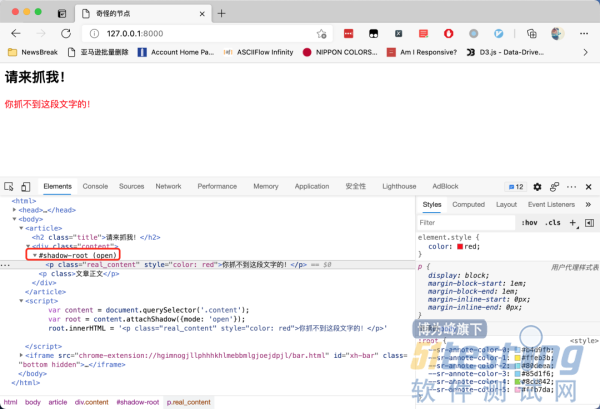
因为这个节点是一个shadow DOM[1]。shadow DOM 的行为跟 iframe很像,都是把一段HTML 信息嵌入到另一个 HTML 中。但不同的是,iframe被嵌入的地址需要额外再搭建一个 HTTP服务,而 shadow DOM 可以只嵌入一段 HTML 代码,所以它比 iframe 更节省资源。
在上面的截图中,通过下面这三行代码,我们把一个新的标签嵌入到了原来的 HTML 中:
var content = document.querySelector('.content');
var root = content.attachShadow({mode: 'open'});
root.innerHTML = '<p class="real_content" style="color: red">你抓不到这段文字的!</p>'








 /1
/1 

 关于我们
关于我们






 发表于 2021-5-11 09:59:28
发表于 2021-5-11 09:59:28






 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务