|
|
2#

楼主 |
发表于 2007-11-21 16:51:35
|
只看该作者
三、试用准备
1.简化JDBC函数
为了方便开发人员的使用,作者提炼出以下简化后的常用JDBC函数:
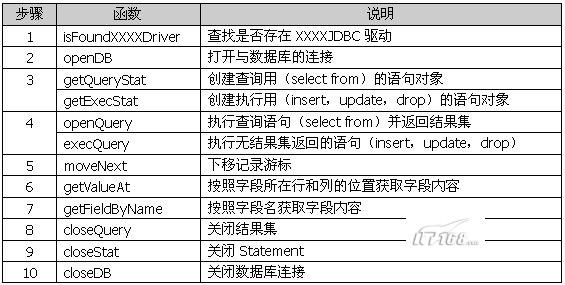
这些函数基本上已经满足大部分的使用,初级开发人员按照函数的调用步骤就可以实现通过JDBC驱动与各种数据库平台进行交互了。
如果用户对数据库操作的效率比较关注,那么还有3组比较重要的,也是常用的JDBC函数,分别是:
(1)事务处理函数:setAutoCommit/commit/rollback
(2)批处理函数:addBatch/execBatch
(3)语句预处理函数:prepareStatement
对于大多数开发人员,只需要知道其用法含义即可,深层次的探索和分析可能需要另外的篇幅来说明,因此作者在此不再赘述。
实际上,上述基本函数的定义,大部分都是对JDK中JDBC函数的封装,读者也可以通过JDBC的文档进行相关的查阅。关键代码参见全文末尾附录部分。
2.数据库表定义
作为试用,作者并没有定义很复杂的数据库表,以下是测试用数据表结构:
create table user_info(
ui_id varchar(64),
ui_passwd varchar(64),
ui_real_name varchar(64), primary key(ui_id));
3.试用思路
比较简单,就是通过上述不同类型的JDBC驱动来连接各种数据库平台,然后向已经初始化的数据表插入10000条记录,再逐条读取,并记录其各个步骤的执行耗费。
四、试用过程
1.平台选择
作者选择了MS Windows XP和Solaris两种平台。其中只有MySQL,JavaDB和Oracle(连接远程服务器)既可在Windows平台进行了测试,也可在Solaris平台下进行了测试。两个系统下的测试代码和框架完全相同。
2.使用JDBC驱动连接数据库
(1)Access数据库
通过JDBC驱动连接Access数据库最常用的是采用建立ODBC数据源(DSN)的方式进行,但是本测试中采用的是通过数据库连接字符串避开了手工建立DSN的部分。以下是关键代码:
final String connectStr =
“jdbc dbc:driver={Microsoft Access Driver (*.mdb)};DBQ=./TestDB.mdb”; dbc:driver={Microsoft Access Driver (*.mdb)};DBQ=./TestDB.mdb”;
……
if( (conn = FoolDB.openDB(connectStr, null, null)) == null)
用过ADO的读者可能一眼就看出来了,上述的连接字符串中的内容和ADO很相似。事实上,作者就是为了避开建立DNS而尝试套用了ADO的连接字符串,结果尝试通过了!
(2)SQL Server数据库
需要说明的,对于SQL Server的测试没有采用Microsoft提供的SQL Server专用的JDBC驱动,还是通过借鉴ADO的连接字符串形式,沿用了JDK自带的JdbcOdbc驱动。
final String connectStr =“jdbcdbc river={SQL Server};Server=.;Database=master;UID=sa river={SQL Server};Server=.;Database=master;UID=sa WD=121fs”;……if( (conn = FoolDB.openDB(connectStr, null, null)) == WD=121fs”;……if( (conn = FoolDB.openDB(connectStr, null, null)) ==
null)
注意:用户名和密码已经包含到连接字符串中。
SUN公司提供的SQL Server的JDBC驱动的版本应该比较陈旧,所以可能导致在操作数据库功能支持和效率方面比当前新的JDBC驱动要差一些。Microsoft提供的SQL Server JDBC驱动类名为:“com.microsoft.jdbc.sqlserver.SQLServerDriver”,连接字符串形如:“jdbc:microsoft:sqlserver://hostname:port;DataBaseName=dbname”。
(3)MySQL数据库
众所周知,MySQL数据库既可以在Windows可以在Solaris平台运行,而且执行效率也深得业界的好评。本试例中连接MySQL使用的是MySQL专用驱动(在第一部分已经详述,在MySQL官方网页有很多的支持文档),以下是关键代码:
final String connectStr = “jdbc:mysql://localhost/phome”;
final String userName = “root”; //
final String passwd = ““;……if( (conn = FoolDB.openDB(connectStr, userName, passwd)) ==
null)
在本地连接时,主机名可以使用“localhost”,但如果连接远程主机时,必须换成该远程主机的IP,而phome是MySQL数据库名称。
(4)Oracle数据库
Oracle提供了thin和oci两种类型的驱动,本测试中使用thin类型JDBC驱动。
final String connectStr = “jdbcracle:thin WBS:1521/oracle088”;final String userName = “test”;final String passwd = “test”; WBS:1521/oracle088”;final String userName = “test”;final String passwd = “test”;
其中“WBS:1521/oracle088”为Oracle服务器的SID。
(5)Java DB
值得一提的,Java DB是由Apache Software Foundation主要参与开发的一个数据库(DB)项目,SUN在JDK1.6.0中将其进行了绑定,它是一款名副其实的纯Java代码开发的数据库平台。可以支持Server/Client也可以支持嵌入式运行模式,本实例中主要采用了嵌入式模式(Embedded)进行操作:
final String connectStr = “jdbc:derby:FoolDB”;……if( (conn = FoolDB.openDB(connectStr, null, null)) ==
null)
其中FoolDB是在初始化过程中,使用连接字符串“jdbc:derby:FoolDB;create=true”进行创建的。创建的结果是:在当前目录中创建一个名为FoolDB的目录,该目录又中包含log,seg0和tmp这3个文件夹,而数据库内容以多文件的方式存放于seg0目录中。
注意:数据库一旦创建之后,就无需再次创建了。
3.设置数据库事务方式
当数据库连接成功之后,需要设定连接的事务方式(前提是该数据库平台支持事务处理)为非自动提交,因为JDBC函数默认为自动提交。
提交过于频繁,就会使数据库操作的效率较低。特别是对于Oracle这种绝对支持事务处理的数据平台而言,设置是否自动提交对系统的效率将有很大的影响。
4.采用批处理方式插入记录
同样一个考虑效率的操作,循环地执行操作语句(Insert,Update)也会增加很多不必要地开销。试例中采用了批量处理的方式,通过这种方式将要进行的操作先进行汇总,再批量提交执行。这样就可以获得较高的执行效率。
//Insert records
for(int i =
0; i < RECORD_COUNT; ++i){//Add each operation to batch
if(FoolDB.addBatch(execStat, “insert into user_info values('guest”
+ Integer.toString(i +
1)+ “', '666666', '我是中国人')”) == false)
……FoolDB.execBatch(execStat); //Execute batch operations
FoolDB.commit(conn);FoolDB.setAutoCommit(conn, true);
这种批处理的方式,可以视同预处理,通过统合批量的操作来减少与数据库的交互频率,也减少数据库访问IO设备的频率,从而也可获得较高的效率。
5.使用行游标读取记录字段
记录插入完毕之后,通过执行查询语句来获取数据集。然后再通过简化函数moveNext来逐行读取结果集的记录行:
//Select from table
String sql =
"select * from user_info";if( (queryRS = FoolDB.openQuery(queryStat, sql)) ==
null){…}…while(FoolDB.moveNext(queryRS) ==
true){//Field ui_id, text(64) type
FoolDB.getFieldByName(queryRS, “ui_id”);//Field ui_passwd, text(64) type
FoolDB.getFieldByName(queryRS, “ui_passwd”);//Field ui_real_name, text(64) type
FoolDB.getFieldByName(queryRS, “ui_real_name”);}
实际上,moveNext的函数名也来源于ADO(在作者看来,JDBC和ADO的应用方式是相同的)。
6.关闭数据库
这里主要对以嵌入式模式运行的JavaDB的关闭进行说明,其他数据库的关闭,直接采用简化后的关闭函数(closeDB)即可。
在嵌入式模式,应用程序退出时就必须关闭数据库。但是如果应用程序关闭数据库失败,当JVM退出时不会对该未被关闭的连接进行检查,这样就占用了数据库的连接资源,就会影响后续的连接执行效率。所以Apache Derby的建议是采用URL的方式显示地关闭数据库。以下是关键代码:
FoolDB.closeDB(conn); //Close connection
if(framework.equals("embedded") ==
true) //If in embedded mode
{//Use URL to shutdown Derby
if(FoolDB.openDB("jdbc:derby:;shutdown=true", null, null) ==
null){//If shutdown failure means that Derby already shutdown
isShutdownOk =
true;}if (isShutdownOk ==
false) //Not shutdown normally
{System.out.println("Derby shutdown NG.");}}
注意:关闭和判断Derby数据库是否正常关闭的连接字符串中是不包含数据库名的。
7.记录各步骤操作的时间戳
以上的操作中,在各个步骤之间添加了时间戳,以此来记录各个数据库平台的执行耗费。
五、结果及分析
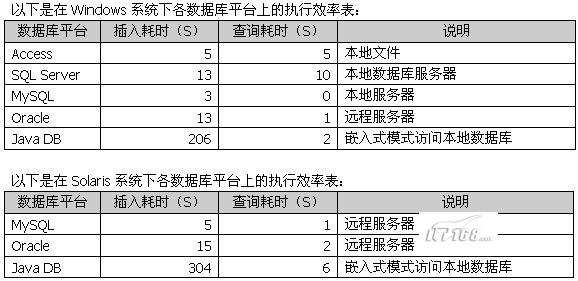
在对试用结果进行评价之前,读者需要考虑各款数据库平台的特点,而不能简单地从执行时间的长短来进行判断,以下是笔者根据开发经验总结出的需要注意的地方:
(1)要保证JDBC驱动和数据库平台的连接是无缝的。例如Oracle和JavaDB数据库本身就是由Java开发,其JDBC驱动和数据库平台的连接可以做到完全无缝,这样可以充分体现出该款数据库平台的特性。反之,Access和SQL Server与对应的JdbcOdbc驱动之间的耦合可能就不如与ADO驱动那么吻合,那么这些数据平台的很多特性就无法通过这些JDBC驱动得以体现。之前我们也提到,Microsoft专门有提供MS SQL Server的JDBC驱动,数据库与这种“对口”的JDBC驱动的耦合肯定要超过JdbcOdbc这种通用型的驱动。
(2)数据库平台要有良好的可移植性。换句话说就是数据库跨操作系统的性能。在这些方面Oracle,MySQL和JavaDB就要比Access和SQL Server有明显优势,它们不仅可以支持Windows平台而且也支持Solaris和Linux平台。而且数据库平台的可移植很大程度也决定了应用系统的可移植性。
(3)数据库平台要支持应用的多样化(需求弹性)。数据库平台应该不仅可以对应传统的C/S,B/S模式,而且还可以扩展为三层的,甚至是多层的模式,或者支持嵌入式系统的应用。显而易见,本身使用Java开发的Oracle和JavaDB在这些方面就具有得天独厚的优势。而且JavaDB还支持嵌入式应用,这样以来数据库的应用空间就更为广阔了。
所以基于以上几点的考虑,我们就可以得出初步的意向:
(1)对于一般的中小型的C/S和B/S架构,MySQL可以说是我们当前首选。它在跨平台和执行效率方面表现得相当的出色。
(2)对于那些对系统构架弹性要求比较高的系统,可以选择Oracle平台,并结合EJB规范进行搭建系统构架无疑将是很好的选择。
(3)选用JavaDB进行嵌入式平台开发似乎是不错的主意。由于现在很多嵌入式设备中都嵌入了Java内核,JavaDB也就可以得以应用了,嵌入式设备与其他系统共享数据的接口就变得及其简单。
(4)如果只在Windows平台进行开发的中小型系统,用Access或者SQL Server平台也不妨是一种简单快捷的途径。 |
|








 /1
/1 

 关于我们
关于我们





 发表于 2007-11-21 16:50:05
发表于 2007-11-21 16:50:05


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务


