|
本文向您介绍如何通过最少的工作优化 WebSphere Application Server V6 以获得最大的性能改善。它侧重于使用 wsadmin 和 Jython 进行命令行优化,而不是使用 GUI 技术。通过应用一些根据经验获得的方法,能够通过最少的管理工作使 WebSphere Application Server 最佳地利用可用的硬件资源。这里描述的技术适用于任何性能优化问题——只有某些特定经验方法是特定于 WebSphere 的。 引言 如果您是这样一个人:启动并运行 WebSphere Application Server 后就忙着处理其他事情,而没有时间研究与性能优化相关的文档(请参阅参考资料)。那么,您来对地方了——本文旨在帮助您确定可能带给您 80% 性能改善的 20% 的性能更新。本文重点介绍 WebSphere Application Server base 产品——下一篇文章将介绍 WebSphere Application Server Network Deployment。 应用程序基础设施中的优化带来的性能改善不能与修复编得很差的应用程序所获得的显著性能改善同日而语。 一些应用程序在其数据库查询中没有 where 子句;一些应用程序调用了 wait() forever;一些应用程序构建了死锁生成器;一些应用程序拥有庞大的 HTTPSession;一些应用程序执行了 select * 并试图将所有数据缓存到中间层中(有千兆的数据也那么干!)。本文将向您介绍一些很好的优化技巧,但只有应用程序本身可以带来真正显著的结果。是的,这意味着应用程序开发人员和服务器管理员必须定期相互沟通! 性能测试环境 找出薄弱环节 您需要一个尽可能反映生产环境的测试环境。如果您使用的是几千兆的数据仓库,则测试系统可能需要小一些。但是性能和生产环境之间的任何差异都可能引起高开销的推断错误。大型企业没有任何理由宣称它们无法提供同等规模的性能测试服务器。小测试环境可能无法暴露某些方面(例如锁操作、日志记录、HTTPSessions、垃圾回收、连接池、CPU、内存、数据库、网络或应用程序)现有的问题。 测试工具——找准方向 创建实际测试工具是有效优化的关键步骤。如果您在测试服务器上施加的工作负载无法反映出站点中实际发生的情况,则您的优化将无法解决问题!有很多开放源代码的软件测试产品和商业软件测试产品(请参阅下面的参考资料)。您可以通过查看现有的服务器日志来了解实际测试场景。当引入新的应用程序时,这些历史记录对您是没有帮助的,所以必须有最好的设想。 测试工具——打破极限 优化旨在发现问题并修复它们。如果测试没有使服务器负载达到临界点,则有些问题将检测不到,所以要确保服务器的负载超过您预期的最高峰流量。这样做将使您获得测试工具定义中的误差幅度。优化最差情况下的负载,这样您在投入生产时就已经拥有更高负载下的性能值。于是,您将知道您的安全幅度有多大以及什么时候需要为非常流行的应用程序进行扩容。应用程序的创建者不应该开发测试工具,因为他们知道假定的边界条件,会有意避免创建超出这些边界的测试用例。生产工作负载可没有这么友善! 一些测试提供的用户数是适度增长的,从而生成相当线性化的性能曲线图。但是实际的用户到达率往往是集群化且不规则的,所以在投入生产环境之前需要对这些条件进行测试。 如果您的测试计算机上有其他用户,则他们必须知道您的测试计划——否则他们可能认为他们遭遇某种严重的问题,例如拒绝服务攻击。 本文所使用的测试环境 本文中的结果来自 IBM 培训计划,它使用 WebSphere Trade6 内部基准来训练学员在高压竞争环境下进行性能优化。该测试环境使用 Red Hat Enterprise Linux V3、WebSphere Application Server V6.0.1、DB2 V8.2 和 Apache JMeter。这些产品将安装在 VMWare V5.0 下。两台 IBM ThinkPad 便携式计算机使用以太网交叉电缆相连接。应用服务器运行在一台计算机上,而测试工具和数据库运行在另一台计算机上。
为了简化性能优化环境和降低出现错误的可能性,您应该使用 shell 脚本来启动不同的组件。下面的清单 1 显示了一个名为 go_trade6 的示例脚本。该脚本从端到端启动基准,包括 WebSphere Application Server、DB2 服务器、JMeter 程序和用于监控 top 和 vmstat 的 xterm。 清单 1. 启动测试环境所有组件的脚本 | xterm -exec top &xterm -exec vmstat 3 &su - -c db2start db2inst1#su - -c oninit informix startWASmozilla &# start test harnesscd /root/trade6/jakarta-jmeter-2.0.2/bin/opt/IBMJava2-141/bin/java ApacheJMeter.jar -t tradebuysell.jmx &# read wastecpu.c wastecpu & wastecpu & export PATH=$PATH:/opt/IBM/WebSphere/AppServer/bin |
环境卫生 获得性能基准数 在进行任何更改之前,获得性能基准数是很重要的,因为只有与基准进行比较才能确切说明系统变快还是变慢。在运行基准测试或其他性能测试时,必须谨慎地控制系统上的其他工作。例如,如果您的数据库用于事务处理和繁重的决策支持 (DSS) 查询,则可以确定非预定的 DSS 查询将牺牲您的事务性能。如果您在不知道 DSS 会有干扰时试图优化此环境,则将错误地得出结论:系统的性能“已优化,但不可预测”。实验示例的性能基准(使用 JMeter)如下面的图 1 所示。可以通过 Run 菜单下拉列表启动一项测试或清除先前的所有数据以进行下一次测试。 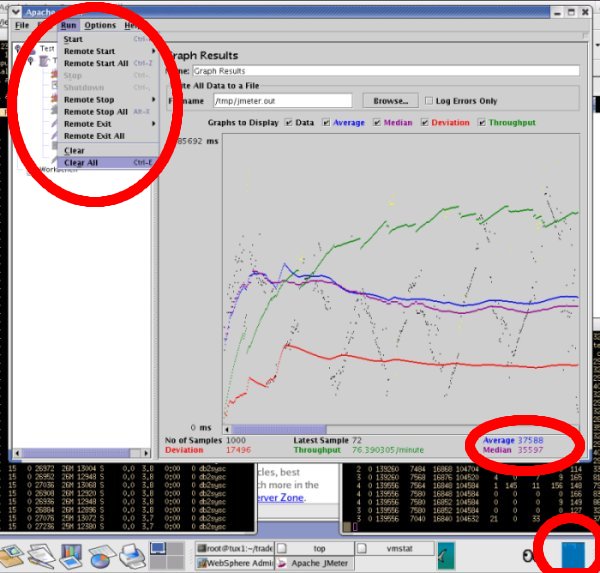
图 1. 使用 JMeter 的性能基准:37 毫秒响应时间 基准性能表明平均响应时间为 37.6 毫秒(请看 JMeter 帧的右下角)。您可以对不同的度量进行优化,例如吞吐量、中值响应时间、响应时间偏差或其他某种优化目标。首先确定优化目标,然后弄清楚如何优化系统才能实现此目标。 如果工作负载很大而且系统优化不好,则需要花很长时间才能获得基准性能值。您可以使用小型测试工具来缩短一些早期测试的时间,还可以获得系统输出的详细信息。确保数千次点击的次秒级响应不会只是应用程序错误页面的详尽测试。JMeter 提供测试活动日志。您可以定义一个文件(例如 /tmp/jmeter.out)来包含 HTTP 请求响应活动的返回代码。 在下面的下载部分,您将发现 JMeter 的两个不同的测试文件。一个是完全测试,另一个标为“Small”。Small 测试也启用了输出收集功能,以便您可以看到请求-响应的结果。在实验测试中,计算机是完全满负荷的——图 1 右下角的蓝色实框表示 100% 的 CPU 使用率。图形指示器和运行 top 命令的 xtermBoth 都指示 CPU 使用率的问题。查明什么占用了 CPU 时间需要费些周折。 没有足够的 CPU 和内存,服务器(WebSphere Application Server 或其他任何服务器)将不能很好地运行。如果您在没有空闲 CPU 时或者在操作系统需要交换虚拟内存的地方试图优化服务器,则无法使其变得很快。下一部分将描述如何检测 CPU 或内存受限的系统以及如何修复它们。 优化日志 一些优化更改将使系统运行得更快,而一些将使之运行得更慢。记录您做了什么更改以及为什么这样更改将使优化过程更简单也更顺利。下面是一个非常简单的配置日志——格式不是很重要,只要您每次记录一些关键数据点即可。一个好的过程是将更改作为注释放在配置文件中。 示例优化日志条目 | DateTime:_____________ Name:____________Parameter Changed_____________Why?_____________________How?________________New Performance___________millisecondsKeep____________ Remove_____________ How?_____ |
CPU 使用率 在进行任何优化前,系统必须有可用的 CPU 周期。任何在服务器上运行的不是很有用的程序都应该停止或禁用——包括在服务器上运行的漂亮屏幕保护程序!检测 CPU 受限的系统的最佳方式是运行 top 命令——它是 Linux/Unix 性能工具的“瑞士军刀”:
图 2. top 命令 在右上角,“idle”处于 0.0%,所以我们知道计算机已竭尽全力在运行。“COMMAND”栏中的进程列表显示占用最多 CPU 周期的两个程序称为 wastecpu。如果您阅读清单 2 中的注释,您会发现可以将 wastecpu 杀死。 清单 2. wastecpu 源代码 | /* if you read this comment before you killed "wastecpu" you did good!Wastecpu is meant to simulate a "production application" and the purpose is to train people not to kill ANYTHING without knowing what it does.*/#include <stdio.h>main(){int i;for (i=0;i<1;i=0){/* wow, what a useful program */i=0;}} /* end of main */ |
在运行 top 命令时,要杀死这些模拟的 CPU 贪吃户,请按 K 键,top 将询问您要杀死什么进程。输入进程 id (PID)(在本例中为 2441),然后 top 将停止此程序。再次执行此操作来杀死第二个副本 PID 2442。要避免以后还要处理 wastecpu 程序,请在 go_trade6 脚本中将其注释掉。 在一些生产环境中,发生问题时除了“抛弃硬件”外别无他法。有许多选择可以进行纵向和横向扩展。图 3 阐释了用于在实验环境中添加另一个处理器的配置。交叉电缆在学员小组(高度竞争的学员的一个重要特征)之间提供“气隙 (Air Gap)”安全性。 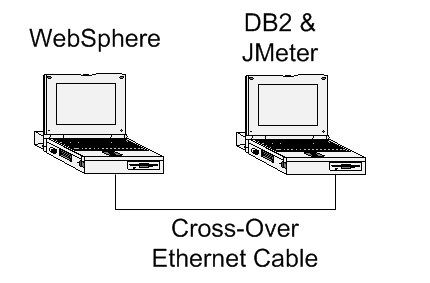
图 3. 测试实验中两台 ThinkPad 的 Trade 6 配置 内存使用率 在有足够内存时,WebSphere Application Server 执行得最好。您可以通过 top 命令查看内存使用率。“交换”域应该为零——如果不是,则操作系统正在通过磁盘空间模拟有更多的 RAM 的情况,这当然是一个很慢的过程。使用 vmstat 命令可以更详细地检查内存情况。下面的图 4 中的 vmstat 输出表明系统不堪重负。“si”和“so”栏(swap-in 和 swap-out)与零相去甚远。此计算机需要更多的内存或者减少正在运行的程序。有关“si”和“so”的更多信息,请使用 man vmstat 获得。 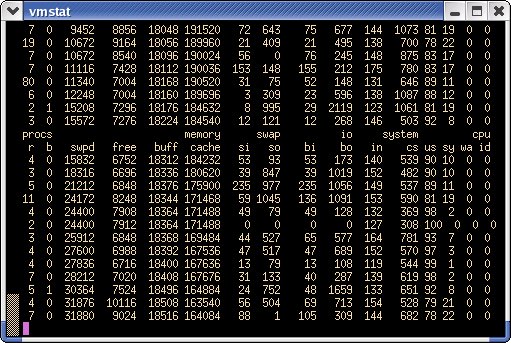
图 4. 内存不足的系统——“si”和“so”应该为零 运行服务器或者使用 VMWare 教授实验的最好做法就是“升级”内存时不用打开计算机。只需关闭客户操作系统 (guest operating system),将设置更改为使用全部内存,然后启动虚拟机,如下面的图 5 所示。如果虚拟机需要比运行主机操作系统更多的内存,则程序运行仍然会很慢。如果有人能够发明一个系统,它可以模拟的内存比硬件中现有的内存更多,则这些程序将会执行得非常好! 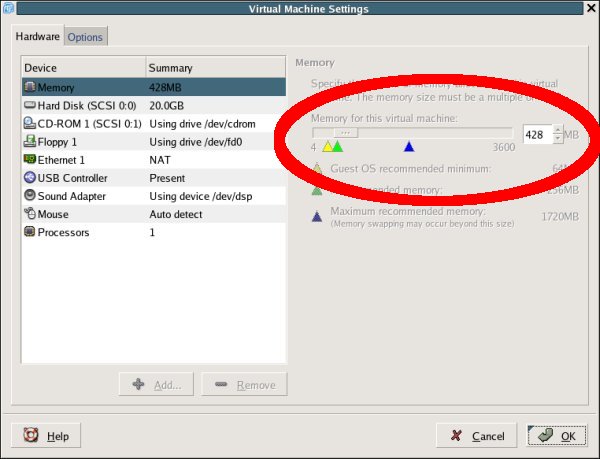
图 5. VMWare 工作站中的内存升级 其他环境因素 环境中有许多其他因素会影响性能,包括网络使用率、服务器上的其他程序、拒绝服务攻击以及电源线被绊断。请确保您的操作系统针对工作负载进行了优化。您需要修改 Linux 上的 sysctl、Solaris 上的 /etc/system,以及AIX 上的一组参数(请参阅下面的参考资料)。 数据库管理员 (DBA) 能够对性能优化做出很大的贡献。除了调整数据库参数外,DBA 可以识别出编得不好的查询和死锁生成器,这种反馈对提高性能是很重要的。DBA 还有一些灵活的工具,例如 DB2 Health Center,它可以识别问题并生成脚本来修复这些问题。DB2 Performance Adviser 和 Index Adviser 也使 DB2 数据库优化变得更容易。要打开 DB2 Health Center,您可以从命令行输入 db2hc,或者单击 DB2 Command Center 中的 Health Center 图标。下面的图 6 显示了 DB2 Health Center 生成的一个警报,图 7 显示了它为更大的锁列表提供的一个建议: 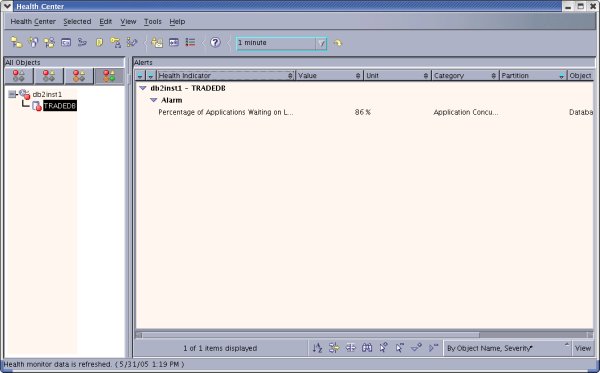
图 6. 正在运行的 Health Center:生成一个警报 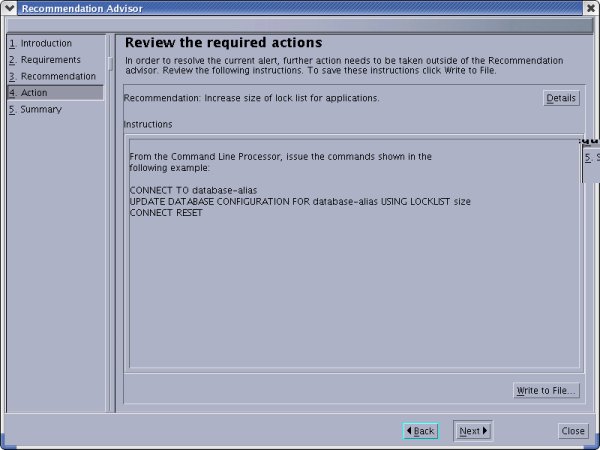
图 7. 正在运行的 Health Center:推荐解决方案 应该捕获图 7 中建议的命令并将其放在一个脚本文件中。当凌晨两点试图恢复系统时是没有地方获得 GUI 的!所有的一切都需要放在脚本中。 实现 Jython 经验优化方法 现在我们开始优化 WebSphere Application Server。Wikipedia.org 将经验方法 定义为“进行近似计算或回调某个值,或者进行某种决策的易学易用的过程”。这是进行快速而质量不高的优化的“入场券”。为什么使用 Jython 呢?硬核管理员使用命令行而非 GUI 来执行重复的定义良好的任务。引用我们一位开发专家的话,“生命太短,不足以用 tcl 编程。” JVM 冗余垃圾回收 (GC) JVM 在堆中执行其工作的核心部分。对象不再使用时就是垃圾(技术术语是它们不再被引用)。对于任何家居,您可以通过看其垃圾来了解居住的是什么样的人!Verbose GC 有助于您确定您的内存堆是否太多或太大。 清单 3. 优化冗余 GC | #(c)copyright 2005# sample code - not supported# get help with this command in interactive mode: AdminConfig.help()server1=AdminConfig.getid('/Node:tux1Node01/Server:server1/')print server1jvm = AdminConfig.list('JavaVirtualMachine', server1)print ">>>>> variable jvm is"print jvmprint ">>>>> AdminConfig.show(jvm)"print AdminConfig.show(jvm)print ">>>>> change jvm settings"AdminConfig.modify(jvm, [['verboseModeGarbageCollection','true' ]] )AdminConfig.save() print ">>>>> after save:"print AdminConfig.show(jvm)# on my system the output of verbose gc is in the file:# /opt/IBM/WebSphere/AppServer/profiles/default/logs/server1/native_stderr1.log# your milage may vary if you change the log locations## note - when using jython you must use the string 'true', see below. ##wsadmin>AdminConfig.modify(jvm, [['verboseModeGarbageCollection', 0 ]] )#WASX7435W: Value 0 is converted to a boolean value of false.#''#wsadmin>AdminConfig.modify(jvm, [['verboseModeGarbageCollection', 1 ]] )#WASX7435W: Value 1 is converted to a boolean value of false.#'' |
要使用以上脚本,请执行下列操作: 将其放在一个文件中并起一个有用的名字,例如 verboseGC_on.jython。 确保 wsadmin.sh(或者 wsadmin,对于 Windows┰谀拿盥肪吨小 在命令提示符下运行 wsadmin.sh -lang jython -f verboseGC_on.jython。 JVM 设置 现在您已经配置了冗余 GC,您可以开始优化堆的大小。理想情况下 GC 周期应该: 发生间隔大于 10 秒 在 1 至 2 秒内完成 下面的脚本将更改堆的大小。其目标是使堆足够大,大到 GC 间隔大于 10 秒;而又足够小,小到持续时间仅为 1 到 2 秒。对于每个新的 JVM 版本,GC 算法将会得到改进,所以此优化应该会随着时间的流逝越来越容易。 清单 4. native_stderr1.log,其 GC 间隔 6893 毫秒,持续时间 456 毫秒 | <AF[14]; Allocation Failure. need 528 bytes, 6893 ms since last AF><AF[14]; managing allocation failure,action=1 (0/183731208) (1668600/1668600)> <GC(14); freeing class sun.reflect.GeneratedMethodAccessor18(0x102391b8)> <GC(14); freeing class sun.reflect.GeneratedFieldAccessor1(0x104e9f48)>..... lines deleted...... <GC(14); freeing class sun.reflect.GeneratedFieldAccessor19(0x10129030)><GC(14); unloaded and freed 20 classes> <GC(14); GC cycle started Tue Dec 27 16;18;13 2005 <GC(14); freed 77240288 bytes, 42% free (78908888/185399808), in 436 ms> <GC(14); mark; 396 ms, sweep; 40 ms, compact; 0 ms><GC(14); refs; soft 52 (age > 6), weak 89, final 88, phantom 0><AF[14]; completed in 456 ms> |
清单 5. 将 JVM 堆增加到 512 MB - 1 GB | #(c)copyright 2005# sample code - notsupported#AdminConfig.help()server1=AdminConfig.getid('/Node:tux1Node01/Server:server1/')printserver1jvm = AdminConfig.list('JavaVirtualMachine', server1)print ">>>>> variable jvm is"print jvmprint ">>>>> AdminConfig.show(jvm)"print AdminConfig.show(jvm)print ">>>>> change jvm settings"AdminConfig.modify(jvm, [['initialHeapSize', 512 ],['maximumHeapSize', 1024 ]])print ">>>>> AdminConfig.show(jvm)"print AdminConfig.show(jvm)AdminConfig.save() |
连接池设置 小型(4 个 CPU)数据库服务器的“最佳状态”是提供 100-200 个连接。WebSphere 作为数据库服务器前面的一个连接集线器。连接池的大小限制了开放多少数据库连接来受理传入的页面请求。 清单 6 中的脚本将 Trade6 应用程序中使用的 JDBC 数据源的数据库连接池限制设置为 113。如果您的应用程序使用所有可用的连接,则大 数连接都可能有一个需求未能满足。您可以通过阅读 javacore 来检测此未满足的需求,或者通过增加连接数并查看什么时候应用服务器停止请求更多的连接。如果连接数等于或大于 WebSphere 客户端用户数,则应该检查应用程序是否存在不严谨的代码。 清单 6. 将 JDBC 连接池大小设置为 113 | #(c)copyright 2005# sample code - not supportedserver1=AdminConfig.getid('/Node:tux1Node01/Server:server1/')print server1jvm = AdminConfig.list('JavaVirtualMachine', server1)print "--> variable jvm is"print jvmprint "--> AdminConfig.show(jvm)"myds=AdminConfig.getid('/DataSource:TradeDataSource/')mydslist=AdminConfig.list('ConnectionPool',myds)print "-->before: "print AdminConfig.show(mydslist)AdminConfig.modify(myds, '[[connectionPool [[maxConnections 113]]]]')AdminConfig.save()#AdminConfig.modify(myds, '[[connectionPool [[minConnections 20]]]]')#AdminConfig.save()after: "mydslist=AdminConfig.list('ConnectionPool',myds)print AdminConfig.show(mydslist)#monitor connections at the database with the command# watch -d -n 5 "db2 list applications| wc -l"# or informix# watch -d -n 5 "onstat -g ses | wc -l"# this will include some irrelevant linesin count -- feel free to egrep them out |
启用 Servlet 缓存 WebSphere Application Server 内置了两个性能工具以帮助改进配置。Performance Adviser 会友好地建议您优化 servlet 缓存,如果您同意,它将使性能得以改善。下面的图 8 显示了性能查看器的图形输出。要访问免费的 IBM 联机 Education Assistant(它提供了有关如何使用 PMI 工具的教程),请查阅下面的参考资料。 清单 7. 启用 Servlet 缓存 | server1=AdminConfig.getid('/Node:tux1Node01/Server:server1/')printserver1mywebcont=AdminConfig.list('WebContainer', server1)print AdminConfig.show(mywebcont)print"now modify settings"AdminConfig.modify(mywebcont,[['enableServletCaching', 'true']] )AdminConfig.save()print AdminConfig.show(mywebcont) |
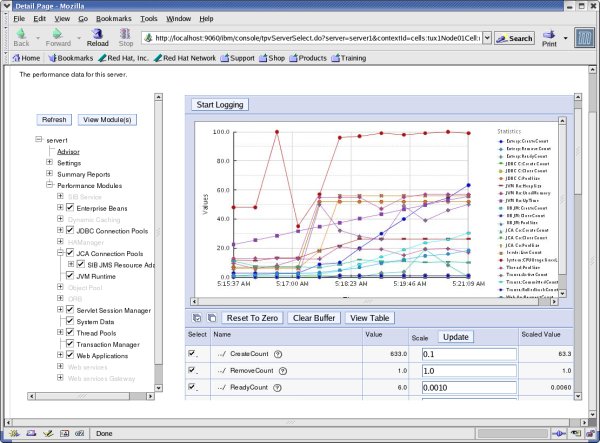
图 8. 性能查看器 线程池计数 此脚本适度地增加线程池以保证 CPU 能够接受。一个 CPU 可以驱动 50 到 75 Java 线程。该脚本很重要,因为它必须发现与 Web 容器相关的线程池。一些简单的 Jython 代码发现正确的标识符,然后为活动线程分配新的最小和最大值: 清单 8. 增加 WebContainer 的线程池大小 | server1=AdminConfig.getid('/Node:tux1Node01/Server:server1/')# show all thread pools# print AdminConfig.list('ThreadPool', server1)# from all the ThreadPools take the WebContainer# it will look something like this:#webpool='WebContainer(cells/tux1Node01Cell/nodes/tux1Node01#cont.../servers/server1|server.xml#ThreadPool_1113265230034)'## here is how to find the thread pool with jython#tpList=AdminConfig.list('ThreadPool', server1).split(lineSeparator)# now loop and find WebContainer# the string.count() tests for a substring# for production please add your own error handlingfor tp in tpList: if tp.count('WebContainer') == 1: tpWebContainer=tp## white space is significant in jython, so the un-indented line# ends the code blockprint tpWebContainerprint AdminConfig.show(tpWebContainer)# now that we have the identifier to get to tpWebContainer # adjust the settings#AdminConfig.modify( tpWebContainer, [['maximumSize', 75 ]] )AdminConfig.save()AdminConfig.modify( tpWebContainer, [['minimumSize', 50 ]] )AdminConfig.save()print AdminConfig.show(tpWebContainer) |
高级优化思想:下一步优化什么 有很多参数可以优化——一些可以使系统变得更快,一些则会使之变得更慢。要阅读优化佳作,请查阅下面的参考资料中的 SpecJAppServer2004 全面披露报告。 有大量创建脚本的资源——相信您会同意使用脚本是最好的方法。在您通过一两次使用管理 GUI了解了可用的参数范围后,将会考虑转为使用脚本。有关脚本的更多信息,请参阅下面的参考资料。 结束语 本文描述了如何基于一些简单的经验来配置 WebSphere Application Server。同时让您通过访问下面的许多资源来获得关于性能优化的更多信息。 在实验基准训练中,单一的最大改善是什么?优化应用程序!下面的图 9 显示了 Trade6 应用程序的配置页面。切换到直接的数据库访问和 JMS 是性能改善的最大单一贡献者。其他应用程序参数也提供了性能改善。该实验示例允许通过 Web 页面更改应用程序。您的应用程序也可以通过配置文件来获得类似的灵活性。 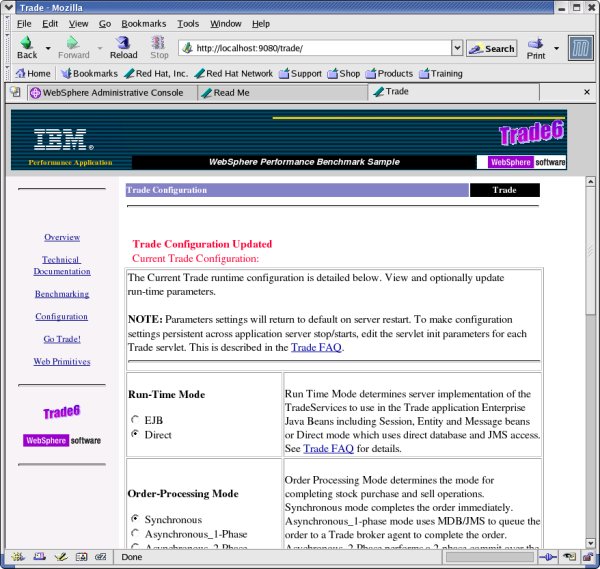
图 9. Trade6 应用程序配置页面:单个 CPU、0.2 秒响应时间 如果您达到或超越了性能目标,还应该做些什么呢?在下面的图 10 中,拥有 0.2 秒响应时间,看起来优化已经到头了。此时,您可以用更多的用户、更大的每用户事务数,或者更复杂的事务来增强测试工具。对于许多用户数超过计划的情况,详细的性能描述将使您了解配置平台的容纳范围有多大。 您可能对如何羸得实验练习和如何从示例应用程序获得最佳性能感兴趣。设计该实验和撰写本文的目的不是为了赢得一场竞争,而是为提高 WebSphere Application Server 性能提供一个快速指导。如果我忽略了您最喜欢的优化参数,我将很乐意在以后的文章中将它包含进来——请将您的优化建议用脚本形式发送给我,我的邮箱是 lurie@us.ibm.com。我期待您反馈您觉得容易优化且优化后能获得很大性能改善的参数,并将代码示例发送给我们。 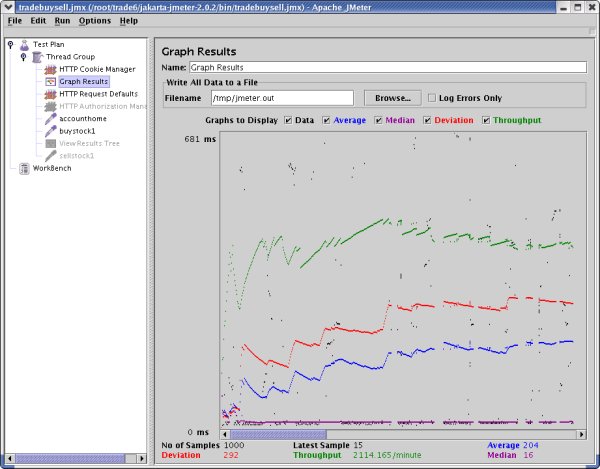
图 10. 应用程序优化提供最大收获:在一个 CPU 上获得 0.2 秒响应时间!
| 







 /1
/1 

 关于我们
关于我们






 发表于 2016-3-1 17:07:05
发表于 2016-3-1 17:07:05


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务
 发表于 2016-3-1 17:50:23
发表于 2016-3-1 17:50:23

