转自:博客园
接口自动化测试的"开胃小菜"1 写作目的本文讲述一个简单的利用WebAPI来进行一次基本没有破坏力的“黑客”行为。 主要目的如下: - 了解什么叫安全漏洞
- 知道什么是api
- 了解一些获取api的工具
- 通过对API的认识了解白盒接口测试基本概念和技术
免责声明: 本文主要是以学习交流为目的,而且实验的对象也是通过搜索引擎随机选择的。不以搞破坏为目的,纯粹是以教学为目的,同时也警醒大伙重视基本的互联网安全。当然,本文会对关键字打个马赛克,防止有兴趣的同学也把网站主当了靶子了。 如果网站主通过搜索引擎找到了本文,希望网站主最先能够做的是如何使用简单的方法堵住漏洞,当然如果网站主要求本文删除相应的信息,本文也会全力配合的。
2 背景介绍先说一个在互联网上常见,但是普通人又不太理解的东西--“验证码”。 
下面是来自 百度百科 的一段解释: 验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。 一般对于开放式的互联网应用,在有需要“上行”数据接口的地方都需要加上一道验证码(也可以是验证短信,但是考虑到成本问题,验证码还是更普遍一些),以防止机器程序使用其远高于人的计算能力进行一些恶意破坏行为。 所谓的恶意行为从技术本质上讲就是利用web应用已经提供的一些接口,来对网站主的后台数据库进行 增/删/改/查 的操作,而且由于这种操作是由计算机来完成,计算机巨大的计算能力常常伴产生极恐怖的破坏力。 通过“图灵测试”可以达到对自然人和机器的良好区分,以达到将机器程序抵挡在外面的目的,阻止其利用其强大的计算能力和自动化信息处理能力来实施破坏。这就是“验证码”的最基本作用。 那么回归到今天的正题,既然是“黑客技术入门”和“接口自动化测试”的入门篇,本文就先挑一些难度低的开始,专门找“软柿子”来捏一下。
3 主要工具
4 寻找攻击对象通过搜索引擎,找关键字:“意见反馈”、“用户反馈”,得到如下的搜索结果: 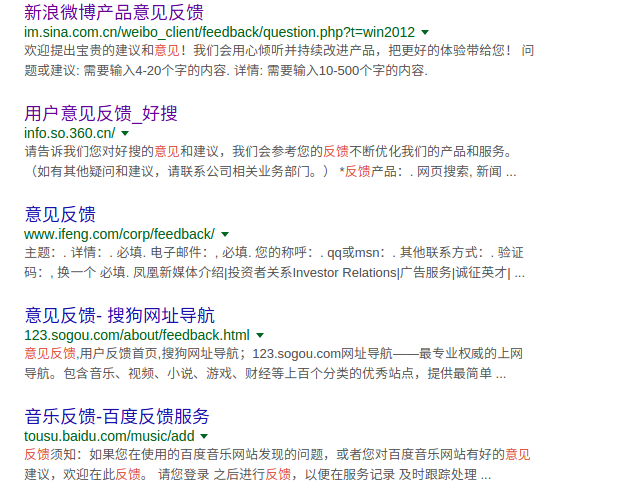
“用户反馈”模块有如下特点: - 有数据上行。因为有向服务器提交数据,会通过相应的接口往网站主服务器上写相应的数据。
- 在Web应用里面重要性很低。很多是象征的摆设,所以安全防范极低。
- 不涉及具体的重要业务。可以在练手的同时,也不会产生多少破坏。
只需要找出里面没有验证码的页面就可以了,主要的搜索结果如下: 有验证码的网站: 无验证码的网站: - 新浪微博
- 搜狗网址导航
- 百度音乐
- 百度百科
- 网易163
- 有道词典
- 易车
- 114la
- 中科大教务处
这只是Google的前两页的搜索结果,发现已经有一大半在这一块是没有进行任何防守的。既然已经找到了这么一个简单的安全“漏洞”,下面就开始实施无关痛痒的“攻击”行为。 由于本文主要是出于学习和交流目的,为了保护实验对象的一些隐私,所以下面的图片和相应的URL都会进行一些简单的马塞克。
5 收集api信息由于Web应用系统本身是不对外开放api的,但是互联网公司的产品为了追求高扩展性和前后端完全分离独立,通常使用如下技术架构: 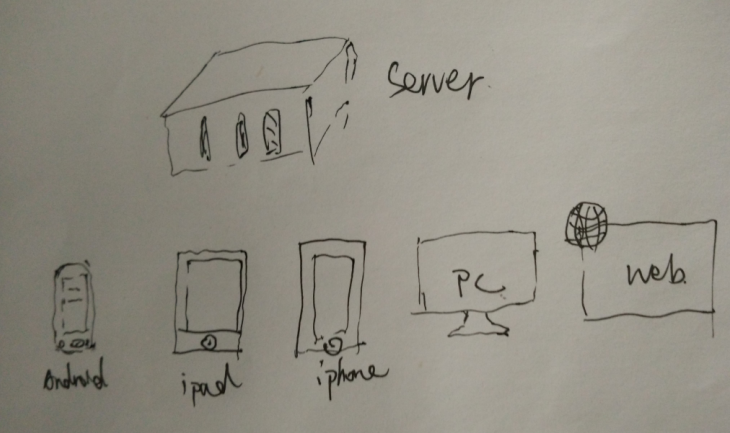
互联网应用的架构,客户端和服务器一般都是基于Http API来进行通讯,所以对于B/S的程序来说,可以很容易通过一些辅助工具来找到通讯的接口。 某个网站“有幸”被选中了: http://x.xxx.xx/ugc/out/feedback/使用Chrome浏览器打开页面 然后填写好表单之后,点击提交按钮。当然,因为提交按钮之后,会跳转到另外一个页面,不便于我们查看提交的数据值,所以要做一些简单的修改,就是表单提交的服务器API简单修改成一个不存在的即可: 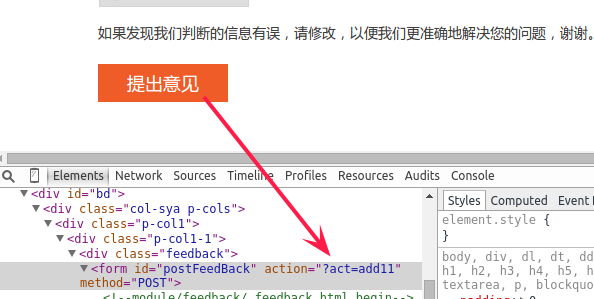
然后在Chrome的Network里面可以看到接口信息: 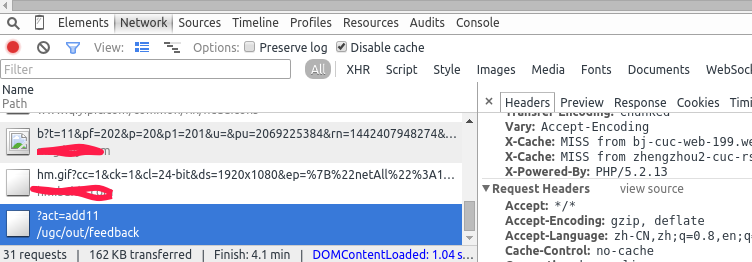
然后将右侧的接口详细数据信息展开,就可以查看到表单值: 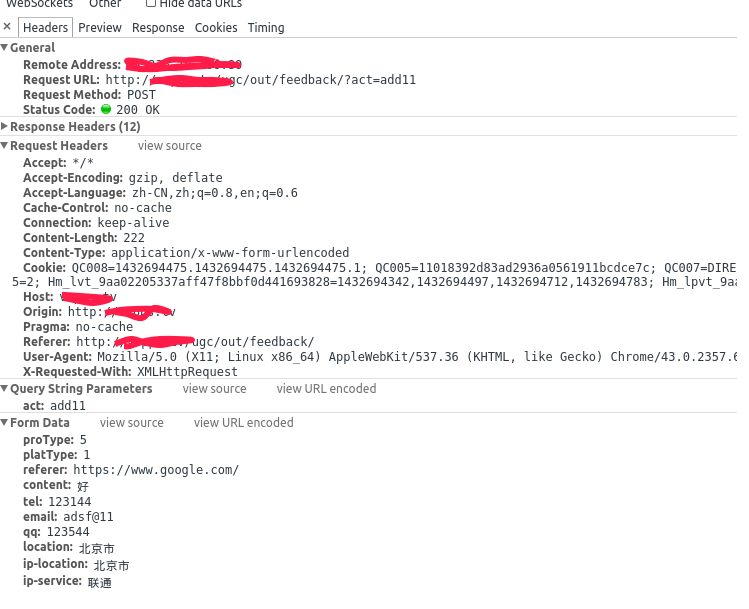
这个表单就告诉了我们此网站应用的服务器端API所接收的合法的数据的格式,这样就相当于知道了调用的方式了。 知道了接口,知道了调用方式,那么接下来就可以通过写程序来实施“黑客”行为了。
6 编写crack脚本由于本人python比较熟悉,所以就使用python来进行相应的操作演示。
- def test_crack_feedback(self):
- """
- 反馈页面刷的测试
- :return:
- """
- url_para = {
- 'proType': 5,
- 'platType': 1,
- 'referer': 'https://www.google.com/',
- 'content': '看你们是否存在此漏洞',
- 'tel': '123144',
- 'email': 'adsf@11',
- 'qq': '123544',
- 'location': '北京市',
- 'ip-location': '北京市',
- 'ip-service': '联通',
- }
-
- post_url = 'http://x.xxx.xx/ugc/out/feedback/?act=add'
-
- res = requests.post(post_url, data=url_para)
- glog.debug(res.text)
返回值 - 1 <span style="font-size: 14px; line-height: 18.2609px;">[2015-05-27 10:58:51,166] connectionpool.py:_new_conn-(259)INFO: Starting new HTTP connection (1): x.xxx.xx</span>
- 2 <span style="font-size: 14px; line-height: 18.2609px;">[2015-05-27 10:58:51,764] connectionpool.py:_make_request-(390)DEBUG: Setting read timeout to None</span>
- 3 <span style="font-size: 14px; line-height: 18.2609px;">[2015-05-27 10:58:52,175] connectionpool.py:_make_request-(430)DEBUG: "POST /ugc/out/feedback/?act=add HTTP/1.1" 200 None</span>
- 4 <span style="font-size: 14px; line-height: 18.2609px;">[2015-05-27 10:58:52,245] singlefun.py:run_xxx-(29)DEBUG: {"retcode":200,"message":null}</span>
根据200的状态码,明显是成功了。因为有经验的Web开发人员都清楚,Http的200状态码就表示成功调用的返回值了。 如果我使用个for循环,将此程序运行100万次,那么这个网站主的这个地方的数据库估计就要抓狂了。如果使用多个机器连续疯狂的刷,而且恰好这个数据表和他们的核心业务数据库放在一起,那么这将会导致数据库连接数量超过极限,导致正常的服务无法被提供了。
7 后续展望和总结本文只是演示了如何利用Chrome去寻找Web应用的接口及调用。而对于看不到前端代码的App应用,则可以通过抓包工具Wireshark来轻松获得相应的接口及调用。 网站主避免此漏洞的方法:给相应的位置加上可靠的“验证码”即可。 PS:传统的字符型验证码,稍微会一些图片识别技术,或者机器学习技术,也是相当好破解的。目前的OCR技术已经相当发达了,想想注册Gmail的时候,那一串人都不认识的字符,结果程序可以进行90%的成功破解率,可想而之机器远比人类想像得要厉害。 当然,如何做好“图灵测试”对“自然人”和“机器人”进行区分,已经成为安全领域的一个重要的课题,也非本文重点讨论的问题了,有兴趣的同学可以在相关领域继续研究吧。 这个事情给做Web应用系统的人员两个警钟: - 所有涉及到数据交互的地方,最好加上验证码。
- 数据尽量要按照重要等级分开部署。
8 免责声明- 本文只是以学习交流为目的
- 本文没有产生破坏行为
- 本文所获取的信息都是通过正常的暴露在外部的信息得到的
- 本文隐藏了具体的URL目标的信息
- 如果实在是有人有要求认为本文造成了事实伤害,作者会按照要求删除此文
- 最后希望此文能够给有志做接口自动化测试的朋友提供了一个好的“开胃菜”
| 







 /1
/1 

 关于我们
关于我们






 发表于 2016-8-9 11:37:10
发表于 2016-8-9 11:37:10


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务
 发表于 2016-8-10 10:41:04
发表于 2016-8-10 10:41:04


