 |  |  |  |  |
|
314| 0
|



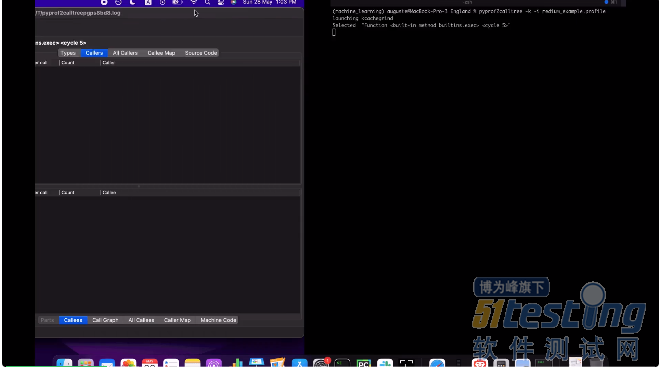
[python] 浅谈Python使用cProfile可视化并解决性能瓶颈问题 |
| ||
 /1
/1 

小黑屋|手机版|Archiver|51Testing软件测试网
( 沪ICP备05003035号 )  关于我们
关于我们
GMT+8, 2024-5-6 16:37 , Processed in 0.064384 second(s), 22 queries .
Powered by Discuz! X3.2
© 2001-2024 Comsenz Inc.






 发表于 2023-6-12 11:11:51
发表于 2023-6-12 11:11:51





 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务