TA的每日心情 | 无聊
14 小时前 |
|---|
签到天数: 946 天 连续签到: 5 天 [LV.10]测试总司令
|
前言
我们前面更新爬虫实战的一些文章,从今天起,我们重点讲解关于parsel解析库的实战技巧,通过实战,我们来学习其强大的功能。
我们先来认识一下什么是parsel库。
Parsel是一个用于解析JSON数据的Python库。它提供了一个简单易用的API,可以轻松地从JSON文件或字符串中解析数据。可以对 HTML 和 XML 进行解析,并支持使用 XPath 和 CSS Selector 对内容进行提取和修改,同时它还融合了正则表达式提取的功能。功能灵活而又强大。
采集数据
我们上一篇介绍了,如何采集大学教务系统里面的成绩单,把自己的成绩采集下来。今天,我们来采集当当网里面的商品信息。之前,我们基本上都是用正则表达式来获取数据的,今天,我们使用parsel方法来获取数据。
发送请求
我们首先确定我们的目标网址,对我们需要获取的数据。这个是我们爬取任何网页都要做的第一步。
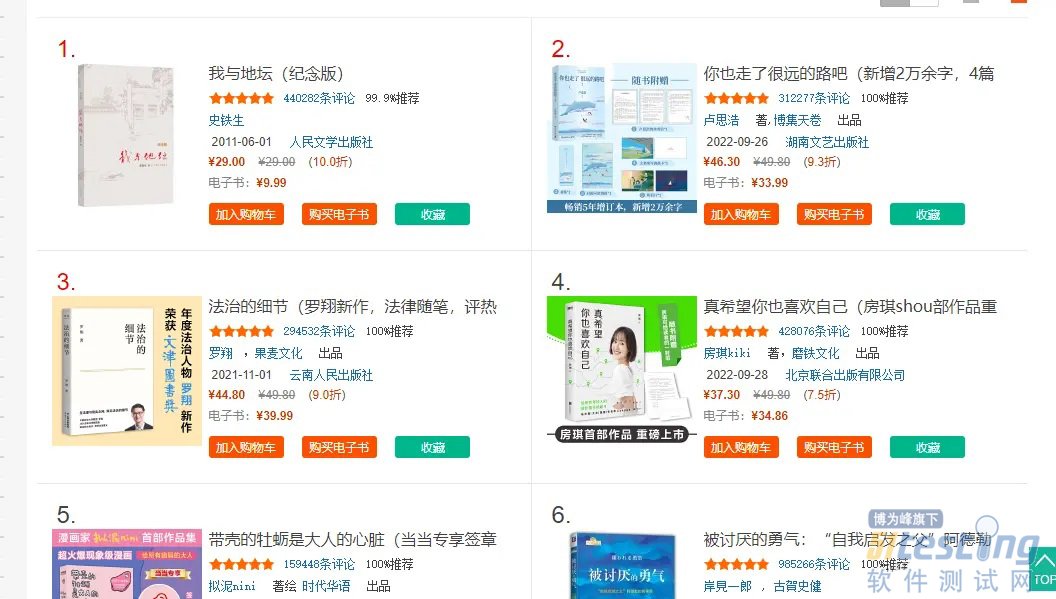
我们要把每一个图书的数据获取下来,我们接下来用到开发者工具。我们看图书名字和价格是在什么位置。是不是在网页源代码中。接下来,我们发送请求,获取网页源代码。
我们可以观察到,每一个商品信息都放在<li>标签里面。我们只要提取<li>标签里面的内容即可。
我们现在开始写代码。
url="http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1"
headers={
'User-Agent': 'Mozilla/5.0 ([url=]Windows[/url] NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response=requests.get(url=url,headers=headers)
代码使用requests库的get()函数来请求这个URL,并将结果存储在变量res中。
获取数据
selector=parsel.Selector(response.text)
lis=selector.css('.bang_list li')
print(lis)
我们使用css方法选择了所有的列表项,并使用?xpath?方法选择了所有包含?.bang_list li?类的列表项。也就是我们上面提到的<li>标签里面的内容。
我们看看效果怎么样。

for li in lis:
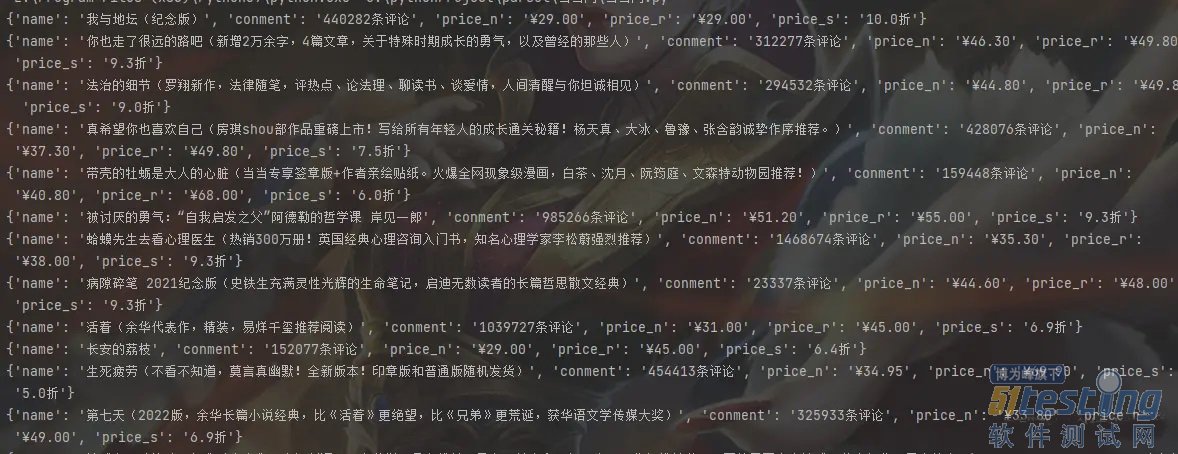
name=li.css('.name a::attr(title)').get()
conment=li.css('.star a::text').get()
price_n=li.css('.price .price_n::text').get()
price_r=li.css('.price .price_r::text').get()
price_s=li.css('.price .price_s::text').get()
css方法用于选择元素的 CSS 样式。在上面的示例中,我们使用css方法选择了所有的列表项,并使用xpath方法选择了所有包含.name a::attr(title)类的列表项。
然后,我们使用get()方法获取了列表项中每个元素的name属性,以及star类中每个元素的text属性。
最后,我们使用get()方法获取了列表项中每个元素的price_n属性,以及price_r和price_s属性。
保存数据
保存数据就简单了,我们已经练习了很多次。
f=open('./data.csv', mode='a', encoding='utf-8', newline='')
csv_writer=csv.DictWriter(f,fieldnames=[
'name',
'conment',
'price_n',
'price_r',
'price_s',
])
这段代码首先打开一个名为data.csv的文件,并指定使用a模式打开文件。然后,使用csv.DictWriter()函数创建一个 CSV 写入器,并指定要写入的列名。在这个例子中,我们指定了fieldnames参数,它包含了我们要写入的列名。
接下来,我们使用csv_writer.writeheader()方法写入列名。这个方法会将列名写入文件的第一行。
最后,我们使用csv_writer.writerow()方法写入数据。
我们先写入字典。
dit = {
'name':name,
'conment':conment,
'price_n':price_n,
'price_r':price_r,
'price_s':price_s,
}
csv_writer.writerow(dit)
这段代码创建了一个字典dit,其中包含了每个元素的值。然后,它使用csv_writer.writerow()方法将字典写入CSV文件中。
我们可以看到,我们已经把数据获取下来了,我们这里发现了,其css语法和我们之前说的一样,这个功能太强大了。
总结
本文主要介绍了parsel库的实战技巧,包括如何采集数据、发送请求和获取数据等方面的内容。通过实战,我们可以学习到parsel库的强大功能,包括对HTML和XML的解析、XPath和CSS Selector的使用以及正则表达式提取的功能。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-4-23 14:35:49
发表于 2023-4-23 14:35:49



 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务
 发表于 2023-4-25 10:20:55
发表于 2023-4-25 10:20:55

