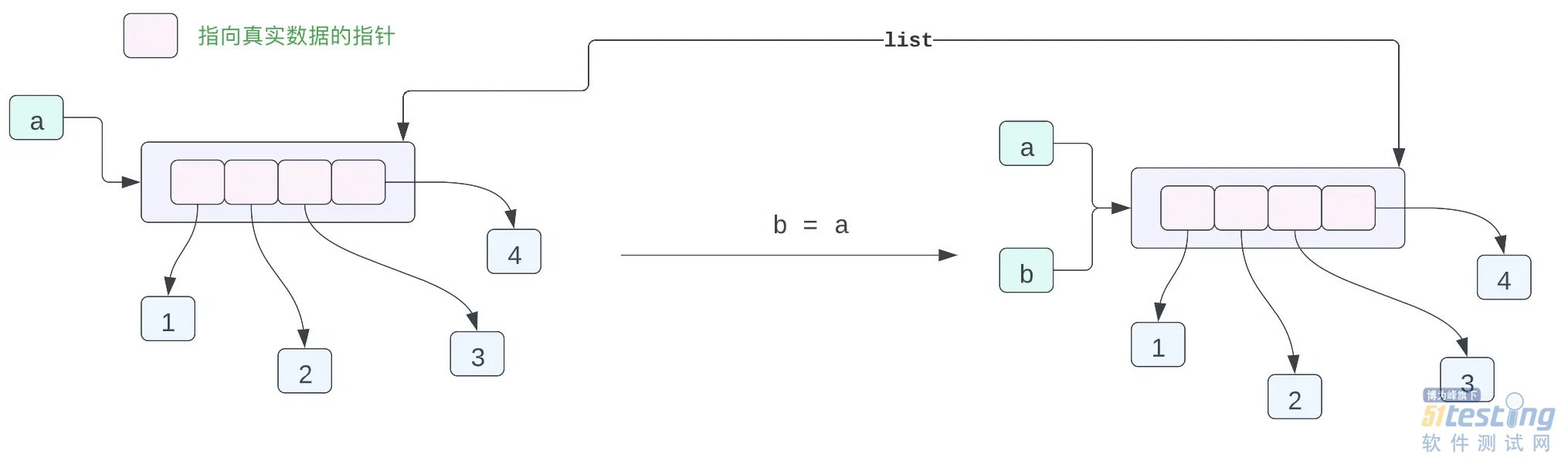
data_assign = data,关于这个赋值语句的内存布局我们在之前已经谈到过了,不过我们也在复习一下,这个赋值语句的含义就是 data_assign 和 data 指向的数据是同一个数据,也就是同一个列表。
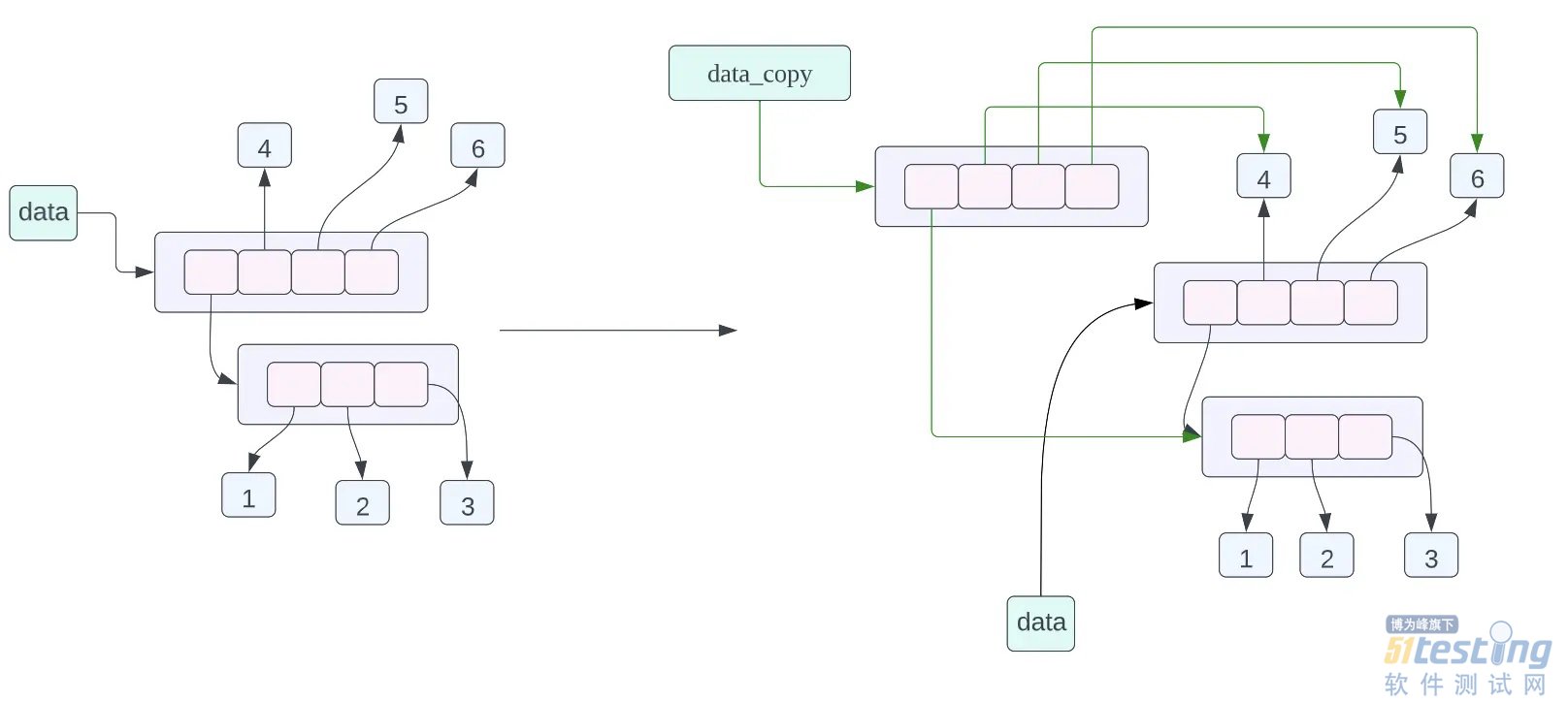
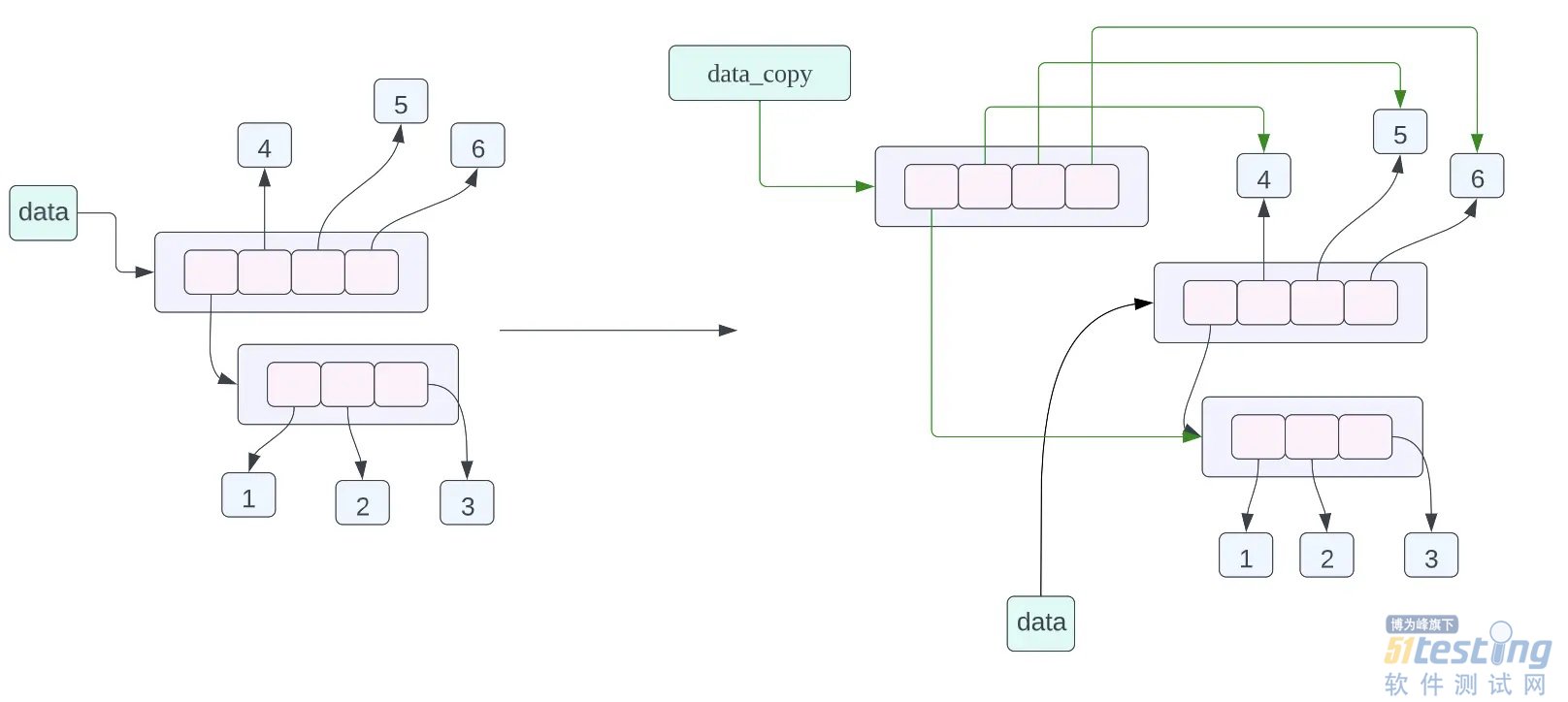
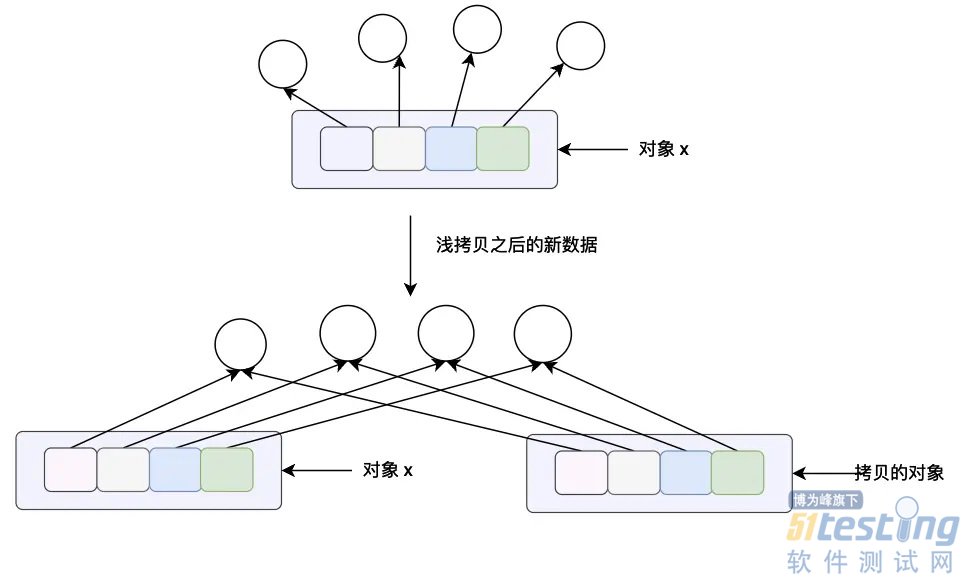
data_copy = data.copy(),这条赋值语句的含义是将 data 指向的数据进行浅拷贝,然后让 data_copy 指向拷贝之后的数据,这里的浅拷贝的意思就是,对列表当中的每一个指针进行拷贝,而不对列表当中指针指向的数据进行拷贝。从上面的对象的内存布局图我们可以看到 data_copy 指向一个新的列表,但是列表当中的指针指向的数据和 data 列表当中的指针指向的数据是一样的,其中 data_copy 使用绿色的箭头进行表示,data 使用黑色的箭头进行表示。 查看对象的内存地址
在前面的文章当中我们主要分析了一下对象的内存布局,在本小节我们使用 python 给我们提供一个非常有效的工具去验证这一点。在 python 当中我们可以使用 id() 去查看对象的内存地址,id(a) 就是查看对象 a 所指向的对象的内存地址。
看下面的程序的输出结果:
a = [1, 2, 3]
b = a
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a) = } {id(b) = }")
根据我们之前的分析,a 和 b 指向的同一块内存,也就说两个变量指向的是同一个 Python 对象,因此上面的多有输出的 id 结果 a 和 b 都是相同的,上面的输出结果如下:
id(a) = 4392953984 id(b) = 4392953984
i = 0 id(a) = 4312613104 id(b) = 4312613104
i = 1 id(a) = 4312613136 id(b) = 4312613136
i = 2 id(a) = 4312613168 id(b) = 4312613168
看一下浅拷贝的内存地址:
a = [[1, 2, 3], 4, 5]
b = a.copy()
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a) = } {id(b) = }")
根据我们在前面的分析,调用列表本身的 copy 方法是对列表进行浅拷贝,只拷贝列表的指针数据,并不拷贝列表当中指针指向的真正的数据,因此如果我们对列表当中的数据进行遍历得到指向的对象的地址的话,列表 a 和列表 b 返回的结果是一样的,但是和上一个例子不同的是 a 和 b 指向的列表的本身的地址是不一样的(因为进行了数据拷贝,可以参照下面浅拷贝的结果进行理解)。
copy.deepcopy(x) 这个方法主要是对对象 x 进行深拷贝,这里的深拷贝的含义是会构造一个新的对象,会递归的查看对象 x 当中的每一个对象,如果递归查看的对象是一个不可变对象将不会进行拷贝,如果查看到的对象是可变对象的话,将重新开辟一块内存空间,将原来的在对象 x 当中的数据拷贝的新的内存当中。(关于可变和不可变对象我们将在下一个小节仔细分析)
根据上面的分析我们可以知道深拷贝的花费是比浅拷贝多的,尤其是当一个对象当中有很多子对象的时候,会花费很多时间和内存空间。
对于 python 对象来说进行深拷贝和浅拷贝的区别主要在于复合对象(对象当中有子对象,比如说列表,元祖、类的实例等等)。这一点主要是和下一小节的可变和不可变对象有关系。