TA的每日心情 | 无聊
3 天前 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
最近chatgpt非常火,通过chatgpt可以做很多事情,笔者也通过实际使用解决了自己的问题,都基本不用自己编程。
本文主要需要解决:
通过burpsuite批量获取的json文件,需要处理成mysql数据库识别的格式,方便入库。
(1)重命名所有文件为txt后缀文件
(2)删除txt文件无用的前N行数据,其实就是头文件数据,有几行就定义几行。
(3)重命名txt文件为json文件。
(4)对json文件自动识别表列名,并处理数据到一个文件中。
1.chatgpt尝试
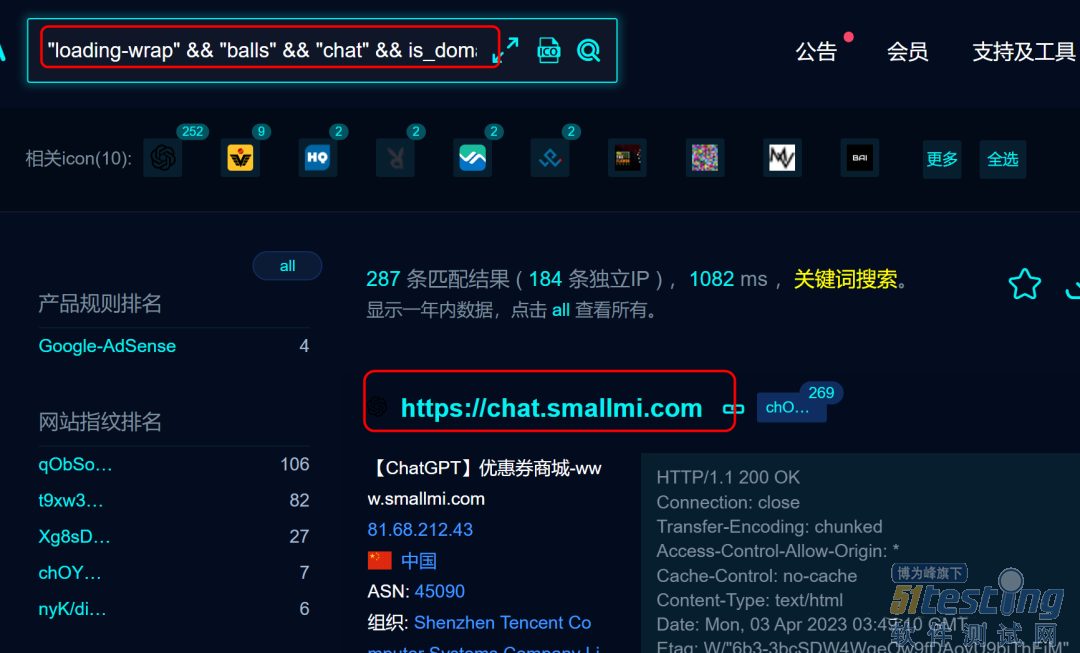
通过fofa.info搜索"loading-wrap" && "balls" && "chat" && is_domain=true,搜索的记录就是提供chatgpt的网站地址。
2.逐个网站测试是否可以免费使用
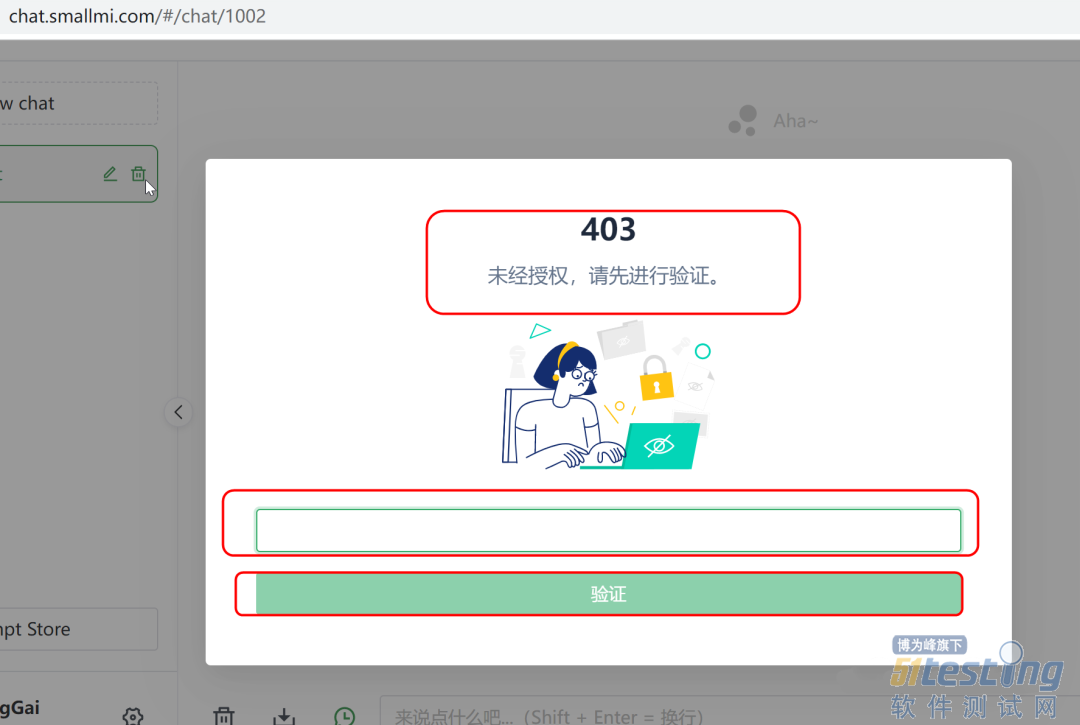
打开搜索中的记录,逐个查看,有的需要输入密码才能方法,寻找一些免费的chatgpt。
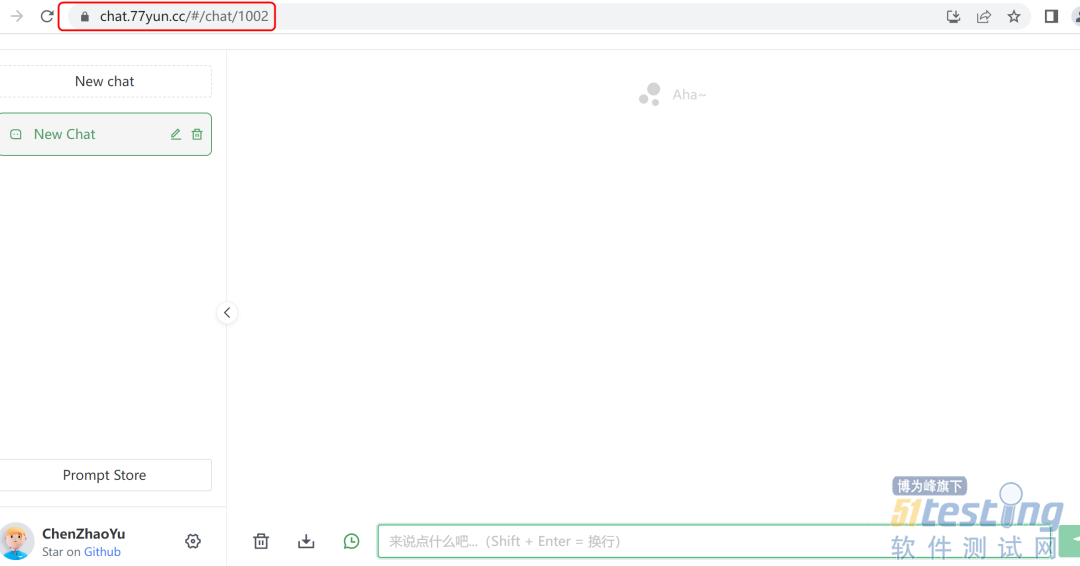
对一些需要输入验证的直接pass掉,然后寻找一些不需要密码就能访问的。例如https://chat.77yun.cc/#/chat/1002
3.进行实际测试
可以在chatgpt中将自己的问题提出来,输入回车后即可获取相应的解决方法。同时对实际数据进行测试,不断的训练,最后达到自己想要的结果。
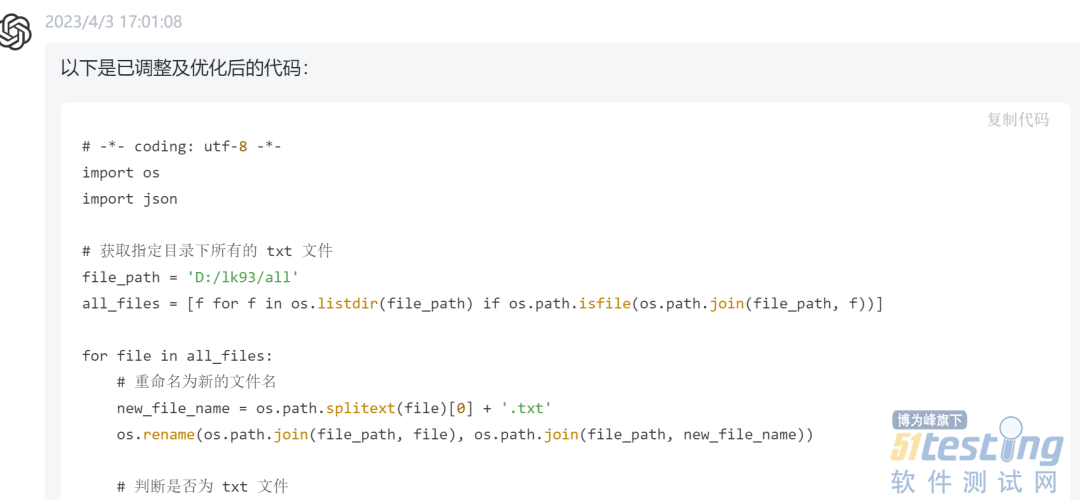
4.最后的代码为
import os
import json
#获取指定目录下所有的文件
dir = 'all'
all_files = [f for f in os.listdir(dir) if os.path.isfile(os.path.join(dir, f))]
for file in all_files:
#将所有扩展名不是.txt的文件改名为同名.txt文件
if not file.endswith('.txt'):
os.rename(os.path.join(dir, file), os.path.join(dir, os.path.splitext(file)[0] + '.txt'))
file = os.path.splitext(file)[0] + '.txt'
#对于每个txt文件,删除前9行的内容并保存到新的txt文件中
with open(os.path.join(dir, file), 'r', encoding='utf-8') as txt_file:
content = txt_file.readlines()
deleted_content = '\n'.join(content[:9])
new_content = ''.join(content[9:])
with open(os.path.join(dir, file), 'w', encoding='utf-8') as txt_file:
txt_file.write(new_content)
#将新的txt文件重命名为同名.json文件,并读取其内容
json_file = os.path.splitext(file)[0] + '.json'
os.rename(os.path.join(dir, file), os.path.join(dir, json_file))
with open(os.path.join(dir, json_file), 'r', encoding='utf-8') as j_file:
data = json.load(j_file)
columns = list(data['page']['list'][0].keys())
rows = []
for item in data['page']['list']:
row_values = []
for column in columns:
value = str(item[column]).replace('\n','').replace(',','')
row_values.append(value)
rows.append(','.join(row_values))
#整理json文件中的数据,并按照列名的顺序写入数据文件out.txt中
with open('out.txt', 'a+', encoding='utf-8') as out_file:
if out_file.tell() == 0:
out_file.write(','.join(columns) + '\n')
out_file.write('\n'.join(rows)+'\n')
print("文件{}中的数据已写入out.txt文件中".format(json_file))
5.总结
使用chatgpt编程非常简单,关键你需要定义好你需要的东西。例如我的功能描述如下:
(1)使用python代码实现以下功能:当前数据目录为all
(2)原始代码中首先对所有文件重命名为文件ren *.* *.txt
(3)获取指定目录下所有的文件,并遍历每个文件。
(4)将所有扩展名不是 .txt 的文件重命名为同名的 .txt 文件,保证后续处理只考虑 txt 文件。
(5)对于每个txt文件,读取文件内容并删除前9行的内容,这一部分数据在原代码中被称为“头部内容”,然后将剩余内容保存到新的txt文件中。
(6)将新的txt文件重命名为同名 .json 文件,并读取其内容。
(7)整理 json 文件中的数据,并按照列名的顺序写入数据文件out.txt中。
需要清晰的定义好想要的功能点,然后通过不停的训练测试最终达到自己想要的效果。总之有了chatgpt后,你有产品的思路就可以,很多功能可以简化,有编程功底的人可以更好的利用。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-5-9 10:56:48
发表于 2023-5-9 10:56:48



 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务