TA的每日心情 | 无聊
昨天 09:05 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
ChatGPT最近备受关注,官网中提供了许多ChatGPT应用场景,例如SQL翻译、语言翻译、代码解释等。作为一名QA,我更关注 ChatGPT生成的自动化测试脚本质量如何,借助ChatGPT能否提升自动化测试编写效率。当提到自动化测试时,我们通常将其分为单元测试、接口测试和UI测试,接下来,我们先看看ChatGPT生成的单元测试代码的质量如何。
ChatGPT辅助后补单元测试
首先,使用Spring框架编写一个简单的后端服务,服务包括两个接口:一个 createUser 接口和一个 getUsers 接口,使用 “spring-boot-starter-data-jpa” 连接、操作数据。service 层的代码实际上没有业务处理逻辑,只是调用了 Repository 中的方法而已。为了让 ChaGPT 为 service 层的代码编写单元测试,Prompt 中的要求如下:
1.Prompt 中要求使用 JUnit5 和 Mockito 框架。
2.Prompt 中要求使用@Mock和@InjectMocks注解。
3.Prompt 中给出了 UserServiceImpl 中的 createUser() 方法的源代码。
ChatGPT 生成了两个测试用例:一个正向测试用例和一个异常测试用例。将这些代码复制到 IDE 中,基本上无需修改即可成功运行。通过这个实验,可以看到,对于简单逻辑的代码,ChatGPT 生成的单元测试代码质量较高。
在上面的例子中,介绍了如何编写 Service 层的单元测试。如果希望编写 Controller 层的单元测试,只需稍微修改 Prompt,在 Prompt 中要求使用 Spring 框架提供的 MockMvc 编写单元测试即可。除了单元测试,针对后端服务,也建议编写少量容器内的集成测试,以覆盖 Controller 层到 DB 层的代码。修改 Prompt,在 Prompt 中要求使用@SpringBootTest和 TestRestTemplate 编写集成测试。实验结果如下,将生成的代码复制到 IDE 上,几乎无需任何修改即可成功执行。
总结而言,对于逻辑比较简单的代码,ChatGPT 生成的单元测试和集成测试代码质量较高,基本可以直接运行,或做很小的修改即可运行。接下来,继续探索对于稍微复杂的代码,ChatGPT 生成的单元测试质量如何。下图是特意编写的一个包含很多分支逻辑的方法,源代码中包含一个 public 的 toLocal() 方法和几个 private 方法,toLocal() 方法会调用这些私有方法。Prompt 和生成的单元测试如下所示:
1.由于代码中存在很多分支逻辑,适合参数化测试数据,因此 Prompt 中要求使@Parameterized
2.将生成的测试代码复制到 IDE 中运行,会发现部分单元测试运行失败。经检查发现,部分单元测试与源代码的逻辑不符,这表明对于稍微复杂的代码,ChatGPT 生成的单元测试仍需要人工干预来进行修正。
3.ChatGPT 生成的单元测试覆盖率在 30%-40% 左右,如果继续要求 ChatGPT 补充更多的单元测试,ChatGPT 可能会生成一些与上一个版本重复的单元测试,或者给私有方法添加单元测试。这表明对于分支逻辑较为复杂的代码,ChatGPT 生成的单元测试覆盖率不够,剩余的部分需要人工进行补充。
当然,上面都是针对遗留系统需要后补单元测试的情况,如果是新系统的开发,我们更加推荐采用 TDD 的方式,而不是在后期补充单元测试。
ChatGPT辅助编写接口自动化测试
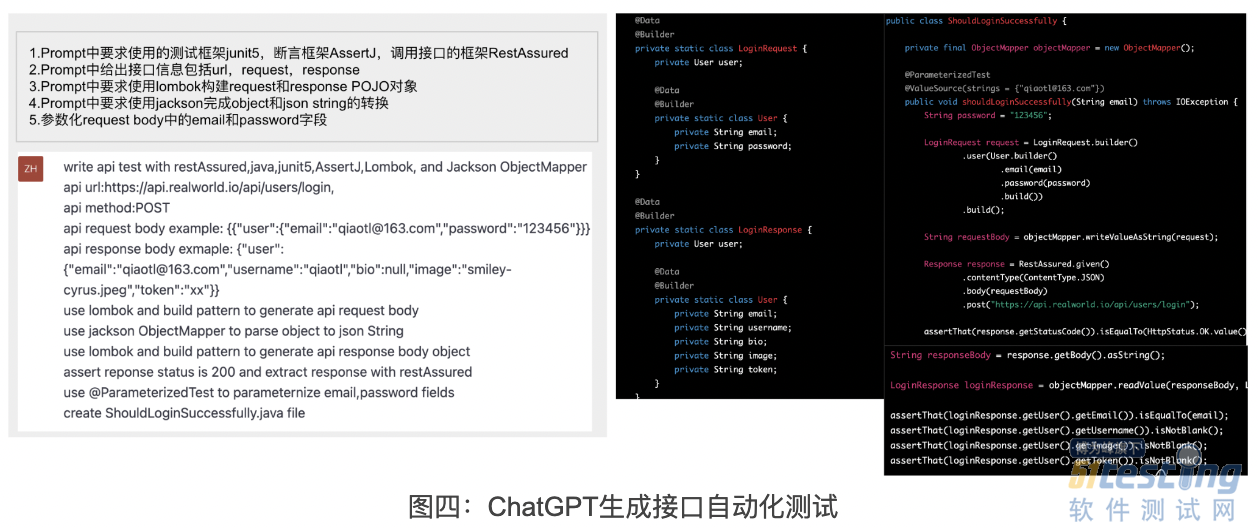
如果要为一个接口编写自动化测试,除需确定测试框架外,还需构建接口的 Request、Response Object。以选用 Java 技术栈为例,可以选用 Lombok 来灵活构建接口的 Request body,使用 jackson 完成 object 和 json string 的转换。下图是 ChatGPT 生成的接口自动化测试结果,接口测试代码质量较高,几乎无需修改即可成功运行。
当然,上述实验仅为单个接口生成接口测试。在实际项目中,接口测试还涉及多个接口间的值传递、配置信息管理、测试数据管理等问题。从测试场景的角度来看,即便是测试同一个接口,也需要构建不同的 Request body 以测试接口的返回内容是否符合预期。实际,对于这些任务都可以通过任务拆解、提供不同的 Prompt 来完成。例如,对于多个接口之间的值传递场景,可以在 Prompt 中先提供第一个接口的信息,生成代码后,再提供第二个接口信息,在生成的代码基础上稍微调整,即可完成不同接口间值传递场景。总结而言,利用 ChatGPT 可提高编写接口自动化测试的效率。
ChatGPT辅助编写Web UI自动化测试
当搜索 “ChatGPT auto write test” 时,发现排在前面的大多数是关于 “如何使用 ChatGPT 编写 web UI 自动化测试” 的文章,这似乎有些奇怪,因为编写 Web UI 自动化测试需要定位 Web 页面上的目标元素,而 ChatGPT 并不知道被测 Web 系统的页面结构。从原理上来说,ChatGPT 无法编写 UI 自动化测试,那么 ChatGPT 真的能编写 Web UI 自动化测试吗?
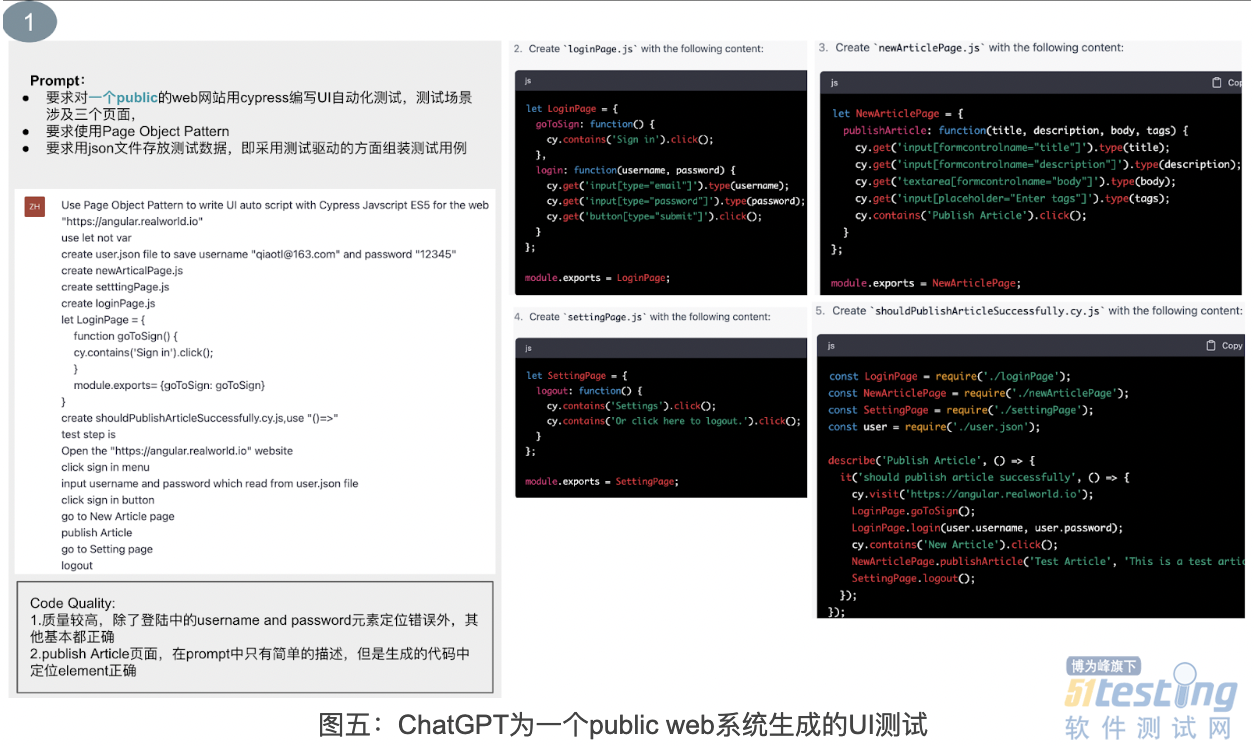
先来看下第一个例子,让 ChatGPT 使用 Cypress 对一个公共网站 “https://angular.realworld.io/” 编写 UI 自动化测试,测试场景涉及三个页面。生成的自动化测试质量很高,除了登录页面上的两个元素定位错误外,其他部分基本正确。并且,按照 Prompt 中要求的 Page Object 模式生成代码,因此,只需稍微修改即可成功运行。当我做到这个实验时,我觉得很奇怪,为什么页面元素定位准确率这么高?我尝试询问 ChatGPT 是否会爬取页面结构,ChatGPT 回复并没有。
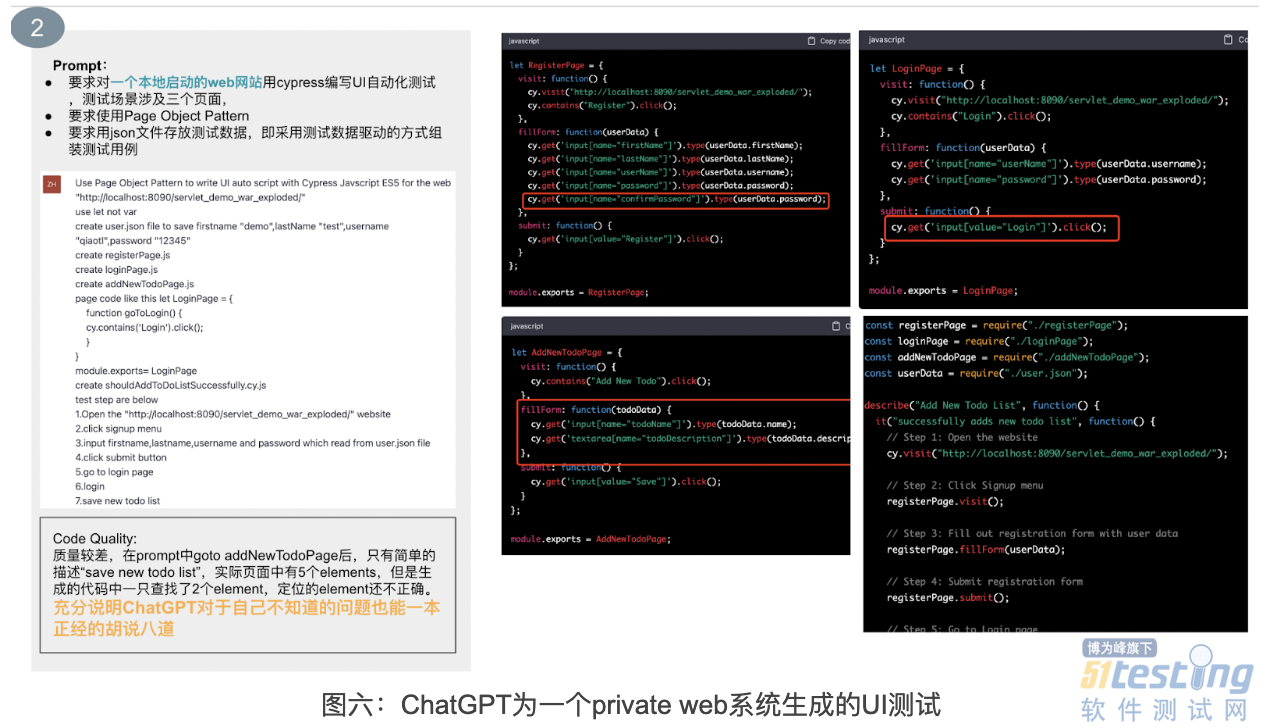
为了搞清楚这个问题,我做了第2个实验,编写了一个包含注册、登录、添加 todoList 的简单 web 系统,本地启动后,让 ChatGPT 为这个 web 系统编写 UI 自动化测试脚本,测试场景涉及三个页面。此次生成的脚本质量较差,部分元素定位错误,第三个页面总共有5个页面元素,ChatGPT 只定位了2个,且定位元素的 selector 也不正确。但是通篇没有任何留空白的地方,在这里,我们也看到了 ChatGPT 如何一本正经地胡说八道。
从上面的实验来看,即使是本地启动的 Web 系统,ChatGPT 仍然可以正确定位少量页面元素。经过分析和观察,我猜测 ChatGPT 大概是根据 Prompt 中的信息猜测元素的类型,然后选用可能性较高的一种方式来定位页面元素。例如,Prompt 提供如下信息:
进入https://xxxx
点击 “signup” 菜单
输入 username、password
ChatGPT 结合上述信息,会猜测 “signup” 菜单是一个链接,因此会选用 Cypress 中的 “cy.contain(“signup”)” 来定位该元素。它还会猜测 username 和 password 是 input 类型的元素,因此会选择使用 Cypress 中的 “cy.get('input[name="firstname"]')” 来定位这些元素。当然,如果你多次生成,有些元素的定位方式可能会从 CSS 修改为 ID 定位等其他方式。
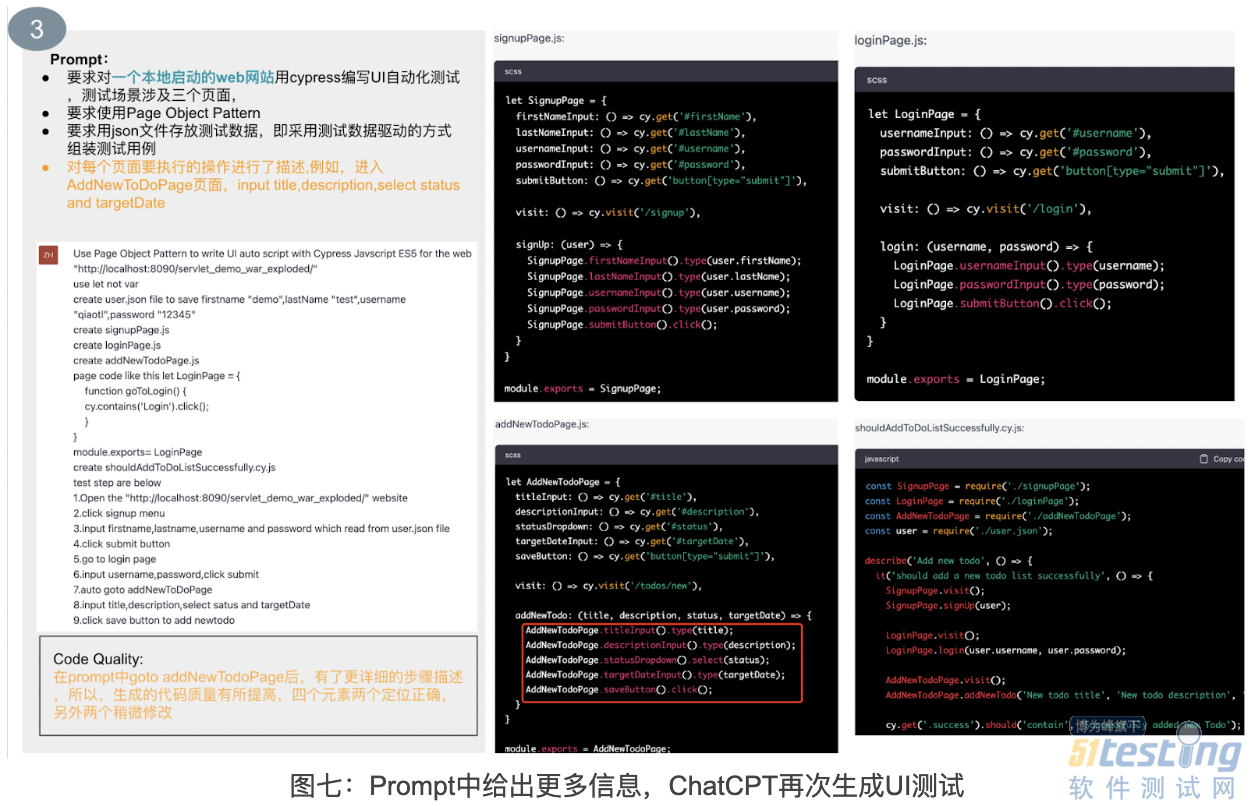
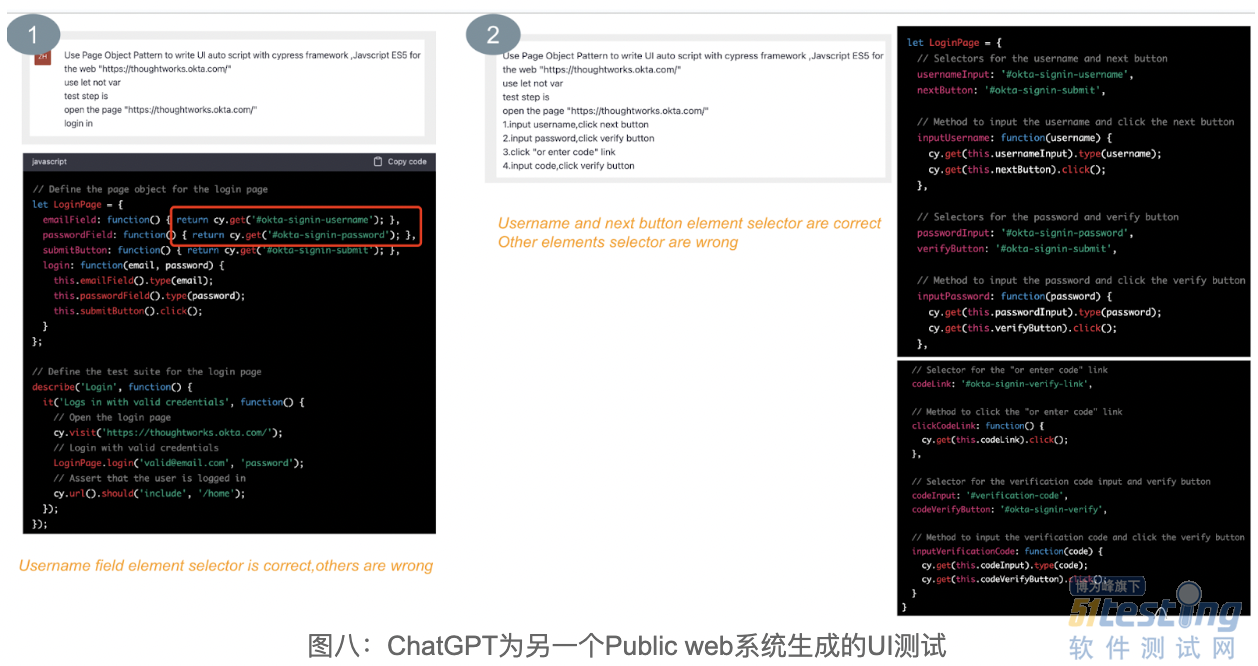
为了进一步验证上面的猜测,我进行了第 3 个实验。在这个实验中,Prompt 中明确告知 ChatGPT 第三个页面需要输入 “title,desc”,选择 “status 和 targetDate”。通过这个信息,ChatGPT 就知道了第三个页面总共有四个需要定位的元素。其中,前两个是 Input 类型的元素,后两个是多选框。对于多选框,生成的代码中,ChatGPT 用 cy.get(“...”).select(“...”) 的方式进行定位。虽然还是没有定位到目标元素,但语法格式正确,与上一次生成的脚本相比,脚本质量有所提高。
从上面的几个实验结果来看,基本证实了 ChatGPT 确实是根据 Prompt 中的信息,猜概率的方式编写 UI 自动化测试,它并不真正知道目标 web 系统的页面结构。但是,如果是猜概率,为什么第一个 public 的 web 系统元素定位正确率这么高呢?难道是 public 的网站定位正确率高,private 的低?
为了解决这个疑惑,我写了另外一个 Prompt,让 ChatGPT 登录我司官网,生成的脚本质量并不高。下面的实验1是让 ChatGPT 登录我司网站,生成的代码中第一个元素定位正确,后面两个均错误。实际系统中,登录首页并没有 password 输入框和 submit 按钮。接着,做了第2次实验,在 Prompt 中描述了更详细的操作步骤,生成的脚本中元素定位正确率依然很低,只是比第 1 次有所提高而已,详细结果如下所示:
同样都是 public 的网站,编写的脚本代码质量差异很大,这说明可能和训练的数据有关。联想到 ChatGPT 基于 github 上的代码做训练,大概率是 github 上有很多 UI 自动化测试代码,用第一个 public 的网站作为测试对象 (备注:我自己就用不同的 UI 测试框架测试过第一个 public 网站,且代码也在 github 上)。所以,如果是某些常见场景,例如打开 google,查找某个信息等,ChatGPT 生成的脚本质量可能较高。反之,如果是内部 web 系统或者新上线的系统,生成的脚本质量就较差。
实际项目中有很多是 ToB 系统,且要求自动化测试和新功能实现同步完成。鉴于 ChatGPT 数据训练来源于 github,如果用 ChatGPT 为实际项目中系统生成 web UI 测试代码,因为页面元素定位正确率很低,故生成的 UI 测试代码帮助很有限。
总结
总的来说,如果一个系统需要后补单元测试,可以考虑借助 ChatGPT 生成单元测试和容器内的集成测试。如果源代码中类的代码行数太多,建议逐个方法输入以生成测试,避免遇到 ChatGPT 单次 tokens 限制。此外,还可以通过任务拆解的方式为项目从0开始构建完善的接口自动化测试。对于 Web UI 自动化测试而言,由于 ChatGPT 无法知道页面的结构,虽然可以生成 UI 自动化测试脚本,但元素定位的准确率很低,对实际项目的帮助很有限。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-5-4 13:41:59
发表于 2023-5-4 13:41:59





 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务