TA的每日心情 | 擦汗
6 小时前 |
|---|
签到天数: 1047 天 连续签到: 5 天 [LV.10]测试总司令
|
1、Wireshark 介绍
Wireshark 是一个功能十分强大的开源的网络数据包分析器,可实时从网络接口捕获数据包中的数据。它尽可能详细地显示捕获的数据以供用户检查它们的内容,并支持多协议的网络数据包解析。
Wireshark 适用于 Windows 和 UNIX 操作系统。它可被用于检查安全问题和解决网络问题,也可供开发者调试协议的实现和学习网络协议的原理。

我们大学阶段上网络课用过,公司阶段如果涉及网络协议开发也会大量用到 Wireshark。
那么,问题来了,能否对 Wireshark 抓包数据进行可视化分析呢?
这引起我极大的好奇和探索欲望,今天带领大家一探究竟。
2、Wireshark 数据可视化可行性与需求分析
主要探讨如下几个问题?
2.1 数据从哪里来?
数据通信(比如:登录 QQ、微信,浏览网页等)都需要大量的数据传输和同步。
从协议层面分为:网络接口层、网络层、传输层、应用层,每一层都有大量的数据。
所以,数据不是问题,数据量也不是问题。
数据量的大小只取决于时间问题。
2.2 数据如何获取?
windows 下的 Wireshark 是可视化查看和分析工具,无法支撑我们获取数据二次处理和分析。
但,Wireshark 后台提供了命令行工具——tshark。
有了tshark 数据获取就“水到渠成”了。
2.3 可视化分析架构如何选型?
“当有了锤子之后,看什么都是钉子”。
我使用 Elastic Stack 比较多,所以天然的依然选型 ELK 。
但,可视化远不止 kibana,比如基于 kibana 的 grafana 也是不错的选择。
·数据落地存储选型:Elasticsearch。
· 数据可视化分析选型:Kibana。
· 数据同步不止一种方案:curl + bulk 批量写入、Logstash、Filebeat 都是可选的方案。
3、Wireshark 数据可视化架构总览
各大组件各司其责,共同完成数据的采集、同步、落地存储和可视乎工作。
Wireshark的 tshark 工具负责网络协议包数据的采集,存储为后缀名为:.pcap 和 json 的文件。
Filebeat或Logstash或curl 实现文件数据的同步。值得一提的是:仅 logstash 能实现中间环节的预处理,借助自带的 filter 插件实现。
Elasticsearch 实现数据存储,数据以 json 文档形式存储到 ES。
Kibana 实现数据可视化。
本文全部实现均基于 ELK 8.X 版本,tshark 使用最新的 4.0.2 版本(2022-12-15最新)。
4、Wireshark 抓包数据采集
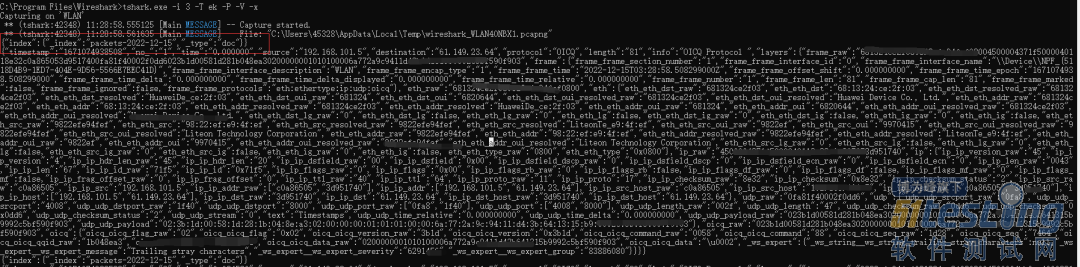
前文分析了tshark 工具的妙处。tshark 新版本更为精妙的提供了支持 ES 数据 bulk 批量导入的格式,如下图所示。
tshark 核心参数含义:
-i:指定网口,linux 下常见的 eth0,windows需要查看获取。
-T:指定包格式,ek 代表 bulk 批量写入 Elasticsearch 的格式。
-j:协议类型,如:"http tcp ip" 分别代表不同的协议类型。
-P、-V:如果 -P 选项与 -V 或 -O 选项一起使用,则摘要行将与详细信息行一起显示。
-x:打印数据包数据的十六进制形式。
数据源也就是抓包的数据对象来自我的宿主机:windows 机器。
tshark windows 下获取网络口的方式:
tshark.exe -D
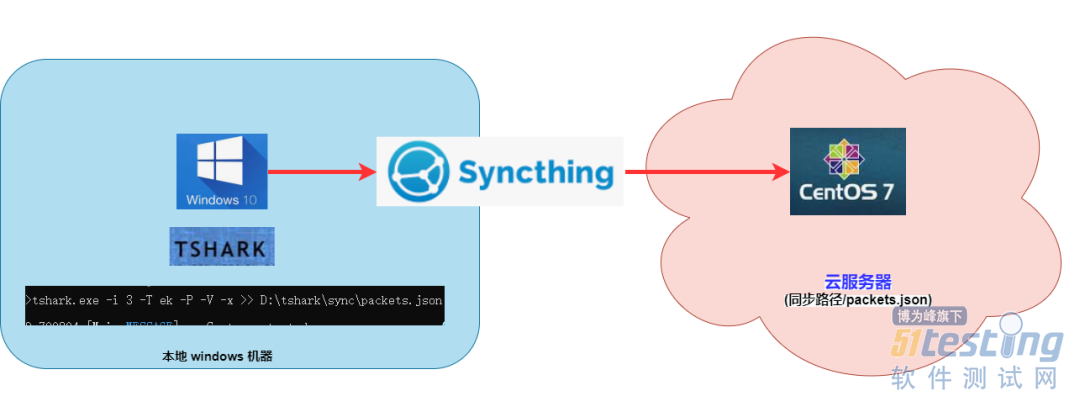
当然这里最快捷的方式就是 tshark 在 windows 机器抓包后写入 json 文件,并借助 logstash 同步 到 Elasticsearch。
但,由于一些特殊原因(版本不兼容等),我通过 synching “曲线救国” 先实现 json 同步,而后借助 logstash 实现 json 数据写入。
tshark 使用参见:https://www.wireshark.org/docs/man-pages/tshark.html
5、Wireshark 数据建模
tshark 抓包简单易用, 但数据字段有数百个。
唯有合理的建模,才能实现准确、高效数据分析和可视化。所以,这一步不能省且很重要。
tshark 提供了指定协议类型并输出 mapping 的功能。这其实为困惑我们的建模拨开了疑云。
tshark -G elastic-mapping --elastic-mapping-filter ip,udp,http,tcp
但,不见得所有字段都是我们想要的。需要结合后面的可视化分析往前追溯建模的合理性。
我们对于核心的几个字段做了建模处理,其他字段忽略,使用了 dynamic:false 特性,数据不被索引和检索,但可以展示。一方面保全的数据的完整性,另一方面极大的方便了建模。
我只对如下几个核心字段建模处理了:
6、Wireshark 数据预处理
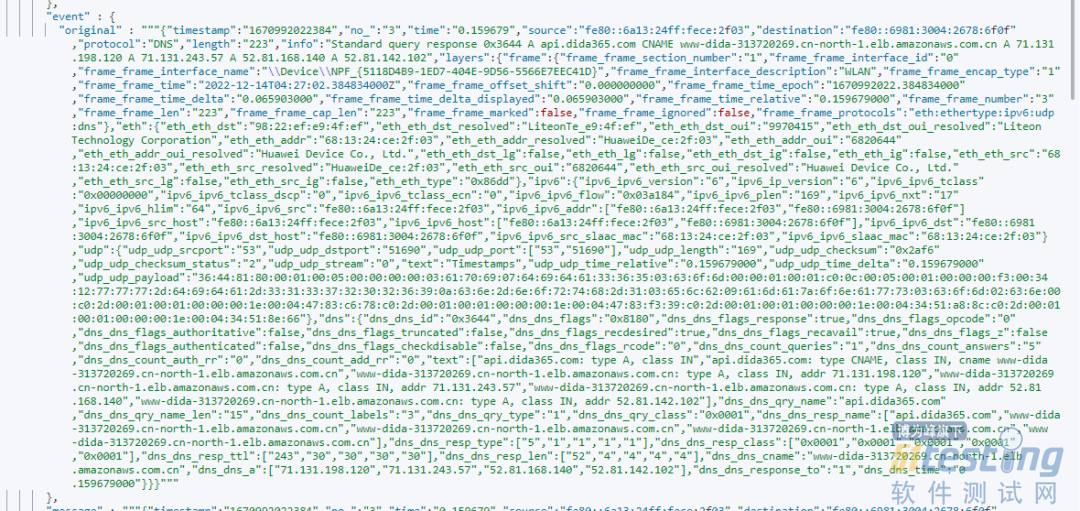
全部导入未经预处理的数据如下所示。
所以数据在写入之前要做一下预处理。
第一,把 json 数据打散。
第二,删除不必要的字段。
第三,增加必要的字段,后续要有地图打点,可以借助 ingest process 实现。
第一,第二等可以借助 logstash 同步中转的 filter 环节实现。
这里强调一下,地图打点需要经纬度信息,咱们的所有数据里面最多到 ip 地址。
这里,需要我们做一下转换,将IP地址转换为经纬度。这一步,Elasticsearch 已经通过 GeoIp processor 集成。
GeoIp processor 根据来自 Maxmind 数据库的数据添加有关 IP 地址地理位置的信息。
默认情况下,GeoIp processor 将此信息添加到 geoip 字段下。GeoIp processor 可以解析 IPv4 和 IPv6 地址。
更多 Maxmind 数据库信息参见:
https://dev.maxmind.com/geoip/geoip2/geolite2/
实现如下:
PUT _ingest/pipeline/geoip_pipeline
{
"description" : "Add geoip info",
"processors" : [
{
"geoip" : {
"field" : "destination",
"ignore_missing": true
}
}
]
}
7、Wireshark 数据写入/数据同步
写入数据的方式如前所述,可以分为三种:
第一:借助 Filebeat 同步 json 文件。
第二:借助 Logstash 同步。
第三:借助 curl 命令行同步写入。
优先推荐:Logstash,因为 Logstash 的"三段论":input、filter、output 更加灵活,插件丰富(绝大多数都已内部集成),支持中间环节的数据处理。
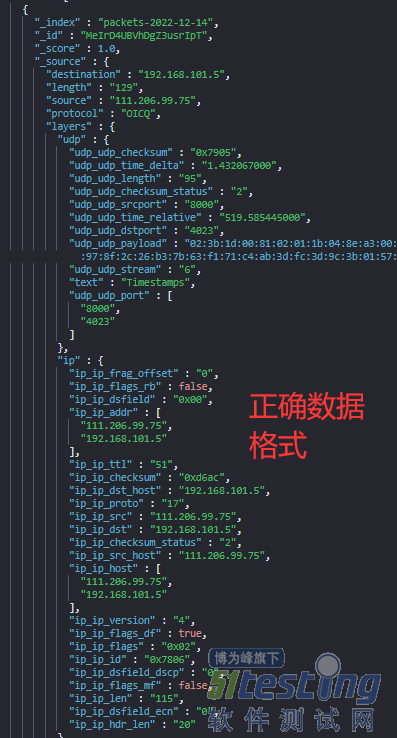
同步完毕后,Elasticsearch 端查看到的数据格式如下。
curl 命令行使用方式如下:
curl -H "Content-Type:application/json" --cacert /elasticsearch-8.1.0/config/certs/http_ca.crt -u elastic:changeme -XPOST "https://111.121.0.114:9200/packets-webserver01-2022-12-14/_bulk" --data-binary "@packes.json"
curl 可能存在的问题,大文件搞不定的问题。制约因素在于 http 请求限制。
解决方案有二:
其一,增大 max_content_length 值(默认值:100mb,这里mb实际是MB意思)。属于静态值,只能在 elasticsearch.yml 中修改且重启后才生效。
http.max_content_length: 500mb
https://www.elastic.co/guide/en/ ... odules-network.html
其二:大文件切割为多个小文件。
举例,linux 环境下将 packets.json 切分为以 20000 行为单位的多个小文件。
split -l 20000 packets.json
8、Wireshark 数据可视化
有了前面的工作,这一步就仅剩工作量了。实战效果如下:
9、小结
大数据就在身边,wireshark 抓一周数据基本磁盘就能爆掉。
中间踩了很多坑,走了不少弯路。比如:tshark 版本问题,tshark 包格式不足以同步问题,数据实时同步工具选型问题,数据精简建模问题等。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-2-20 13:06:43
发表于 2023-2-20 13:06:43










 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务