TA的每日心情 | 无聊
4 天前 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
前天 OpenAI 开放了两个新模型的api接口,专门为聊天而生的 gpt-3.5-turbo 和 gpt-3.5-turbo-0301。
ChatGPT is powered by gpt-3.5-turbo, OpenAI’s most advanced language model.
从上面这句话,我们可以知道现在 chat.openai.com 官网就是由 gpt-3.5-turbo 模型提供的服务,现在官方公开了这一模型的调用接口,这使得我们这些普通开发者也能直接在自己的应用/服务中使用这个狂揽亿万用户的模型。
接下来将和大家介绍如何利用 Python 快速玩转 gpt-3.5-turbo。
本文所有代码已开源,持续更新中:XksA-me/ChatGPT-3.5-AP
先跑起来,再理解
首先你需要有一个 openai 账号,如何注册我就不多说了,网上教程很多,而且很详细,如果有问题可以加我微信:pythonbrief,添加通过后请直接描述你的问题+问题截图。
访问下面页面,登录 openai 账号后,创建一个 api keys。
# api keys 创建页面
https://platform.openai.com/account/api-keys
接下来很简单了,安装 openai 官方的 Python SDK,这里需要注意的是得安装最新版本 openai,官方推荐的是 0.27.0 版本。
pip install openai==0.27.0
直接上请求代码:
import openai
import json
# 目前需要设置代理才可以访问 api
os.environ["HTTP_PROXY"] = "自己的代理地址"
os.environ["HTTPS_PROXY"] = "自己的代理地址"
def get_api_key():
# 可以自己根据自己实际情况实现
# 以我为例子,我是存在一个 openai_key 文件里,json 格式
'''
{"api": "你的 api keys"}
'''
openai_key_file = '../envs/openai_key'
with open(openai_key_file, 'r', encoding='utf-8') as f:
openai_key = json.loads(f.read())
return openai_key['api']
openai.api_key = get_api_key()
q = "用python实现:提示手动输入3个不同的3位数区间,输入结束后计算这3个区间的交集,并输出结果区间"
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "一个有10年Python开发经验的资深算法工程师"},
{"role": "user", "content": q}
]
)
代码解析:
·get_api_key() 函数是我自己写的一个从文件读取 api keys 的方法,我是存在一个 openai_key 文件里,json 格式,你可以改成你自己的获取方法,甚至可以直接写到代码里(虽然不推荐,但确实最简单)。
· q 是请求的问题
· rsp 是发送请求后返回结果
· openai.ChatCompletion.create 中参数
- model 是使用的模型名称,是一个字符串,用最新模型直接设置成gpt-3.5-turbo 即可
- messages 是请求的文本内容,是一个列表,列表里每个元素类型是字典,具体含义如下表:
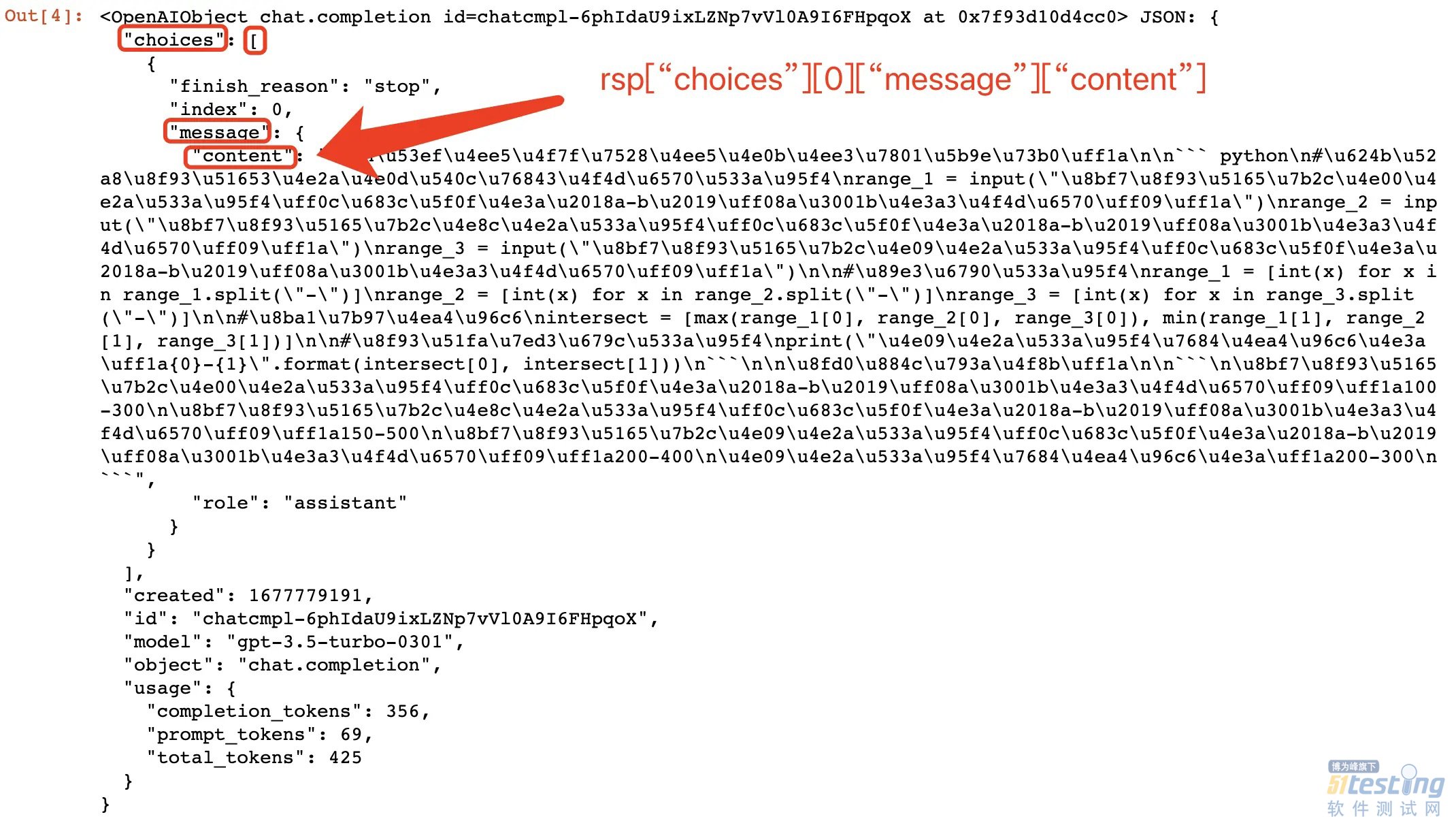
· 程序运行返回内容,从响应回复内容我们可以看到,回复内容是一个 json 字符串。
我们可以通过以下方法直接获取相关信息:
·返回消息内容
rsp.get("choices")[0]["message"]["content"]
· 角色
rsp.get("choices")[0]["message"]["role"]
· 问题+回答总长度
rsp.get("usage")["total_tokens"]
其他信息也可以通过类似方法获取。
· [url=]测试[/url] ChatGPT 回答代码运行情况,可以看出代码逻辑和运行都没啥问题,注释也到位。
实现多轮对话
如何实现多轮对话?
gpt-3.5-turbo 模型调用方法 openai.ChatCompletion.create 里传入的 message 是一个列表,列表里每个元素是字典,包含了角色和内容,我们只需将每轮对话都存储起来,然后每次提问都带上之前的问题和回答即可。
·效果图
可以看到,我首先问了“1+1=几”,然后问“为什么是这样”,ChatGPT 会根据前面的提问将新问题识别为“为什么1+1=2”。
后面继续问水仙花数有哪些,再问“如何写个python程序来识别这些数”,ChatGPT 同样会根据前面的提问将新问题识别为“如何写个python程序来识别这些水仙花数”,并给出对应解答。
实现代码:
import openai
import json
import os
os.environ["HTTP_PROXY"] = "http://127.0.0.1:7890"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:7890"
# 获取 api
def get_api_key():
# 可以自己根据自己实际情况实现
# 以我为例子,我是存在一个 openai_key 文件里,json 格式
'''
{"api": "你的 api keys"}
'''
openai_key_file = '../envs/openai_key'
with open(openai_key_file, 'r', encoding='utf-8') as f:
openai_key = json.loads(f.read())
return openai_key['api']
openai.api_key = get_api_key()
class ChatGPT:
def __init__(self, user):
self.user = user
self.messages = [{"role": "system", "content": "一个有10年Python开发经验的资深算法工程师"}]
self.filename="./user_messages.json"
def ask_gpt(self):
# q = "用python实现:提示手动输入3个不同的3位数区间,输入结束后计算这3个区间的交集,并输出结果区间"
rsp = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=self.messages
)
return rsp.get("choices")[0]["message"]["content"]
def writeTojson(self):
try:
# 判断文件是否存在
if not os.path.exists(self.filename):
with open(self.filename, "w") as f:
# 创建文件
pass
# 读取
with open(self.filename, 'r', encoding='utf-8') as f:
content = f.read()
msgs = json.loads(content) if len(content) > 0 else {}
# 追加
msgs.update({self.user : self.messages})
# 写入
with open(self.filename, 'w', encoding='utf-8') as f:
json.dump(msgs, f)
except Exception as e:
print(f"错误代码:{e}")
def main():
user = input("请输入用户名称: ")
chat = ChatGPT(user)
# 循环
while 1:
# 限制对话次数
if len(chat.messages) >= 11:
print("******************************")
print("*********强制重置对话**********")
print("******************************")
# 写入之前信息
chat.writeTojson()
user = input("请输入用户名称: ")
chat = ChatGPT(user)
# 提问
q = input(f"【{chat.user}】")
# 逻辑判断
if q == "0":
print("*********退出程序**********")
# 写入之前信息
chat.writeTojson()
break
elif q == "1":
print("**************************")
print("*********重置对话**********")
print("**************************")
# 写入之前信息
chat.writeTojson()
user = input("请输入用户名称: ")
chat = ChatGPT(user)
continue
# 提问-回答-记录
chat.messages.append({"role": "user", "content": q})
answer = chat.ask_gpt()
print(f"【ChatGPT】{answer}")
chat.messages.append({"role": "assistant", "content": answer})
if __name__ == '__main__':
main()
代码解析:
ChatGPT 类,包含三个函数:
__init__初始化函数,初始化了三个个实例变量,user、messages、filename(当前用户、消息列表、存储记录的文件路径)。
ask_gpt函数,将当前用户所有历史消息+最新提问发送给 gpt-3.5-turbo ,并返回响应结果。
writeTojson函数,结束/重置用户时记录当前用户之前的访问数据。
main函数,程序入口函数,用户输入用户名后进入与 ChatGPT 的循环对话中,输入 0 退出程序,输入 1 重置用户,退出和重置都会将当前用户之前访问数据记录搭配 json 文件中。
由于 gpt-3.5-turbo 单次请求最大 token 数为:4096,所以代码里限制了下对话次数。
更多拓展
·你可以写个函数,从 json 文件读取历史用户访问记录,然后每次访问可以选用户。
· 你可以写个 web 服务,使用 session 或者数据库支持多用户同时登录,同时访问。
· 你可以基于之前分享的钉钉机器人项目,将 gpt-3.5-turbo 接入钉钉机器人。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-3-10 13:16:25
发表于 2023-3-10 13:16:25







 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务