本帖最后由 八戒你干嘛 于 2017-8-9 12:08 编辑
前言:
在基于基于 Docker 的分布式测试系统构建 (一)中主要阐述了两个方面的内容,分别为开发此分布式测试系统的缘由以及docker基础镜像的构建和踩过的坑。在本篇中主要有4个部分的内容,分别为分布式测试系统的架构、技术实现细节简述、docker Node节点的部署,以及前端实现。
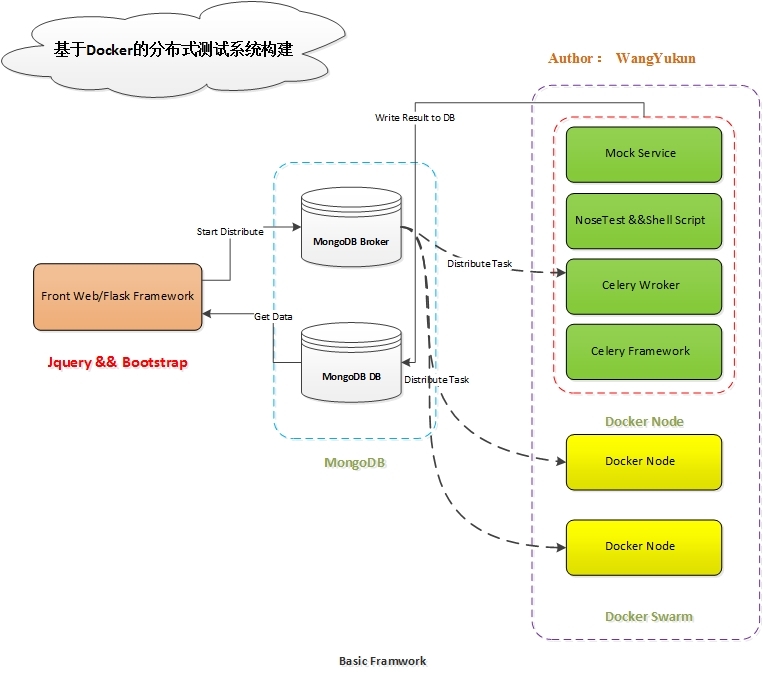
一、分布式测试系统的架构整体的测试架构主要Docker Nodes节点,Mongodb Broker,Mongodb DB, Front Web,这4个部分构成,其实现的架构简图如下所示:
现在就每个部分简要叙述:
1. Docker Node节点简述
Docker Node节点主要有Celery 异步框架,Celery Worker任务,Nosetests 测试框架,Mock服务构成。
其分布式实现主要有Celery来完成,通过编写Celery worker 任务来实现具体的测试逻辑。由于业务逻辑本身的需求情况,分层级的调用关系成为实现的有效途径。Celery Worker从Mongodb Broker接收需要完成的任务信息,然后调用Node节点本身的Nosetests框架和Shell脚本,最后调用Mock Service辅助完成测试任务。Celery Worker完成待定的测试任务后,将测试结果写入MongoBD 数据库中以备前端调用。 2. Docker Swarm
由于本系统的docker node节点并不多,考虑实现成本以及后续管理难易程度,本系统使用Swarm来管理docker node节点。如果docker node节点众多,可以考虑k8s。关于docker swarm在第二部分会进行说明,这里不在叙述。 3. Mogondb
在本系统中,MongoDB主要有两个方面的用途。用途一,作为Celery 的broker,接收前端发送过来的任务请求信息,当broker中有数据时,Celery Worker从broker中获取数据,完成后续任务执行过程;用途二,作为DataBase,Celery worker完成任务后,将result.json数据写入到数据库中 4. 前端实现
由于部门内当前的web系统,使用的是Flask Web框架,所以前端主要由Flask + Jquery + Bootstrap实现
整个架构实现还算比较清晰,这对后期的维护也带来了方便。 二、技术实现有关细节简述1. 关于使用Celery作为异步框架
由于测试用例本身都是基于python来开发的,并且web系统为Flask,所以有充分的理由选择Celery,关于异步框架的选择可以参考基于 Docker 集群的分布式测试系统 DDT (DockerDistributedTest)文章中对异步框架的对比。 2. 关于Nosetests的插件化
默认安装的nosetests是并未安装json插件的,但是提供xml格式。为了便于后续的结果处理,需要事先安装json插件。这里还有一个小插曲,由于之前从来都是使用默认的插件,都不太清楚原来nosetests也可以私自开发插件并安装,走了不少弯路。当然json的插件不需要自己再重复造轮子,可以直接下载安装。 由于nosetests提供了xml格式报告输出,所以第一时间选择的是xml作为最后的结果报文格式。用到--with-xunit参数,同时需要安装nosexunit插件,但是安装的过程中,需要coverage特定版本的支持,为2.85版本。但是即使安装了2.85版本的支持包,https://pypi.python.org/pypi/coverage/2.85也同样会报错。 安装后,使用--with-xunit来运行,会提示如下信息:NameError: global name 'pylint' is not defined。但是pylint已经被正确安装,出现这个错误很是匪夷所思。后来以为是nosexunit的版本的问题,现在安装的是最新版本0.3.3,后来换成0.3.2和0.3.1都会出现错误,暂时还没有发现原因。所以最后还是使用json作为结果输出格式。 3. 关于测试数据以及环境准备
数据更新以及运行相关环境的准备,总体来说可以有两种大的途径,可总结为远程拉取,和本地挂载。 - 远程拉取 远程拉取可以有多种方法,第一种为通过rsync方法,将目的机中的数据远程拉取到docker node中,但是由于运行环境的数据量太大,所以当初认为并不可行。经过统计,在内网中完全拉取大小在5.5G左右的文件夹,需要6分钟左右,这个时间太长了。所以当初这个方案是被废弃了。 第二种方法为使用svn或者git,svn的话对于一些特别大的文件,会提示上传受到限制,这种情况下可以使用svn ignore对某些大的文件进行排除,后来发现由于文件夹太大的原因导致svn报错,使用svn ignore属性同样不能解决问题,现在svn报错也还无法查明原因。 - 本地挂载 通过将所需要的文件传输到docker node宿主机中,然后在运行docker node的时候通过docker -v 本地挂载的形式,可以比较方便的解决环境问题。但是这样会使得部署一个node节点也复杂了一步,必须先同步环境相关数据到docker宿主机,这样又绕回了问题本身。所以本地挂载在本分布式测试系统中并不合适。 所以最后还是要考虑第一个方案。在仔细研究了rsync服务后,发现之前对rsync的研究并不深入,并不清楚rsync的差异性同步模式,通过这篇文章进行了详细的了解,https://segmentfault.com/a/1190000002427568,最后决定使用rsync的方式来进行文件同步。
举例如下: - rsync -auvrtzopgP --progress --delete --exclude "core.*" --exclude "your/log" 192.168.56.73::root/the/des/directory/ ./
- #receiving incremental file list
- #sent 17376 bytes received 2397856 bytes 536718.22 bytes/sec
- #total size is 17239007382 speedup is 7137.62
通过设置--exclude 参数可以将不需要同步的文件排除,比如日志文件,这在实践中很有用 4. 关于分布式系统的执行粒度
在第一篇文章中我有提,现在的分布式系统执行的最小粒度是文件,也就是说nosetests 在运行测试程序时,最小是全部执行某一个文件中所有的case。比如A.py文件中有10个cases,而B.py文件有50cases,那么运行过程是node1运行A.py中的所有case,node2运行B.py中的所有cases。由于A.py中的cases比较少,所以node1运行完成后,就闲置了。而总的运行时间有node2来决定,这种情况下系统的资源被浪费了。 当以casesID作为执行的基本单元时,这种情况就不复存在了,假如运行一个case为1分钟,那么原先需要运行50min才能运行完所有的case。而在现有的执行粒度下,只需要30min就可以运行完所有的case。关于python文件中casesID的收集,可以通过nosetests --collect-only命令来进行收集。 5. 关于Celery worker的命令
由于每一个cases的运行都需要Mock Service的支持,其主程序在内存中只允许运行一个实例,所以每一个docker node节点每次只可以运行一个case,否则便会相互影响。在解决这个问题的时候走了不少弯路,后来在仔细研究了celery worker的命令后,发现可以通过celery worker的运行时参数就可以控制,当时便有一个柳暗花明又一村的感觉。
举例如下: - celery -A pc_ads_distribute_worker worker -c 1 --maxtasksperchild=1 -l INFO
其中的-c参数表示worker并发为1,--maxtasksperchild表示每一个worker最多有几个孩子,同样设置为1,这样就可以满足具体业务测试要求了
| 







 /2
/2 

 关于我们
关于我们





 发表于 2017-8-9 11:44:13
发表于 2017-8-9 11:44:13


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务 楼主
楼主
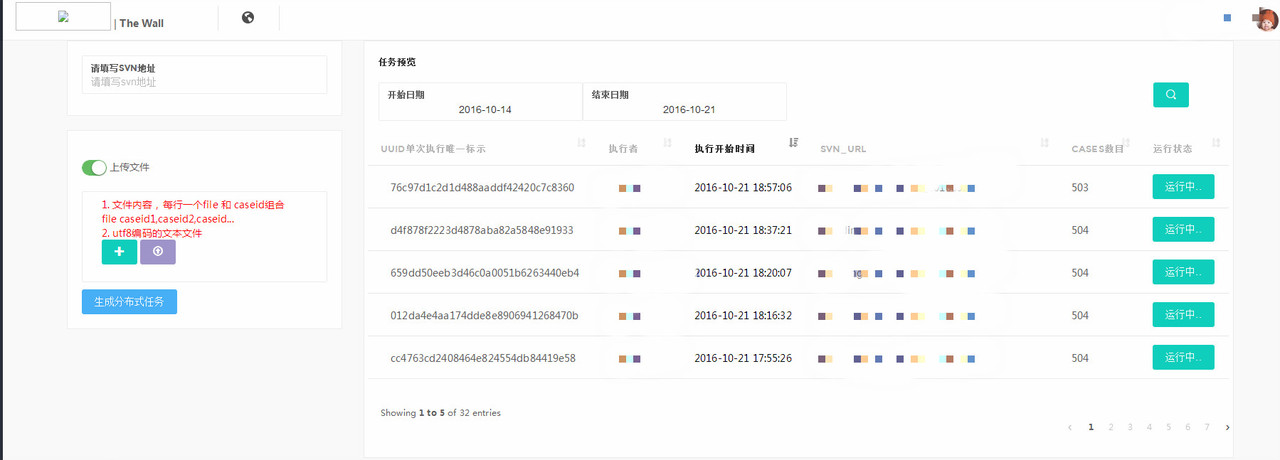
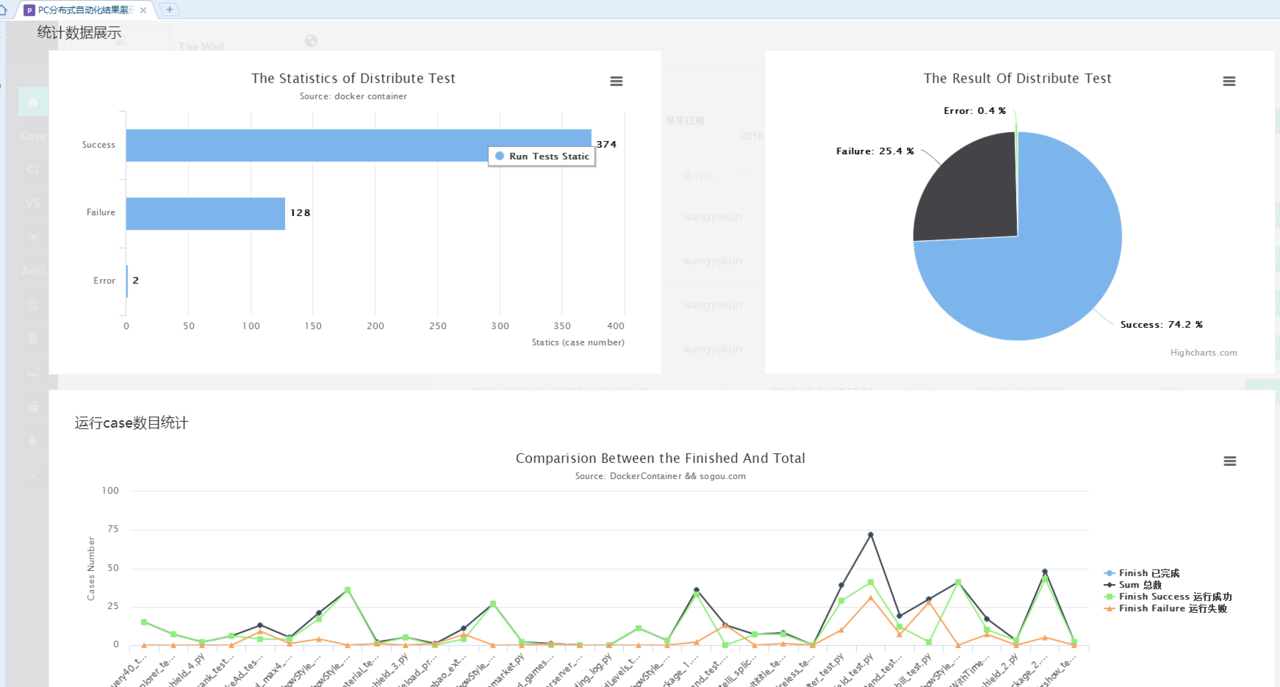
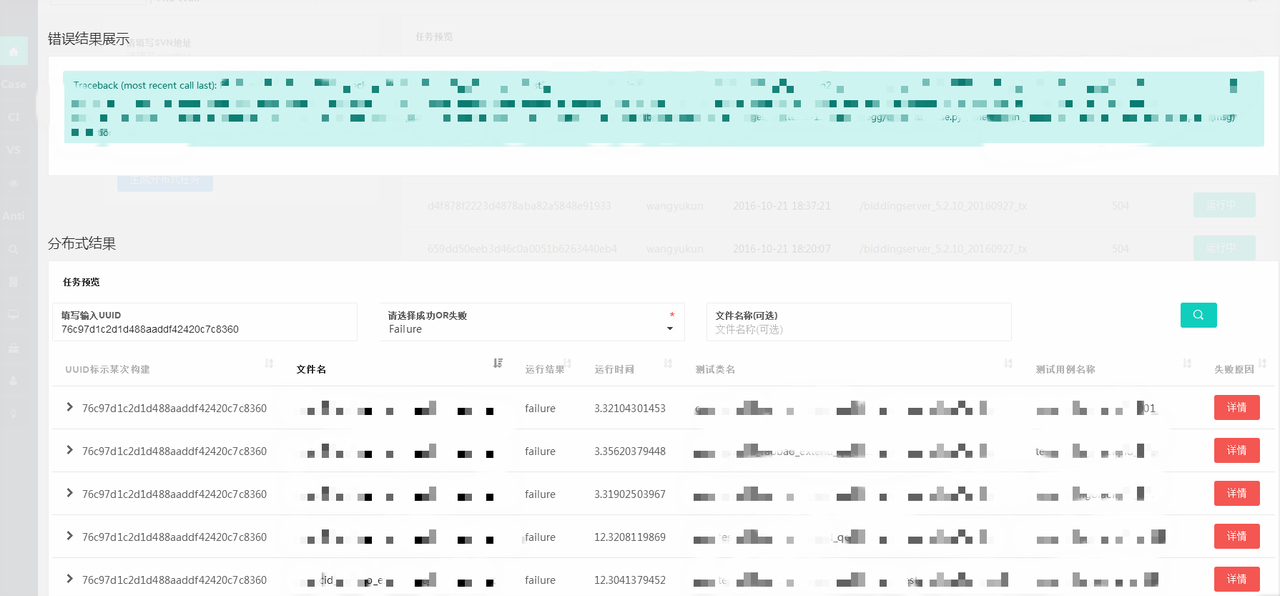

 发表于 2017-8-13 12:37:36
发表于 2017-8-13 12:37:36


