TA的每日心情 | 无聊
14 小时前 |
|---|
签到天数: 1050 天 连续签到: 1 天 [LV.10]测试总司令
|
数据采集
我们上一篇介绍了,如何采集王者最低战力,本文就来给大家介绍如何采集王者皮肤,买不起皮肤,当个桌面壁纸挺好的。下面,我和大家介绍如何获取数据。
确定网址
我们在对王者英雄的主页,进行了分析,我们发现,其网页地址相似,就差一个数字。
https://pvp.qq.com/web201605/herodetail/{ename}.shtml
我们可以把它当作为每个英雄的编号,我们可以从英雄列表获取编号,不过,这里我们直接请求第三方接口数据。
获取英雄编号
html_url ='https://www.sapi.run/hero/getHeroList.php'
datas = requests.get(html_url).json()['data']
for data in datas:
ename = data['ename']
cname = data['cname']
print(ename,cname)
这段代码中,html_url?是一个 URL,指向一个 SAPI 的 Hero 列表页面。requests.get(html_url).json()['data']?返回一个 JSON 对象,其中包含了 Hero 列表页面的数据。ename?和?cname?是 JSON 对象中的两个键值对,分别表示 Hero 的编号和名字。
在这段代码中,我们使用了一个?for?循环来遍历 JSON 对象中的每一个键值对,并打印出它们的值。这样就可以得到 Hero 列表页面中所有 Hero 的编号和名字。
获取皮肤名称
我们拿到每一个英雄的编号之后,我们就可以访问每一个英雄的主页,我们在其主页可以看到他们的英雄名称和他们的英雄皮肤的地址。我们先获取英雄皮肤的名称。
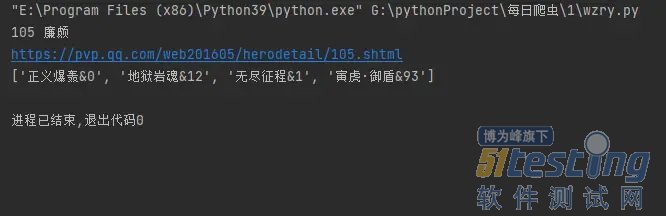
herodetail_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'
print(herodetail_url)
res = requests.get(herodetail_url,headers=headers)
res.encoding = 'gbk'
# print(res.text)
pfs = re.findall('data-imgname="(.*?)"',res.text)[0]
pfs=pfs.split('|')
print(pfs)
这段代码中,herodetail_url?是一个 URL,指向一个 Hero 详细页面。requests.get(herodetail_url,headers=headers)?返回一个 JSON 对象,其中包含了 Hero 详细页面的数据。res.encoding = 'gbk'?设置了 JSON 对象的编码方式为 GBK。re.findall('data-imgname="(.*?)"',res.text)[0]?使用正则表达式匹配 Hero 详细页面中的英雄名称,并返回第一个匹配项。pfs?是匹配项的值,它是一个包含英雄名称的列表。
接下来,我们对字段进行处理。
for pf in pfs:
pf = pf.split('&')[0]
# print(pf)
pf_list.append(pf)
print(len(pf_list))
print(pf_list)
我们得到了这样的数据。['正义爆轰', '地狱岩魂', '无尽征程', '寅虎·御盾'],到了这里,我们皮肤名字就获取下来了。
获取皮肤
pages = len(pfs)
for page in range(1,pages+1):
pf_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{page}.jpg'
pf_url_list.append(pf_url)
这段代码中,我们首先计算出 Hero 详细页面中图片的数量,然后使用range函数生成从 1 到pages的整数序列。接下来,我们使用一个循环来遍历这个序列,并将每个图片的 URL 添加到pf_url_list列表中。
最后,我们将pf_url_list列表中的所有 URL 连接起来,并将它们作为参数传递给requests.get()?函数,以获取 Hero 详细页面的数据。
到这里,我们把所有皮肤的地址获取了下来。
保存数据
for name,url in zip(pf_list,pf_url_list):
path = f'.//皮肤//{cname}//'
# print(path)
if not os.path.exists(path):
os.mkdir(path)
# print(cname,name,url)
pf_save = requests.get(url,headers=headers)
print(f"path + '{name}.jpg'")
with open(path + f'{name}.jpg', 'wb') as f:
f.write(pf_save.content)
这段代码中,我们首先将pf_list和pf_url_list两个列表进行了zip操作,并将结果存储在pf_list和pf_url_list两个变量中。然后,我们使用os.path.exists()函数来检查path目录是否存在,如果不存在,则使用os.mkdir()函数创建该目录。接下来,我们使用requests.get()函数来获取pf_url_list列表中的每个 URL,并将它们作为参数传递给requests.get()函数,以获取pf_list列表中的每个 URL。
最后,我们使用with open()语句打开path + '{name}.jpg'文件,并将pf_save.content写入该文件中。这样就可以将pf_list和pf_url_list中的每个 URL 保存到path + '{name}.jpg'文件中。
总结
这是一篇关于如何采集王者皮肤的文章,介绍了如何从英雄列表获取编号,并使用正则表达式从网页地址中提取英雄编号和名字。此外,还介绍了如何使用 requests.get() 函数从网页中获取数据,以及如何将数据保存到文件中。
|
|








 /1
/1 

 关于我们
关于我们





 发表于 2023-4-18 13:14:16
发表于 2023-4-18 13:14:16


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务