|
煮酒论数据——谈分布式测试体系构建
出处:淘测试 作/译者:凡提
自谷歌提出云计算概念之后,大数据领域的发展就逐渐加速日新月异,云计算具体到实例,可以归纳为调度、均衡、容错、监控、运维等一整套操作海量数据的方案。有别于传统小规模或孤立体系产品,云计算生态圈存在错综复杂的系统级别关联,并行其中的不同架构和模块流转于超大规模的分布式软硬体资源中,很难划分出明显的界限。对于这样的产品体系,传统领域的测试方案要么逐渐失效,要么作用域缩减到仅能覆盖体系末端。为了保证大数据平台的可靠性、稳定性和高性能,亟需构建一套与之相匹配的测试体系来衡量产品是否合格。
存在的问题 业界在大数据测试领域的探索始终没有停止过,以hadoop生态圈为例,与之相关的各类测试工具自成一体,例如Hadoop本身通过mock出MiniCluster(包括MR和HDFS)用来为开发代码做功能验证,DFSIO/Slive等用来做压力和性能测试;HBase则通过一系列模拟随机/顺序读写相关的工具来做性能测试。而我们自己的ODPS则通过HiveUT来完成功能覆盖和有限的性能验证。仔细梳理这些工具不难发现存在一些问题,列举如下: 1. 这些独立的测试工具和体系很难被其他产品复用,比如说验证hadoop功能的MiniCluster上是不能搭建HBase的,也不能跑Hive。MR输出的默认Counters很难在HBase的测试调优中发挥作用。 2. 各种工具之间对比性较差,例如DFSIO和Slive的输出结果几乎没有什么关联性;还有的时候同一个工具测不同版本,判断耗时、资源占用状况几乎相同,实际上某些第三方指标出现了变化,工具却不能很好的反映出来。 3. 各种工具自身的运行效率无评判标准,被测目标无第三方监控依据。缺乏系统的绘制性能趋势图的能力。 4. 传承性不够,跨产品使用的可能性较小,例如HBase的测试中,很少对HDFS的性能做一个预判,原因是相关的人员缺乏对HDFS体系的了解,对其工具可起到的测试作用缺乏理解。 5. 工具易用性较差,几乎所有类似独立体系工具由于想在广度上覆盖尽量多的应用场景,因此使用了大量的参数用于配合用户不同的测试目的。 6. 此类工具往往依赖产品自身架构来进行相关测试,缺乏完全独立于产品本身的第三方验证方式,如果产品相关联部分发生了变动,要么造成基于老版本的工具失效,要么可能会影响到测试结果的准确性。 诸如以上所述的问题,几乎存在于大数据测试领域的每一个角落,对于阿里数据平台的相关产品来说,随着时间的推移规模的扩大和业务的日渐繁忙,测试上的这些缺陷越来越无法容忍,构建一套与之匹配的分布式测试框架体系就成为了必经之路。为了构造这样一个测试体系,分布式测试框架与集群管理(DST)于2012年初应声而出,从雏形开始一步步构造成为如今拥有数十个页面、数万次构建、数千测试场景和报告,既可以应对复杂业务场景,也可以满足小版本单一功能快速集测需求的自动化测试框架体系。
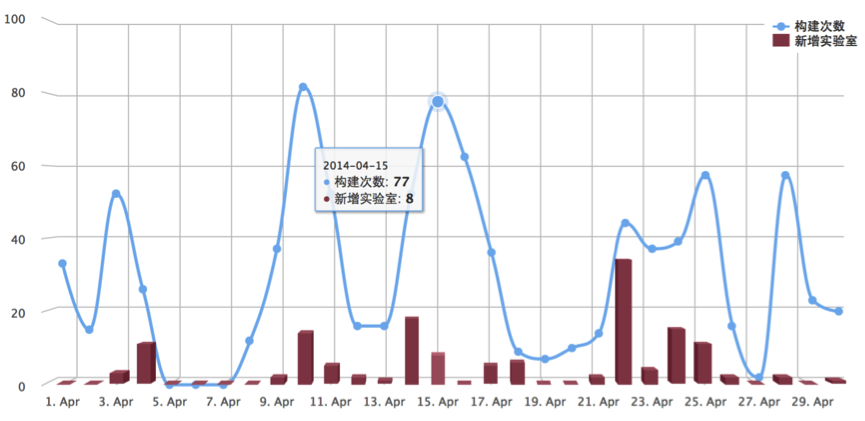
历史溯源 解决上述存在的问题,构造与之匹配的测试体系,就要从分布式测试框架与集群管理(DST)的历史说起,因为DST的发展过程恰恰正是解决上述问题的轨迹。以下是里程碑级别事件的时间线: 2012年1月,DST开始立项,第一行代码提交版本控制 2012年3月,场景管理(用于构造测试用例)和实验室管理(用于调度执行测试)制作完成 2012年4月,指标配置器和指标计算模板配置功能完成 2012年5月,第一次执行从场景到调度,如今可供查阅这份古老的测试报告:隐藏 2012年5月,ganglia监控数据导入HBase成功,可供查阅第一份有监控数据的测试报告:隐藏 2012年7月,生成集测报告功能上线,最古老的一份集测报告:隐藏 2012年7月底,三线(BI线、广告线、搜索线)回归纳入DST调度体系,首次实现业务线自动化回归 2012年8月,实现基线对比功能,多个版本测试结果可自动进行趋势对比 2012年11月,数据魔方业务线回归纳入DST调度体系(由于对比工具的复杂性导致纳入体系的难度很大) 2013年1月,DST接入Kelude体系使用kelude接口进行用户认证管理和通知等功能 2013年2月,实现测试报告评审体系,通过工具引导流程,迫使测试报告必须通过开发、运维、测试的三方会审 2013年上半年,随着云梯1跨机房项目启动,DST最高接受超过7000台机器的平均每台150多个监控指标的同时导入 2013年3月,配置管理上线,海量测试资源首次实现图形化调度管理 2013年12月,优化监控指标查询系统,将分级查询耗时优化到秒级查询耗时 2014年2月,集群管理上线,用户可以自由分配测试资源组装自己的测试集群,其中云梯1产品更实现了一键自动化部署
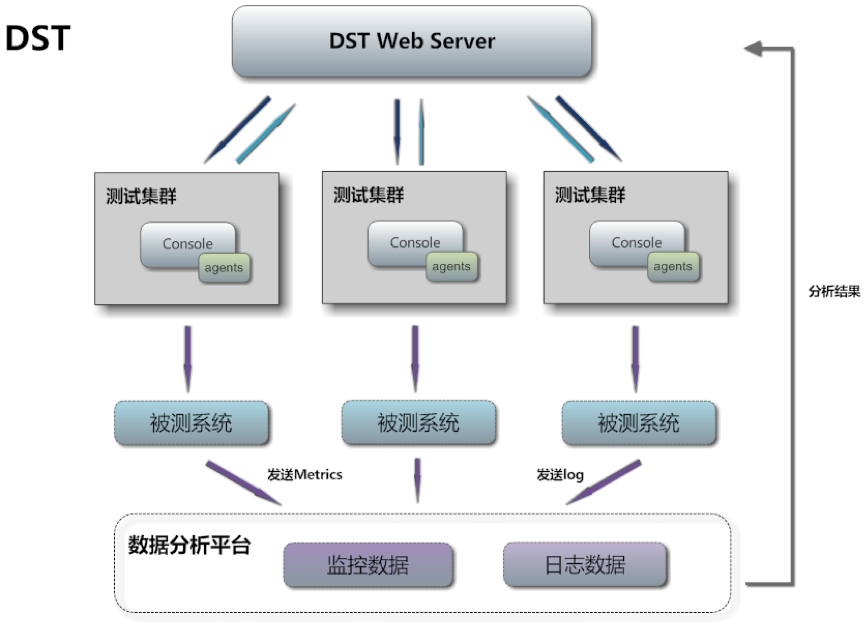
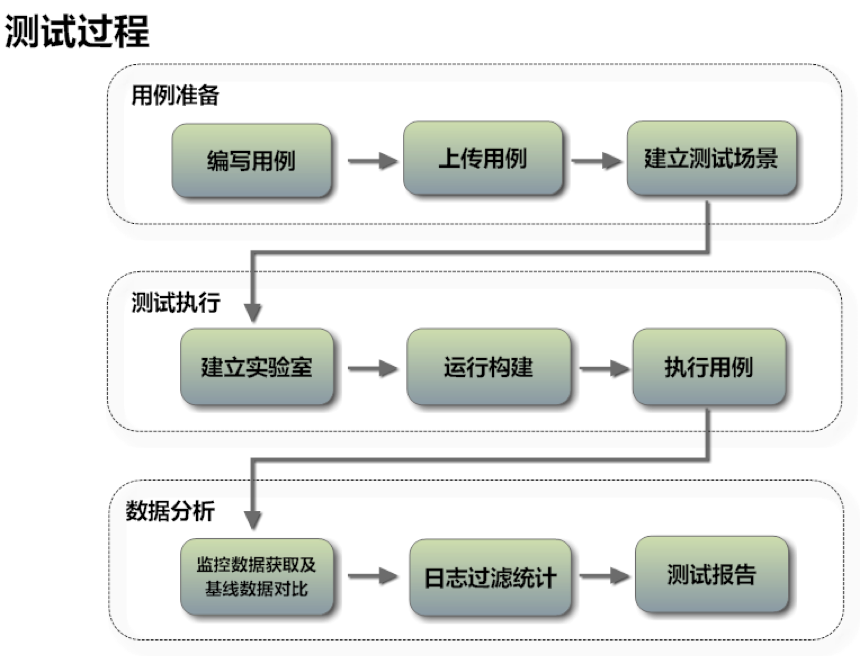
综上所述,最终构造成功的体系与架构可以从下面几张图来看: 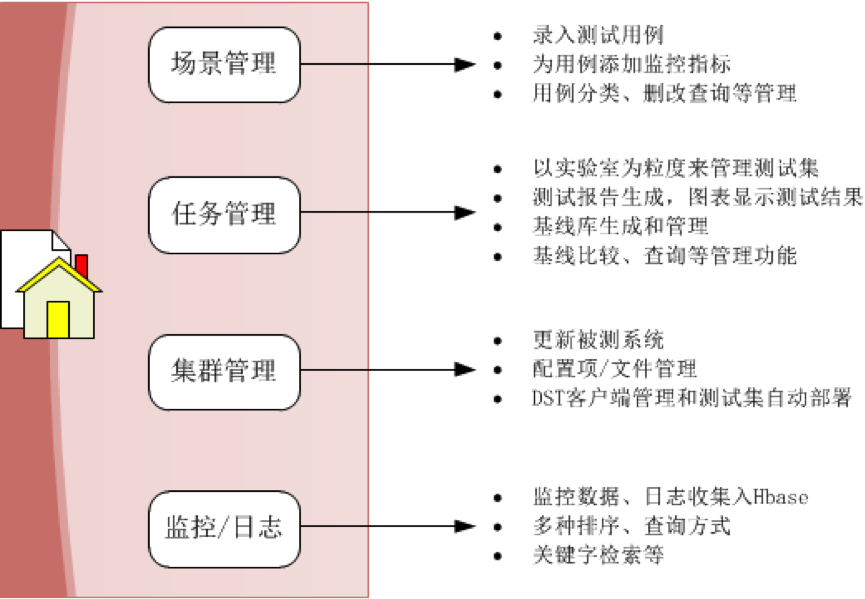
| 







 /1
/1 

 关于我们
关于我们





 发表于 2015-1-9 11:53:42
发表于 2015-1-9 11:53:42


 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 微信
微信 收藏
收藏 置顶服务
置顶服务 换色服务
换色服务 楼主
楼主