标题: 这些SQL 题大部分人答不出来,我保证! [打印本页] 作者: lsekfe 时间: 2023-6-12 10:38 标题: 这些SQL 题大部分人答不出来,我保证! 周末的时候,一个读者问了我一个很有意思的问题,是关于 MySQL 中 update 加锁的问题。
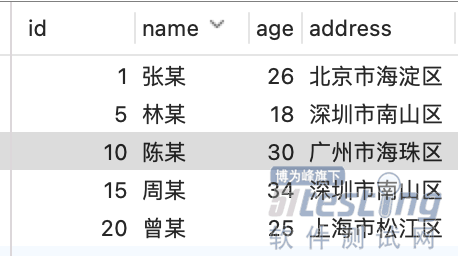
他用下面这张数据库表,做了个 MySQL 实验的时候。
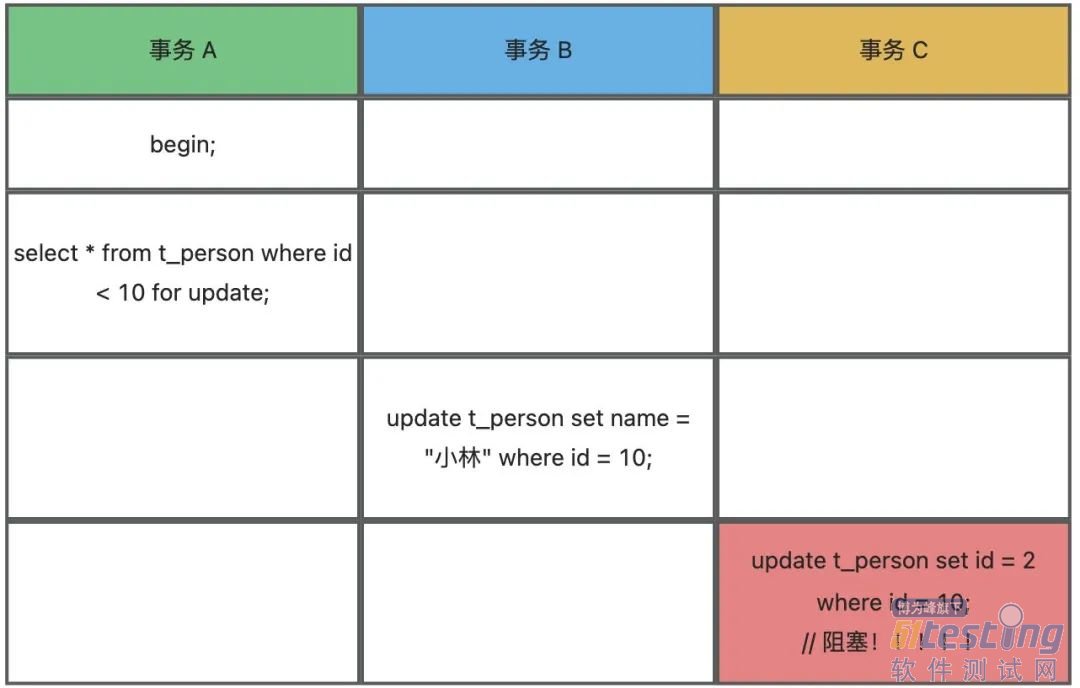
发现事务 B 的 update 不会阻塞,而事务 C 的 update 会阻塞,都是对 id = 10 这条记录进行 update, 为什么一个会阻塞,一个不会阻塞?
首先,我们先来分析下,事务 A 这条 SQL 加了什么锁。
// 事务 A
select * from t_person where id < 10 for update;
我直接说结论,事务 A 加了这三个行级锁:
在 id 为 1 的主键索引上,加了 X 型的 next-key 锁,范围是 (-∞,1]。意味着,其他事务无法对 id = 1 的记录进行删除和更新操作,同时无法插入 id 小于 1 的新记录。
在 id 为 5 的主键索引上,加了 X 型的 next-key 锁,范围是 (1, 5]。意味着,其他事务无法对 id = 5 的记录进行删除和更新操作,同时无法插入 id 为 2、3、4 的新记录。
在 id 为 10 的主键索引上,加了 X 型的间隙锁,范围是 (5, 10)。意味着,其他事务无法插入 id 为 6、7、8、9 的新纪录。
PS:如果你不清楚什么是 MySQL 这些行级锁(记录锁、间隙锁、next-key 锁),以及不清楚行级锁的加锁规则。。
事务 B 的 update 语句为什么不会阻塞?
事务 B 的 update 语句是对 id = 10 的行记录的 name 字段进行更新。
// 事务 B
update t_person set name = "小林" where id = 10;
事务 B 会在 id = 10 的主键索引上加 X 型记录锁,仅锁住这一行。因为当我们用唯一索引进行等值查询的时候,查询的记录是「存在」的,在索引树上定位到这一条记录后,该记录的索引中的 next-key 锁会退化成「记录锁」。
事务 A 并没有对 id = 10 的主键索引上加 X 型记录锁,而是对 id = 10 的主键索引上加 X 型间隙锁。间隙锁和记录锁之间是没有互斥关系的,所以事务 B 的 update 语句不会阻塞。
事务 C 的 update 语句为什么会阻塞?
事务 C 的 update 语句是将 id = 10 的行记录的 id 更新为 2。
// 事务 C
update t_person set id = 2 where id = 10;
这条 update 很特殊,特殊之处在于更新了主键索引。你以为它只是一个更新操作,实际上它在背后执行了两个操作:
操作 1:delete from t_person where id = 10;
操作 2:insert into t_person (2, 陈某, 30, 广州市海珠区);
也就是先删除 id = 10 的记录,然后再插入 id = 2 的新纪录。
为什么当 update 语句更新了索引值,会被拆分成删除和插入操作?
要回答这个问题,我们先要清楚 B+ 树的特点。
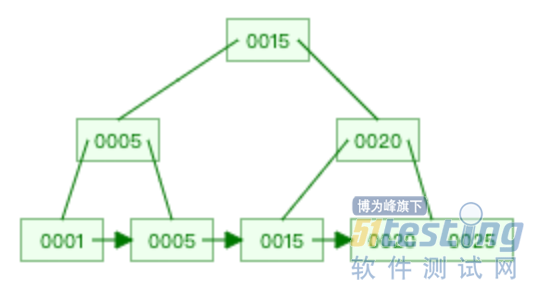
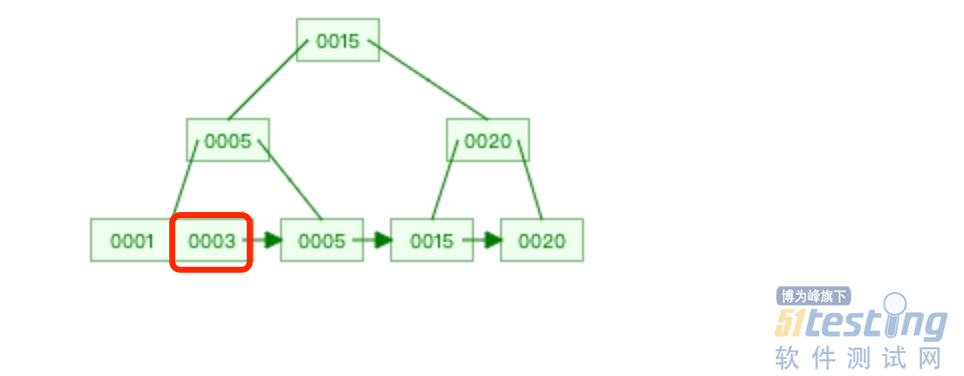
Innodb(MySQL 存储引擎)在实现索引的时候,采用的数据结构是 B+ 树。B+ 树是基于二分查找树演变过来的,所以 B+ 树在存储索引的时候,是按顺序存储的,因为这样才能利用二分查找快速检索到索引。
现在有一颗这样的 B+ 树,可以看到叶子节点的索引值是从小到大的顺序。
事务 C 的 update 语句具体阻塞在哪个「操作」?
现在我们知道,事务 C 的 update 特殊语句背后执行了两个操作,分别是删除和插入操作,那具体是阻塞在哪个「操作 」?
「操作 1 」是删除 id = 10 的记录,事务 C 是会在 id = 10 的主键索引上加 X 型记录锁,而事务 A 并没有对 id = 10 的主键索引上加 X 型记录锁,而是对 id = 10 的主键索引上加 X 型间隙锁。间隙锁和记录锁之间是没有互斥关系的,所以「操作 1 」不会阻塞。
根据排除法,既然 「操作 1 」不会阻塞,那事务 C 的 update 语句阻塞的原因就是因为 「操作 2」发生了阻塞。
为什么「操作2」会发生阻塞呢?
我们先要知道,插入操作什么时候会发生阻塞:插入语句在插入一条新记录之前,需要先定位到该记录在 B+树的位置,如果插入的位置的下一条记录的索引上有间隙锁,此时会生成一个插入意向锁,然后锁的状态设置为等待状态,现象就是插入语句会被阻塞。
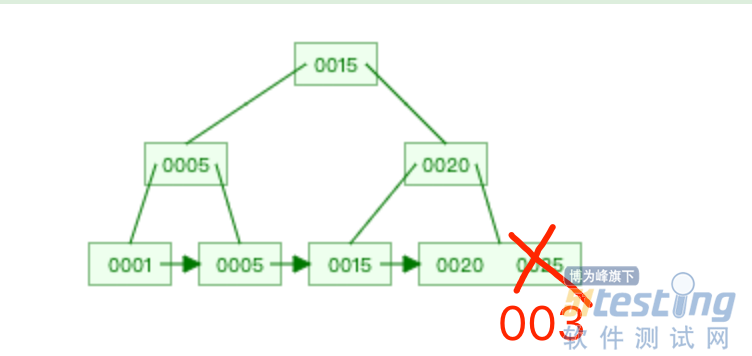
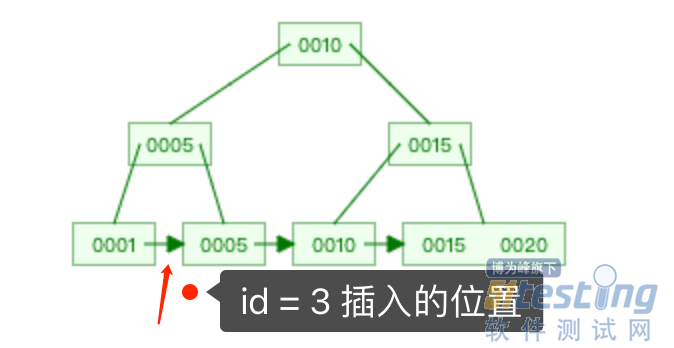
「操作 2」插入的是 id = 2 的新记录,在主键索引的 B+树定位到插入的位置如下图。
插入位置的下一条记录是 id = 5 的记录,而事务 A 在 id 为 5 的主键索引上已经加了 X 型的 next-key 锁,这里面包含了间隙锁。所以「操作 2」的插入操作会发生阻塞,这就是事务 C 的 update 语句阻塞的原因。
从这我们也可以知道间隙锁的作用,就是阻止其他事务在间隙锁的范围内插入新记录,从而避免可重复读隔离级别下幻读的现象。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句,查看事务 C 在加什么锁的时候导致阻塞。
从上面的输出信息,可以看到事务 C 在加「插入意向锁」的时候,发生了阻塞。
插入意向锁是插入操作才会有的锁,而事务 C 只是执行 update 语句,却出现了插入意向锁,从这里也可以证明,事务 C 这条特殊的 update 语句运行的时候,被拆分成了两个操作,一个是删除,另一个是插入。
总之,如果 update 语句更新的是普通字段的值,就会对发生更新的记录加 X 型记录锁。
但是,如果 update 语句更新的是索引的值,那么在运行的时候会被拆分成删除和插入操作,这时候分析锁的时候,要从这两个操作的角度去分析。
完啦!
怎么样,够不够细节?