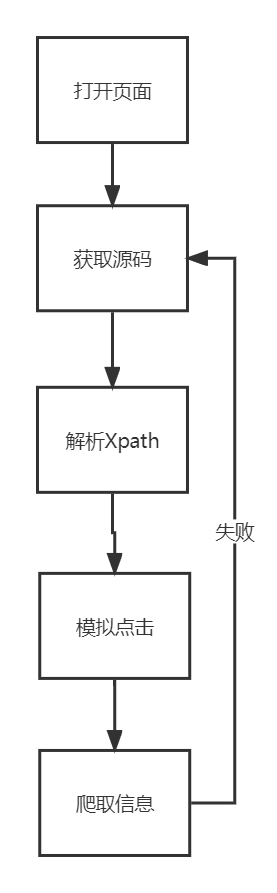
for province_id in range(0,32):
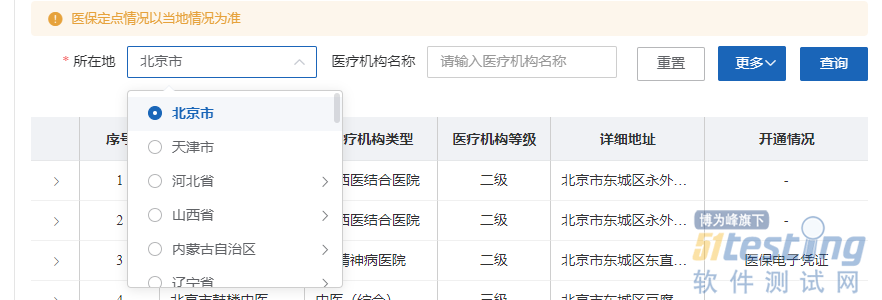
change_province(driver,province_id) #顺序切换省市
max_page=driver.find_element(By.XPATH,'//*[@id="app_main"]/div/div[2]/div/ul/li[6]').text #获取最大页数
max_page=int(max_page)
data=get_info(driver) #获取第一页的数据
for i in range(0,max_page-1):
next_page(driver)
data_1=get_info(driver)
data.extend(data_1)