1.1 selenium的使用
1、爬虫开始,先将需要的模块包导入:
from selenium import webdriver # 模拟真人操作网页
import pyquery as pq # 解析网页
import time # 时间模块
import os # 文件模块
import pandas as pd
from selenium.webdriver.chrome.service import Service # 新增
from selenium.webdriver.common.by import By
2.避免乱码,在py文件的最上面,加入utf-8编码,显示中文。
# coding = utf-8
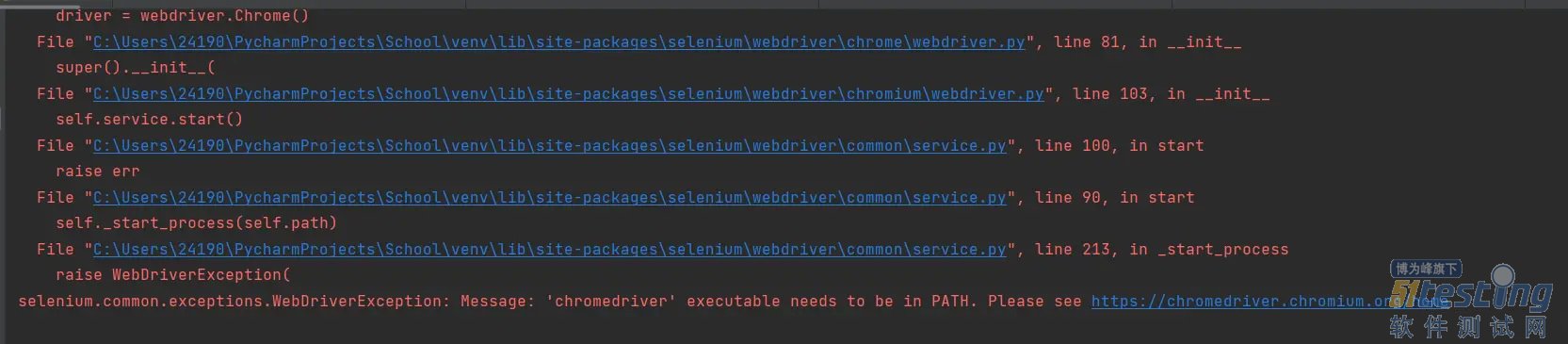
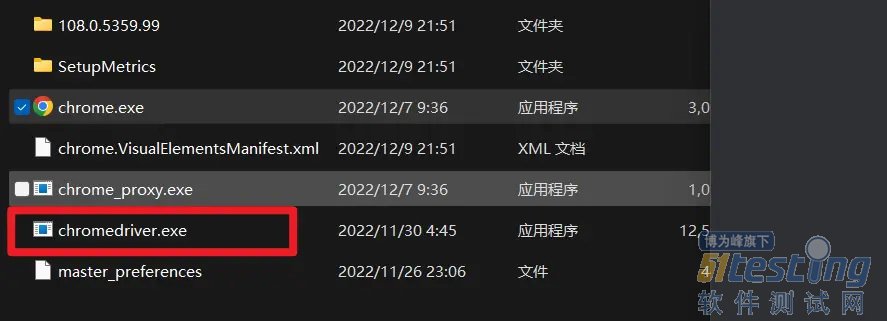
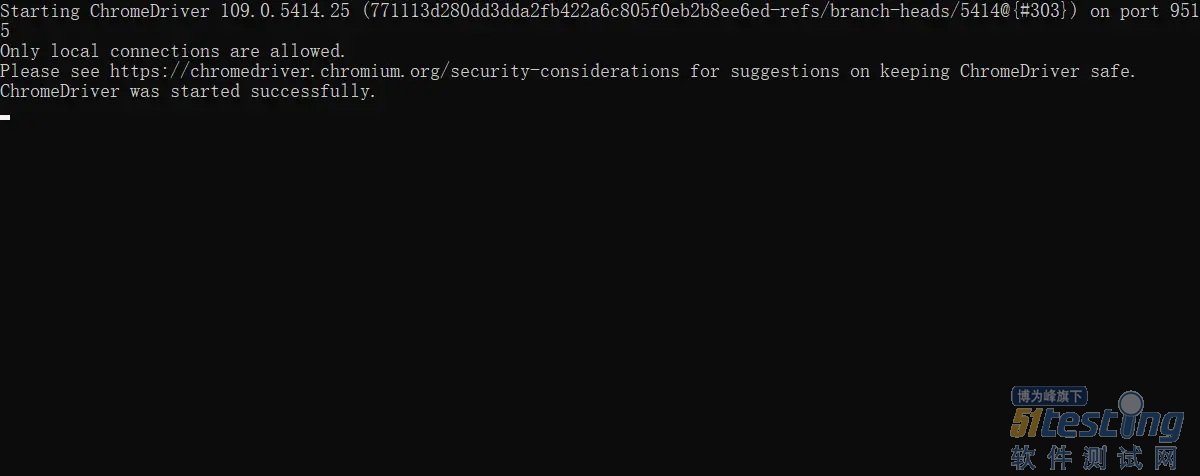
3.将谷歌的chromedriver的路径写一下,如果没有chromedriver的话,去官网下载一下,下载解压,将chromedriver拖拽到谷歌游览器的目录即可。
service = Service(executable_path='/home/yan/Python/chromeselenium/chromeselenium/chromedriver')