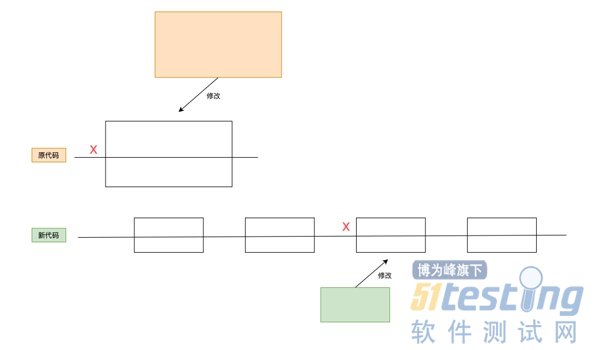
把原来放在一个函数中实现的多个步骤拆分成为多个更小的函数,每个函数只做一件事。当数据源发生变化时,只需要改动 get_source 相关的代码即可;如果网络请求返回的数据不符合最终要求,我们可以在 trim 函数中对它进行修剪。这样一来,代码应对变化的能力提高了许多,整个流程也变得更清晰易懂。改动前后的变化如下图所示:
单一职责原则的核心是解耦和增强内聚力,如果一个函数承担的职责过多,等于把这些职责耦合在一起,这种耦合会导致脆弱的设计。当发生变化时,原本的设计会遭受到意想不到的破坏。单一职责原则实际上是把一件事拆分成多个步骤,代码修改造成的影响范围很小。 让代码稳定性飞升的开放封闭原则和依赖倒置原则
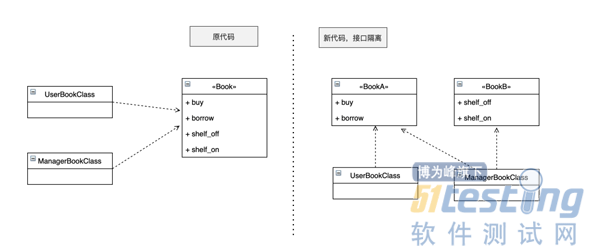
开放封闭原则中的开放指的是对扩展开放,封闭指的是对修改封闭。需求总是变化的,业务方这个月让你把数据存储到 MySQL 数据库中,下个月就有可能让你导出到 Excel 表格里,这时候你就得改代码了。这个场景和上面的单一职责原则很相似,同样面临代码改动,单一职责原则示例主要表达的是通过解耦降低改动的影响,这里主要表达的是通过对扩展开放、对修改封闭提高程序应对变化的能力和提高程序稳定性。
稳定这个词如何理解呢?
较少的改动或者不改动即视为稳定,稳定意味着调用这个对象的其它代码拿到的结果是可以确定的,整体是稳定的。
按照一般程序员的写法,数据存储的代码大概是这样的: