








| from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support.expected_conditions import presence_of_element_located import time import re import subprocess import os # selenium调用 options = webdriver.ChromeOptions() # 编码格式 options.add_argument('lang=zh_CN.UTF-8') # 等待浏览器DOMContentLoaded事件 options.page_load_strategy = 'eager' # 无头模式启动 # options.add_argument('--headless') # 谷歌文档提到需要加上这个属性来规避bug options.add_argument('--disable-gpu') options.add_argument('blink-settings=imagesEnabled=false') browser = webdriver.Chrome(options=options) wait = WebDriverWait(browser, 10) |
| browser.get("https://tongbu.eduyun.cn/tbkt/tbkthtml/1.html") |
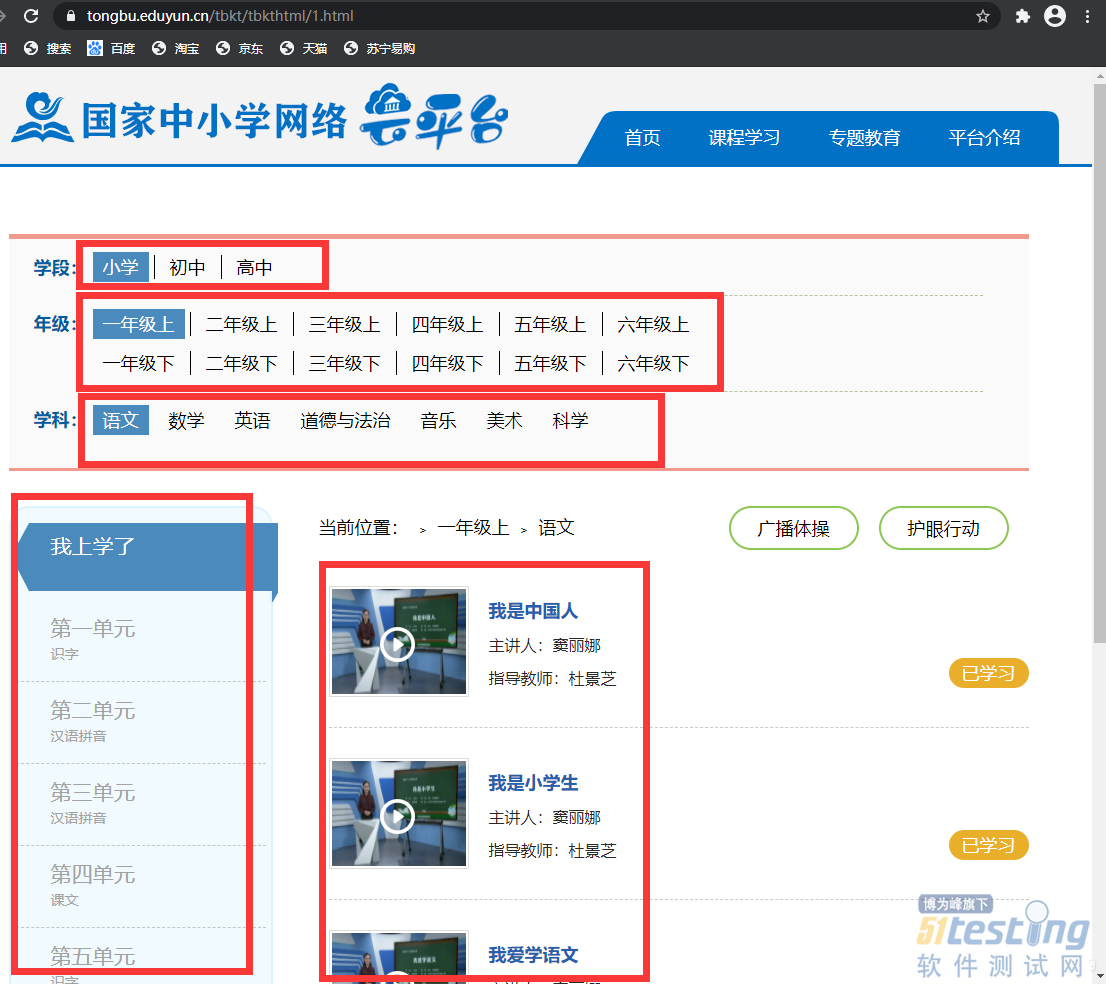
| def fibonacci(): # 学段 wait.until(presence_of_element_located((By.ID, "xueduan"))) elements_xd = browser.find_element(By.ID, "xueduan").find_elements(By.TAG_NAME, "dd") for len_xd in range(len(elements_xd)): element_xd_a = browser.find_element(By.XPATH, "//dl[@id='xueduan']/dd[{}]".format(len_xd + 1)) element_xd_a_text = element_xd_a.text print(element_xd_a_text) element_xd_a.click() # 年级 wait.until(presence_of_element_located((By.ID, "nianjiDl"))) elements_nj = browser.find_elements(By.XPATH, "//dl[@id='nianjiDl']/dd[@value]") for len_nj in range(len(elements_nj)): element_nj_a = browser.find_element(By.XPATH, "//dl[@id='nianjiDl']/dd[@value][{}]".format(len_nj + 1)) element_nj_a_text = element_nj_a.text print(element_nj_a_text) element_nj_a.click() # 学科 wait.until(presence_of_element_located((By.ID, "xuekeDl"))) elements_xk = browser.find_elements(By.XPATH, "//dl[@id='xuekeDl']/dd") for len_xk in range(len(elements_xk)): element_xk_a = browser.find_element(By.XPATH, "//dl[@id='xuekeDl']/dd[{}]".format(len_xk + 1)) element_xk_a_text = element_xk_a.text print(element_xk_a_text) element_xk_a.click() # 单元 wait.until(presence_of_element_located((By.ID, "UlDzfw"))) elements_nl = browser.find_elements(By.XPATH, "//ul[@id='UlDzfw']/li") for len_nl in range(len(elements_nl)): element_nl_li = browser.find_element(By.XPATH, "//ul[@id='UlDzfw']/li[{}]".format(len_nl + 1)) element_nl_li_a = element_nl_li.find_element(By.XPATH, "h3/a") element_nl_li_span = element_nl_li.find_element(By.XPATH, "h3/a/span") element_nl_li_a_text = element_nl_li_a.text print(element_nl_li_a_text) print("##{}".format(element_nl_li_span.text)) element_nl_li_a.click() # 视频列表 wait.until(presence_of_element_located((By.ID, "casel"))) elements_casel = browser.find_elements(By.XPATH, "//div[@id='casel']/dl") for len_casel in range(len(elements_casel)): element_casel_li_a = browser.find_element(By.XPATH, "//div[@id='casel']/dl[{}]/dd/h4/a".format( len_casel + 1)) element_casel_li_a_text = element_casel_li_a.text print(element_casel_li_a_text) # 视频地址 browser.get(element_casel_li_a.get_attribute("href")) # 具体视频连接在script里面,使用正则表达式获取连接 _script = browser.find_element_by_xpath("//div[@class='ShiPin_C']/script[2]").get_attribute( "textContent") # 获取m3u8中的下载连接 searchObj = re.search(r'file:\s*"(.*)?",', _script, re.M | re.I) browser.back() yield element_xd_a_text, element_nj_a_text, element_xk_a_text, element_nl_li_a_text, element_casel_li_a_text, searchObj.group( 1) |

| list = fibonacci() l1 = next(list) print(l1) ffmpeg_cmd = 'D:\\ffmpeg-n4.3.1\\bin\\ffmpeg.exe -referer "http://tongbu.eduyun.cn/" -i "{}" -c copy -bsf:a aac_adtstoasc "{}".mp4'.format( l1[5], l1[4]) print(ffmpeg_cmd) child = subprocess.Popen(ffmpeg_cmd, cwd=os.getcwd() + "\\", shell=True) child.wait() l1 = next(list) print(l1) ffmpeg_cmd = 'D:\\ffmpeg-n4.3.1\\bin\\ffmpeg.exe -referer "http://tongbu.eduyun.cn/" -i "{}" -c copy -bsf:a aac_adtstoasc "{}".mp4'.format( l1[5], l1[4]) print(ffmpeg_cmd) child = subprocess.Popen(ffmpeg_cmd, cwd=os.getcwd() + "\\", shell=True) child.wait() browser.quit() |
| 欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/) | Powered by Discuz! X3.2 |