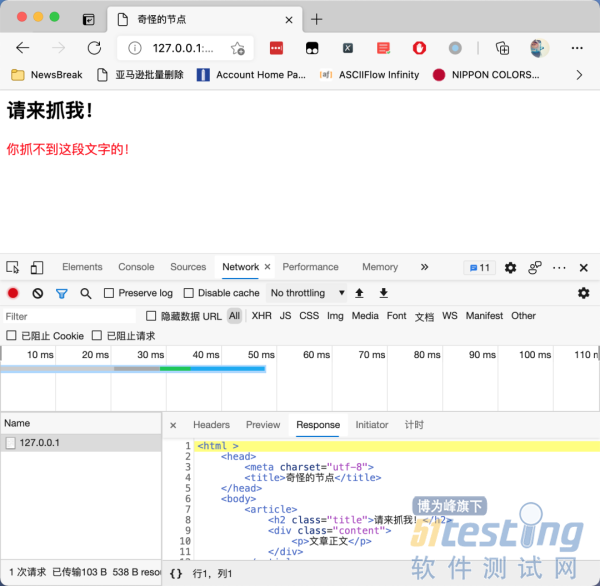



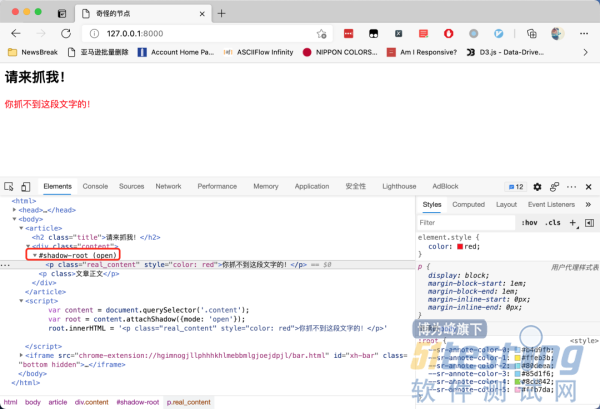
| var content = document.querySelector('.content'); var root = content.attachShadow({mode: 'open'}); root.innerHTML = '<p class="real_content" style="color: red">你抓不到这段文字的!</p>' |
| shadow = driver.execute_script('return document.querySelector(".content").shadowRoot') content = shadow.find_element_by_class_name('real_content') print(content.text) |

| 欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/) | Powered by Discuz! X3.2 |