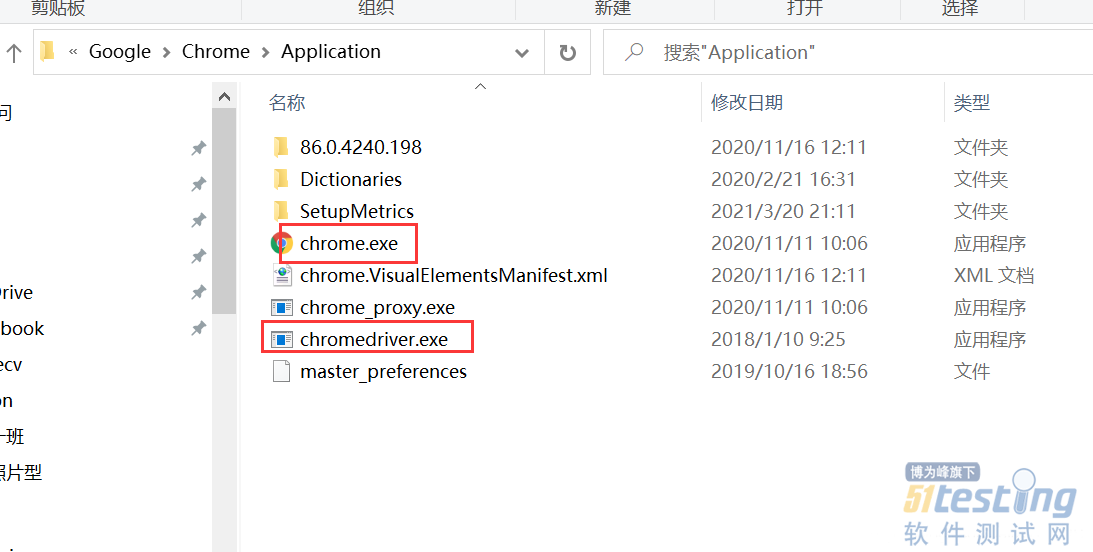
| pip install Selenium |
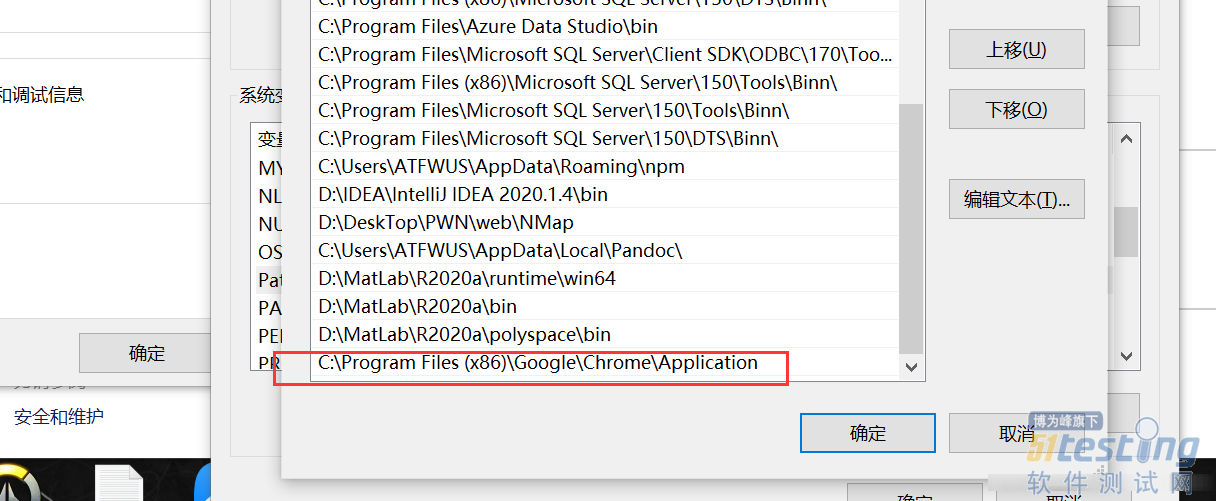
| from selenium import webdriver driver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe") |


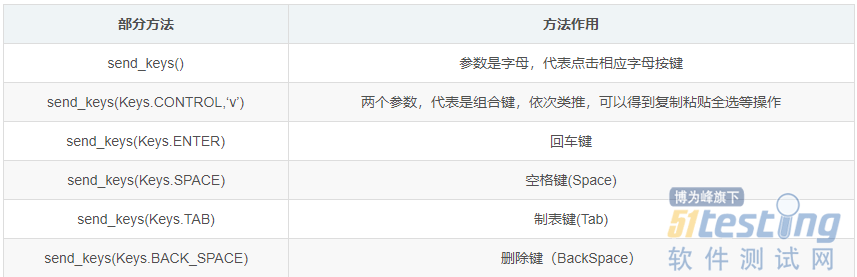
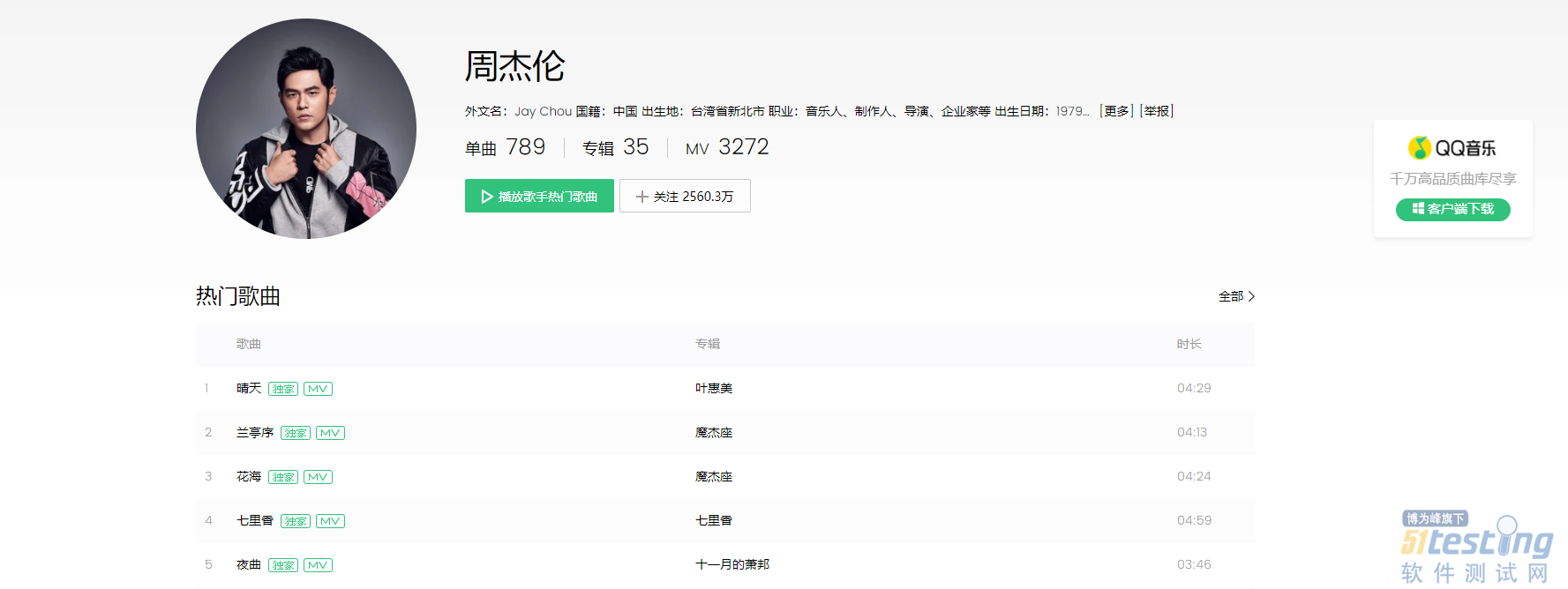
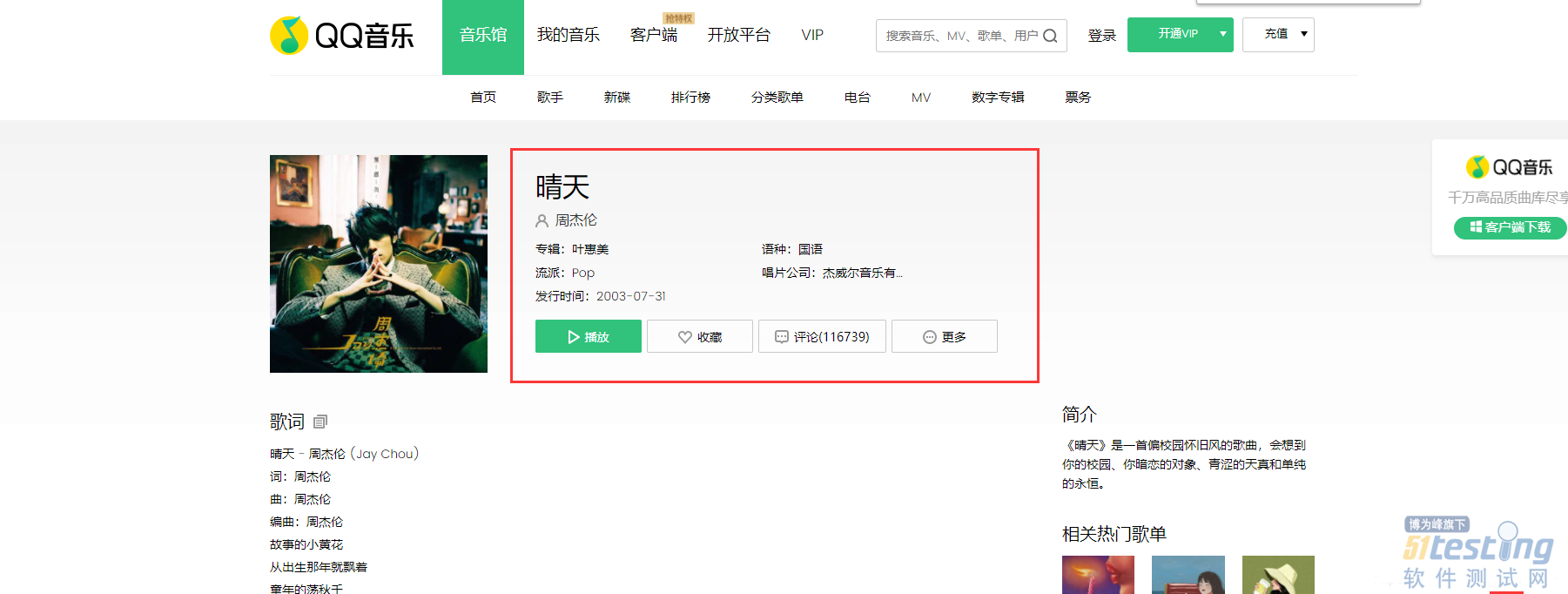



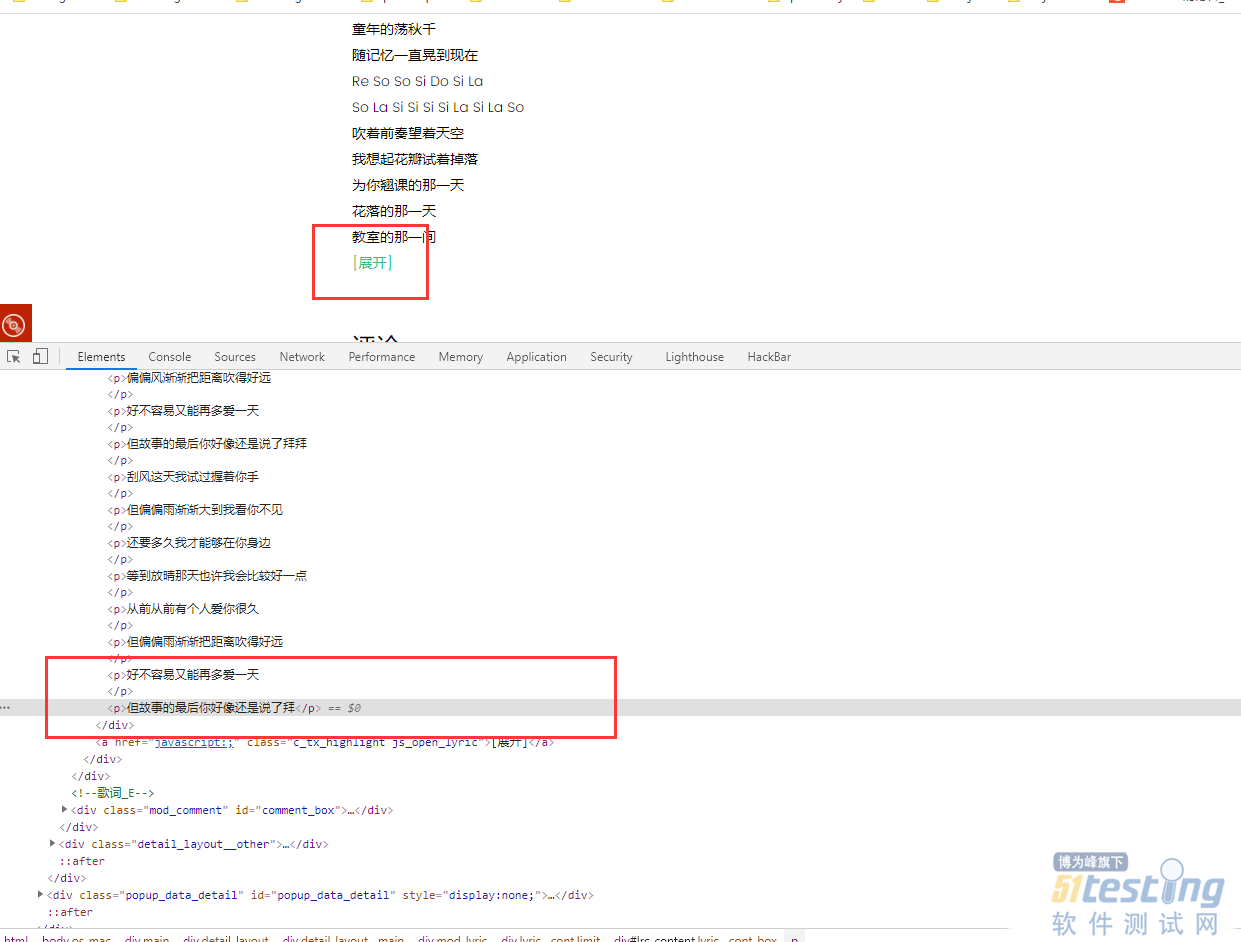

| from selenium import webdriver import csv from time import sleep import time # # Author : ATFWUS # Date : 2021-03-21 20:00 # Version : 1.0 # 爬取某个最热门五首歌曲的基本信息,歌词,前五百条热门评论 # 此代码仅供交流学习使用 # #1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口 driver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe") #2.打开QQ音乐 -周杰伦页面 driver.get("https://y.qq.com/n/yqq/singer/001t94rh4OpQn0.html") #3.配置 csv_file = open('songs1.csv','w',newline='',encoding='utf-8') writer = csv.writer(csv_file) start = time.time() # 取前5首歌曲 song_numer=5 song_url_list=[] song_resourses=[] songlist__item=driver.find_elements_by_class_name("songlist__item") # 获取所有歌曲url for song in songlist__item: song__url=song.find_element_by_class_name("js_song").get_attribute("href") song_url_list.append(song__url) song_numer-=1 if(song_numer==0): break # print(song_url_list) print("已获取当前歌手热门歌曲列表前五首的url") print() # 获取一首歌曲所需要的信息 def getSongResourse(url): song_resourse={} driver.get(url) # 这个1.8秒用于等待页面所有异步请求的完成 sleep(1.8) # 获取歌曲名 song_name=driver.find_element_by_class_name("data__name_txt").text print("开始获取歌曲《"+song_name+"》的基本信息") # 获取流派,发行时间,评论数 song_liupai = driver.find_element_by_css_selector(".js_genre").text[3:] song_time = driver.find_element_by_css_selector(".js_public_time").text[5:] song_comment_num = driver.find_element_by_css_selector(".js_into_comment").text[3:-1] print("歌曲《" + song_name + "》基本信息获取完毕") print("开始获取歌曲《" + song_name + "》的歌词") # 点击展开歌词 driver.find_element_by_partial_link_text("[展开]").click() sleep(0.3) lyic="" # 获取拼接歌词 lyic_box=driver.find_element_by_id("lrc_content").find_elements_by_tag_name("p") for l in lyic_box: if l.text!="": lyic+=l.text+"\n" print("歌曲《" + song_name + "》的歌词获取完毕") print("开始获取歌曲《" + song_name + "》的第1-15条热门评论") # 获取500条评论 comments=[] # 点击加载更多29次,每次多出15条评论 for i in range(33): try: driver.find_element_by_partial_link_text("点击加载更多").click() except: break print("开始获取歌曲《" + song_name + "》的第"+str((i+1)*15+1)+"-"+str((i+2)*15)+"条热门评论") sleep(0.5) comments_list=driver.find_element_by_css_selector(".js_hot_list").find_elements_by_tag_name("li") for com in comments_list: content=com.find_element_by_css_selector(".js_hot_text").text content_time=com.find_element_by_css_selector(".comment__date").text zan_num=com.find_element_by_class_name("js_praise_num").text comment = {} comment.update({"评论内容":content}) comment.update({"评论时间":content_time}) comment.update({"评论点赞次数":zan_num}) comments.append(comment) print("歌曲《" + song_name + "》的前五百条热门评论获取完毕") print("歌曲《"+song_name+"》所有信息获取完毕") print() song_resourse.update({"歌曲名":song_name}) song_resourse.update({"流派":song_liupai}) song_resourse.update({"发行时间":song_time}) song_resourse.update({"评论数":song_comment_num}) song_resourse.update({"歌词":lyic}) song_resourse.update({"500条精彩评论":comments}) return song_resourse for song_page in song_url_list: song_resourses.append(getSongResourse(song_page)) print("正在写入CSV文件...") for i in song_resourses: writer.writerow([i["歌曲名"],i["流派"],i["发行时间"],i["评论数"],i["歌词"]]) for j in i["500条精彩评论"]: writer.writerow([j["评论内容"],j["评论时间"],j["评论点赞次数"]]) writer.writerow([]) csv_file.close() end = time.time() print("爬取完成,总耗时"+str(end-start)+"秒") |
| pip install pandas |
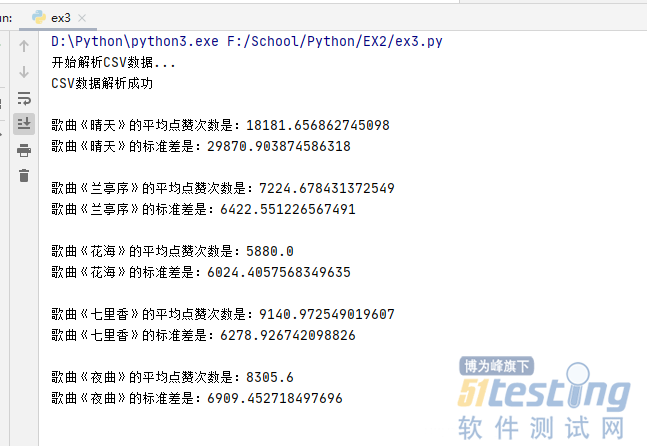
| import pandas as pd import csv # 这五个列表用于创建Series se=[] names=[] # 先读取CSV文件的内容至内存中 with open("songs1.csv",'r',encoding="utf8") as f: # 创建阅读器对象 reader = csv.reader(f) rows = [row for row in reader] index=0 print("开始解析CSV数据...") for i in range(5): s1=[] # 读取第一行信息 names.append(rows[index].__str__().split(',')[0][2:-1]) index+=1 # 读取五百条评论的点赞消息 for j in range(510): try: s1.append(int(rows[index].__str__().split(',')[2][2:-2])) index+=1 except: break se.append(s1) # 读取掉空行 index+=1 print("CSV数据解析成功\n") # 创建的5个series for i in range(5): series=pd.Series(se) print("歌曲《"+names+"》的平均点赞次数是:" + str(series.mean())) print("歌曲《" + names + "》的标准差是:" + str(series.std())) print() |

| 欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/) | Powered by Discuz! X3.2 |