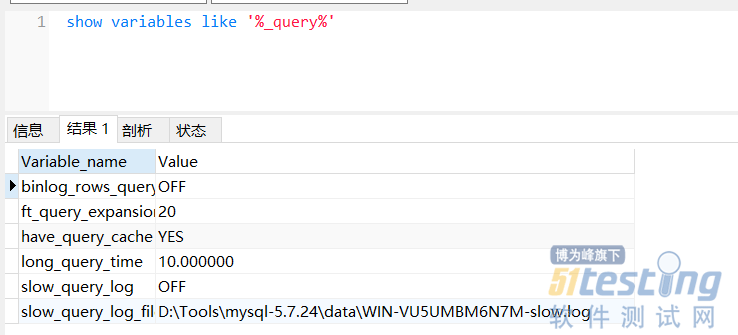
| set global slow_query_log=1; set global long_query_time=1; set global slow_query_log_file='mysql-slow.log' |
| slow_query_log = 'ON' slow_query_log_file = D:/Tools/mysql-8.0.16/slow.log long_query_time = 1 log-queries-not-using-indexes |
| ./pt-query-digest slow2.log >> slow2.txt |
| # Query 9: 0.00 QPS, 0.00x concurrency, ID 0xF914D8CC2938CE6CAA13F8E57DF04B2F at byte 499246 # This item is included in the report because it matches --limit.# Scores: V/M = 0.22 # Time range: 2019-07-08T03:56:12 to 2019-07-12T00:46:28 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= =======# Count 8 69 # Exec time 1 147s 1s 3s 2s 3s 685ms 2s # Lock time 0 140ms 2ms 22ms 2ms 3ms 2ms 2ms # Rows sent 0 0 0 0 0 0 0 0 # Rows examine 0 23.96M 225.33k 482.77k 355.65k 462.39k 81.66k 345.04k # Query size 2 17.72k 263 263 263 263 0 263 # String:# Databases xxxx# Hosts xx.xxx.xxx.xxx# Users root# Query_time distribution# 1us # 10us # 100us # 1ms # 10ms # 100ms # 1s ################################################################ # 10s+ # Tables# SHOW TABLE STATUS FROM `xxxx` LIKE 'xxxxx_track_exec_channel'\G # SHOW CREATE TABLE `xxxx`.`xxxxxxxx_exec_channel`\G # SHOW TABLE STATUS FROM `xxx` LIKE 'xxxxx_TRACK_ASSIGN'\G # SHOW CREATE TABLE `xxxx`.`xxxxx_EFFECTIVE_TRACK_ASSIGN`\G # SHOW TABLE STATUS FROM `xxx` LIKE 'xxxx_task_exec'\G # SHOW CREATE TABLE `xxxx`.`xxxxx_task_exec`\G UPDATExxxxxx_effective_track_exec_channel a SET EXEC_CHANNEL_CODE=(SELECT GROUP_CONCAT(DISTINCT(channel_id)) FROM xxxxxx_EFFECTIVE_TRACK_ASSIGN WHERE status in (1,2,4) AND id IN (SELECT assgin_id FROM xxxxxx_task_exec WHERE task_id=a.task_id))\G |

| 欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/) | Powered by Discuz! X3.2 |