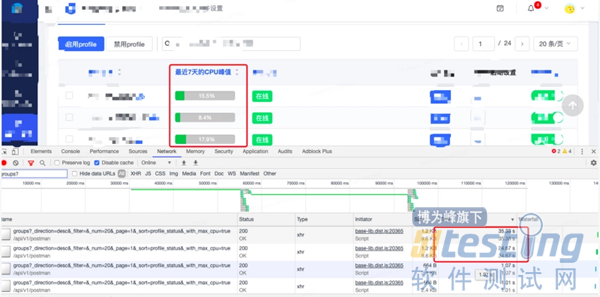
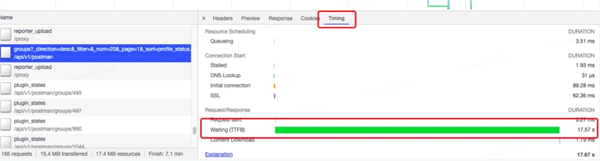

| def get_max_cpus(project_code, gids): """ """ ... # 再定义一个获取 cpu 的函数 def get_max_cpu(project_setting, gid, token, headers): group_with_machines = utils.get_groups(...) hostnames = get_info_from_machines_info(...) res = fetchers.MonitorAPIFetcher.get(...) vals = [ round(100 - val, 4) for ts, val in res['series'][0]['data'] if not utils.is_nan(val) ] maxmax_val = max(vals) if vals else float('nan') max_cpus[gid] = max_val # 启动线程批量请求 for gid in gids: t = Thread(target=get_max_cpu, args=(...)) threads.append(t) t.start() # 回收线程 for t in threads: t.join() return max_cpus |


| def get_group_profile_settings(project_code, gids): # 获取 Mysql ORM 操作对象 ProfileSetting = unpurview(sandman.endpoint_class('profile_settings')) session = get_postman_session() profile_settings = {} for gid in gids: compound_name = project_code + ':' + gid result = session.query(ProfileSetting).filter( ProfileSetting.name == compound_name ).first() if result: resultresult = result.as_dict() tag_indexes = result.get('tag_indexes') profile_settings[gid] = { 'tag_indexes': tag_indexes, 'interval': result['interval'], 'status': result['status'], 'profile_machines': result['profile_machines'], 'thread_settings': result['thread_settings'] } ...(省略) return profile_settings |
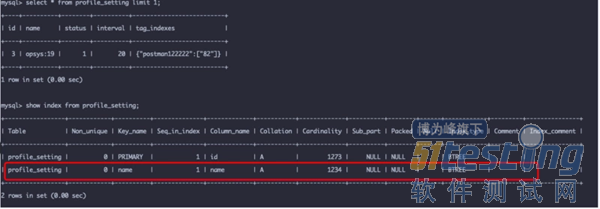
| for gid in gids: ... |

| def get_group_profile_settings(project_code, gids): # 获取 Mysql ORM 操作对象 ProfileSetting = unpurview(sandman.endpoint_class('profile_settings')) session = get_postman_session() profile_settings = {} for gid in gids: compound_name = project_code + ':' + gid result = session.query(ProfileSetting).filter( ProfileSetting.name == compound_name ).first() ... |
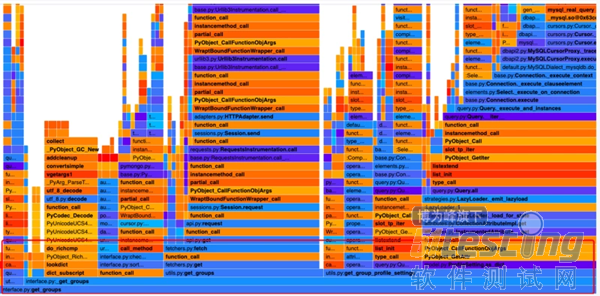
| 1. 数据库的查询没有批量查询; 2. ORM 的对象太多重复的生成,导致性能损耗; 3. 属性读取后没有复用,导致在遍历次数较大的循环体内频繁 getAttr,成本被放大; |
| def get_group_profile_settings(project_code, gids): # 获取 Mysql ORM 操作对象 ProfileSetting = unpurview(sandman.endpoint_class('profile_settings')) session = get_postman_session() # 批量查询 并将 filter 提到循环之外 query_results = query_instance.filter( ProfileSetting.name.in_(project_code + ':' + gid for gid in gids) ).all() # 对全部的查询结果再单条处理 profile_settings = {} for result in query_results: if not result: continue resultresult = result.as_dict() gid = result['name'].split(':')[1] tag_indexes = result.get('tag_indexes') profile_settings[gid] = { 'tag_indexes': tag_indexes, 'interval': result['interval'], 'status': result['status'], 'profile_machines': result['profile_machines'], 'thread_settings': result['thread_settings'] } ...(省略) return profile_settings |

| 欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/) | Powered by Discuz! X3.2 |