51Testing软件测试论坛
标题:
爬虫Scrapy框架的setting.py文件详解
[打印本页]
作者:
悠悠小仙仙
时间:
2019-6-11 11:58
标题:
爬虫Scrapy框架的setting.py文件详解
# -*- coding: utf-8 -*-
# Scrapy settings for demo1 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
#
http://doc.scrapy.org/en/latest/topics/settings.html
#
http://scrapy.readthedocs.org/en ... der-middleware.html
#
http://scrapy.readthedocs.org/en ... der-middleware.html
BOT_NAME = 'demo1' #Scrapy项目的名字,这将用来构造默认 User-Agent,同时也用来log,当您使用 startproject 命令创建项目时其也被自动赋值。
SPIDER_MODULES = ['demo1.spiders'] #Scrapy搜索spider的模块列表 默认: [xxx.spiders]
NEWSPIDER_MODULE = 'demo1.spiders' #使用 genspider 命令创建新spider的模块。默认: 'xxx.spiders'
#爬取的默认User-Agent,除非被覆盖
#USER_AGENT = 'demo1 (+
http://www.yourdomain.com
)'
#如果启用,Scrapy将会采用 robots.txt策略
ROBOTSTXT_OBEY = True
#Scrapy downloader 并发请求(concurrent requests)的最大值,默认: 16
#CONCURRENT_REQUESTS = 32
#为同一网站的请求配置延迟(默认值:0)
# See
http://scrapy.readthedocs.org/en ... html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3 下载器在下载同一个网站下一个页面前需要等待的时间,该选项可以用来限制爬取速度,减轻服务器压力。同时也支持小数:0.25 以秒为单位
#下载延迟设置只有一个有效
#CONCURRENT_REQUESTS_PER_DOMAIN = 16 对单个网站进行并发请求的最大值。
#CONCURRENT_REQUESTS_PER_IP = 16 对单个IP进行并发请求的最大值。如果非0,则忽略 CONCURRENT_REQUESTS_PER_DOMAIN 设定,使用该设定。 也就是说,并发限制将针对IP,而不是网站。该设定也影响 DOWNLOAD_DELAY: 如果 CONCURRENT_REQUESTS_PER_IP 非0,下载延迟应用在IP而不是网站上。
#禁用Cookie(默认情况下启用)
#COOKIES_ENABLED = False
#禁用Telnet控制台(默认启用)
#TELNETCONSOLE_ENABLED = False
#覆盖默认请求标头:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
#启用或禁用蜘蛛中间件
# See
http://scrapy.readthedocs.org/en ... der-middleware.html
#SPIDER_MIDDLEWARES = {
# 'demo1.middlewares.Demo1SpiderMiddleware': 543,
#}
#启用或禁用下载器中间件
# See
http://scrapy.readthedocs.org/en ... der-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'demo1.middlewares.MyCustomDownloaderMiddleware': 543,
#}
#启用或禁用扩展程序
# See
http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
#配置项目管道
# See
http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'demo1.pipelines.Demo1Pipeline': 300,
#}
#启用和配置AutoThrottle扩展(默认情况下禁用)
# See
http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
#初始下载延迟
#AUTOTHROTTLE_START_DELAY = 5
#在高延迟的情况下设置的最大下载延迟
#AUTOTHROTTLE_MAX_DELAY = 60
#Scrapy请求的平均数量应该并行发送每个远程服务器
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
#启用显示所收到的每个响应的调节统计信息:
#AUTOTHROTTLE_DEBUG = False
#启用和配置HTTP缓存(默认情况下禁用)
# See
http://scrapy.readthedocs.org/en ... middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
解释几个参数:
ROBOTSTXT_OBEY = True -----------是否遵守robots.txt
CONCURRENT_REQUESTS = 16 -----------开启线程数量,默认16
AUTOTHROTTLE_START_DELAY = 3 -----------开始下载时限速并并延迟时间
AUTOTHROTTLE_MAX_DELAY = 60 -----------高并发请求时最大延迟时间
最底下的几个:是否启用在本地缓存,如果开启会优先读取本地缓存,从而加快爬取速度,视情况而定
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR ='httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE ='scrapy.extensions.httpcache.FilesystemCacheStorage'
以上几个可以视项目需要开启,但是有两个参数最好每次都开启,而每次都是项目文件手动开启不免有些麻烦,最好是项目创建后就自动开启
#DEFAULT_REQUEST_HEADERS = {
#'接受':'text / html,application / xhtml + xml,application / xml; q = 0.9,* / *; q = 0.8',
#'Accept-Language':'en',
#}
这个是浏览器请求头,很多网站都会检查客户端的头,比如豆瓣就是每一个请求都检查头的user_agent,否则只会返回403,可以开启
#USER_AGENT ='Chirco(+ http://www.yourdomain.com)'
这个是至关重要的,大部分服务器在请求快了会首先检查User_Agent,而scrapy默认的浏览器头是scrapy1.1我们需要开启并且修改成浏览器头,如:Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.1(KHTML,和Gecko一样)Chrome / 22.0.1207.1 Safari / 537.1
但是最好是这个USER-AGENT会随机自动更换最好了。
下面的代码可以从预先定义的用户代理的列表中随机选择一个来采集不同的页面
在settings.py中添加以下代码
DOWNLOADER_MIDDLEWARES = {
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
'randoms.rotate_useragent.RotateUserAgentMiddleware' :400
}
rotate_useragent的代码为:
# -*- coding: utf-8 -*-
import random
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
#这句话用于随机选择user-agent
ua = random.choice(self.user_agent_list)
if ua:
print('User-Agent:'+ua)
request.headers.setdefault('User-Agent', ua)
#the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape
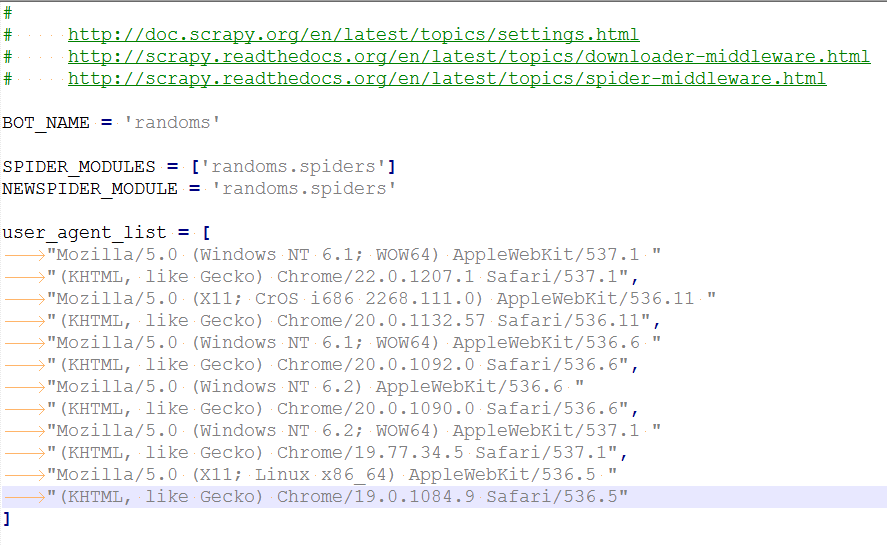
user_agent_list = [\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
运行爬虫可以看到信息:
2017-04-16 00:07:40 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
User-Agent:Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3
2017-04-16 00:07:40 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET
http://www.jianshu.com/robots.txt>
from <GET
http://jianshu.com/robots.txt>
User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1
2017-04-16 00:07:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET
http://www.jianshu.com/robots.txt>
(referer: None)
User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24
2017-04-16 00:07:41 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET
http://www.jianshu.com/>
from <GET
http://jianshu.com/>
User-Agent:Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3
也可以把user_agent_list放到设置文件中去:
在rotate_useragent文件中加入一行代码
from randoms.settings import user_agent_list
运行效果如下:
作者:
Miss_love
时间:
2020-12-30 16:02
支持
欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/)
Powered by Discuz! X3.2