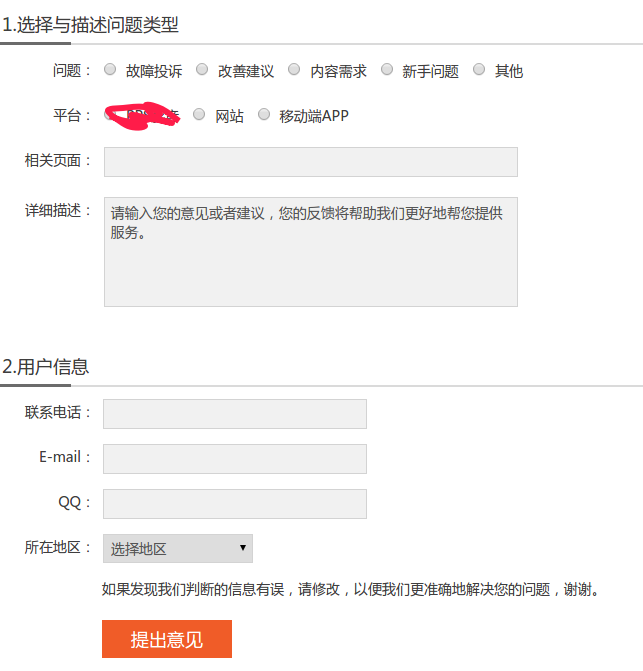

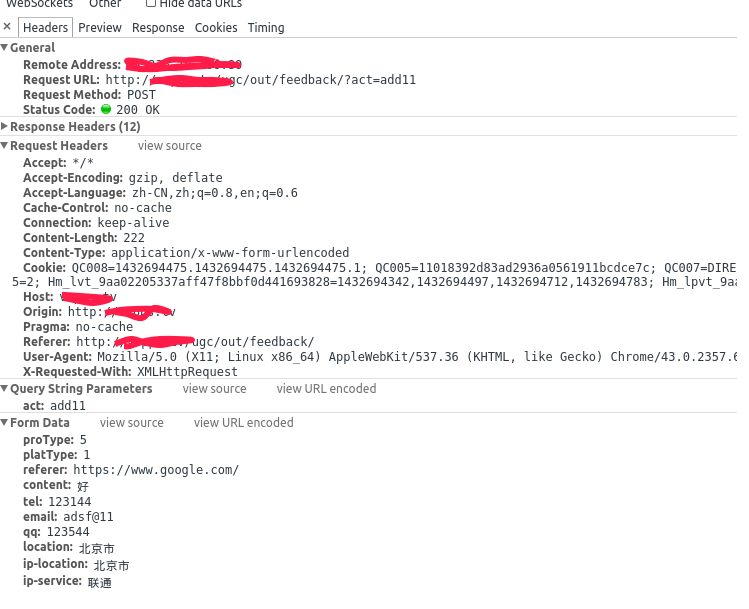
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。
| 欢迎光临 51Testing软件测试论坛 (http://bbs.51testing.com/) | Powered by Discuz! X3.2 |